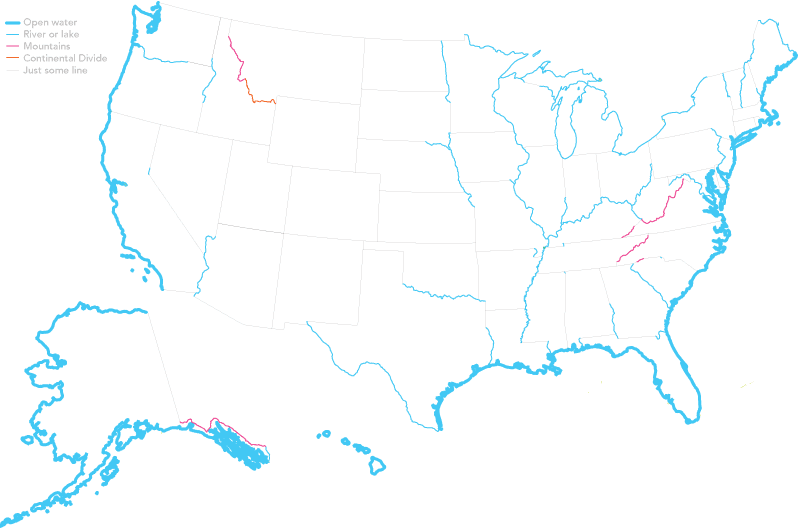
This map by Dorothy Gambrell looks at US state borders formed by natural, well, borders. None of those lines drawn by a bunch of old men wearing wigs. What I really like is how those artificial borders are drawn as a thin grey line and labelled as “just some line”.
Guantanamo Bay and the US military prison there almost always spark a debate. For some months now, prisoners have been staging a hunger strike. Increasingly, however, the strike is garnering attention not for itself, but for the US military’s treatment of the prisoners in force feeding them. The National Post looked at just how this is being done in this infographic. Pay particular attention to the illustration of the tube, which is drawn to actual size.
Force feeding Guantanamo’s striking prisoners
Credit for the piece goes to Andrew Barr, Mike Faille, and Richard Johnson.
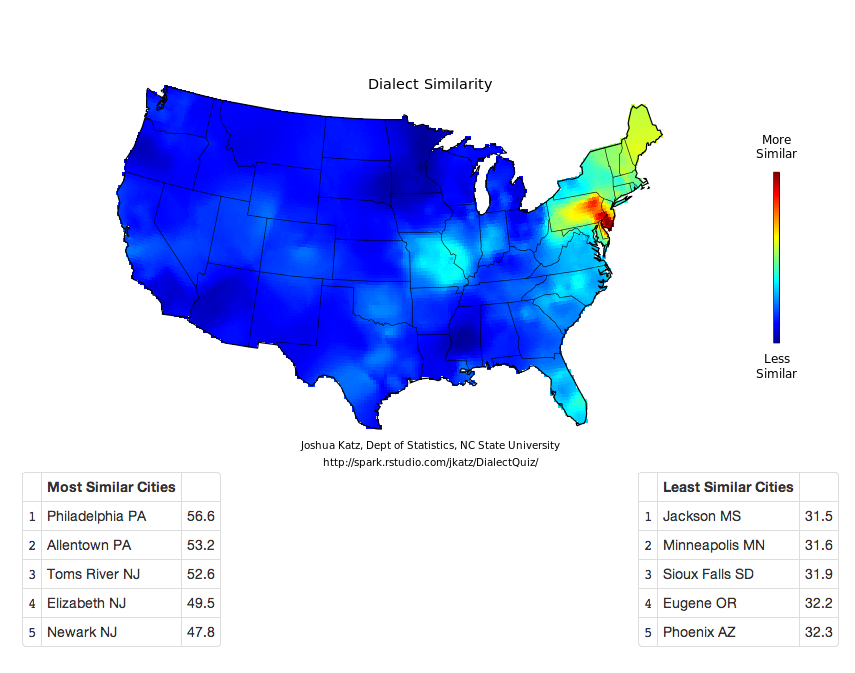
Joshua Katz from North Carolina State University has created an interactive version of the dialect survey maps first perhaps popularised several years ago. Katz has also created an interactive map that looks at a city’s dialect and maps its areas of similarity and difference. An interesting extension of the original survey data, however, is the ability to take the survey yourself and see where your dialect fits. There are two versions, a 25-question survey and a 140-question survey.
The screenshot below is my result from the 25-question version. And it fits me fairly well since I spent most of my years in the suburbs of Philadelphia but every summer in South Jersey (and quite a bit of time in Allentown). Click the map to take the quiz for yourself. Feel free to reply and share your results.
Clearly I am Philadelphia raised
From the technical side, for those wondering, this is a piece that is done in Shiny, the interactive version of R.
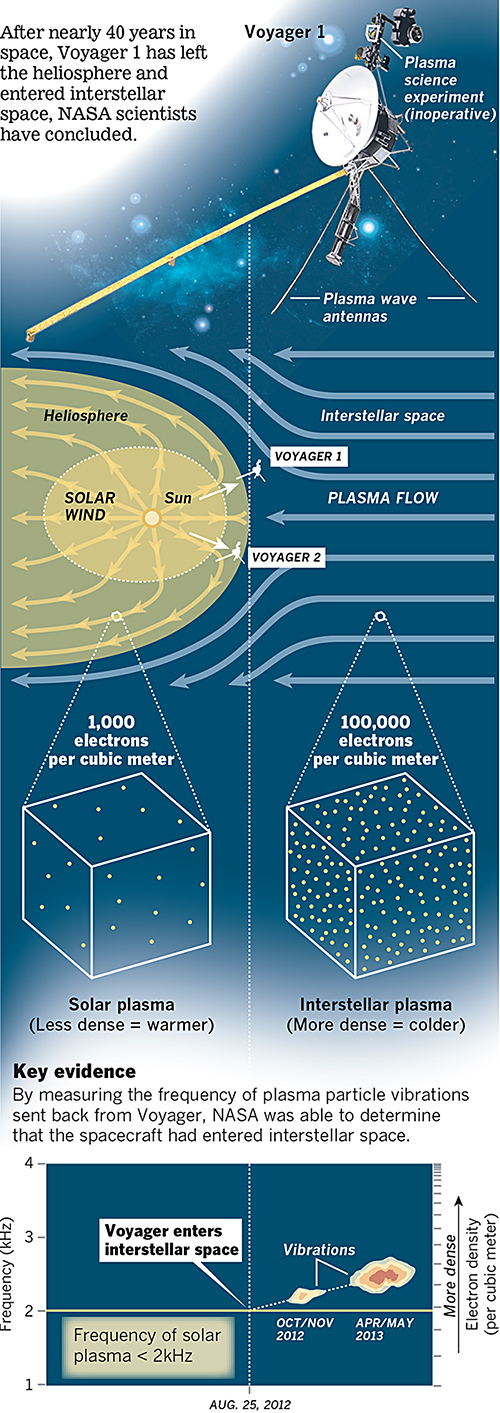
Last week NASA announced that last year, Voyager 1 left the Solar System about 25 August 2012. A lot of the graphics that were published to support that story chronicled the distance travelled by that probe. However, this excellent graphic by the Los Angeles Times instead looks at how NASA determined through the data returned that Voyager had left the Solar System.
Voyager 1 departs the Solar System
The piece does a really good job of setting up the story in illustrating the instrument packaged used to collect the data. Moving down the piece, it shows locations and the different environments and then how those environments differ in electron density. Lastly it looks at how NASA interpolated the date from the data collected. A really solid piece.
Credit for the piece goes to Monte Morin, Doug Stevens, and Anthony Pesce.
Normally this would be a Friday post. But, for those of you fellow Red Sox fans who happen to live near enough to Fenway to go catch a game, Wednesday night is Dollar Beard Night. This graphic by the Red Sox details the different types of beards worn by Red Sox players this year. It’s like the bunch of idiots of 2004.
The Red Sox beards
Wednesday night if you show up to Fenway with a beard, you can get a $1 ticket for Dollar Beard Night. Hence why posting this Friday would do you fellow Red Sox fans no good.
Today’s post comes via @dansidor and in fairness isn’t quite about a graphic, but rather how to obtain data for a graphic. Or not. I’m not really sure. To hell with it. It’s Friday. Have a weekend.
For those of you who read this blog in Chicago know very well that the Red Line, Chicago’s busiest subway line, is undergoing major construction as the transit authority rebuilds much of the line. But what exactly does that entail?
Earlier this year the Chicago Tribune looked at that and with a series of illustrations, explained the different steps of the process. This first section details the steps taken to rip up the rails.
Dismantling the existing rail lines
Credit for the piece goes to Jemal R. Brinson and Kyle Bentle.
Tuesday was election day in New York (among other places) where voters went to the polls for the mayoral primary (among other positions). For those living underneath what I can only presume was a very comfortable rock, this is the whole Anthony Weiner comeback election. Anyway, a bunch of different websites, most tied to the New York area, were covering the election results. So I wanted to share just a few.
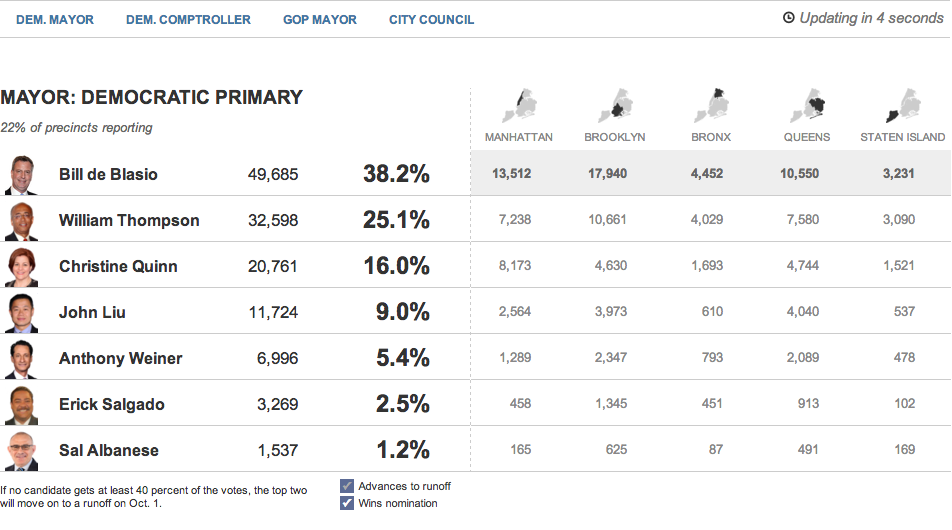
First we have the Huffington Post with the most straightforward presentation. Their table covers the main candidates and their results at a borough level and at a city-wide level.
The Huffington Post’s tabular results
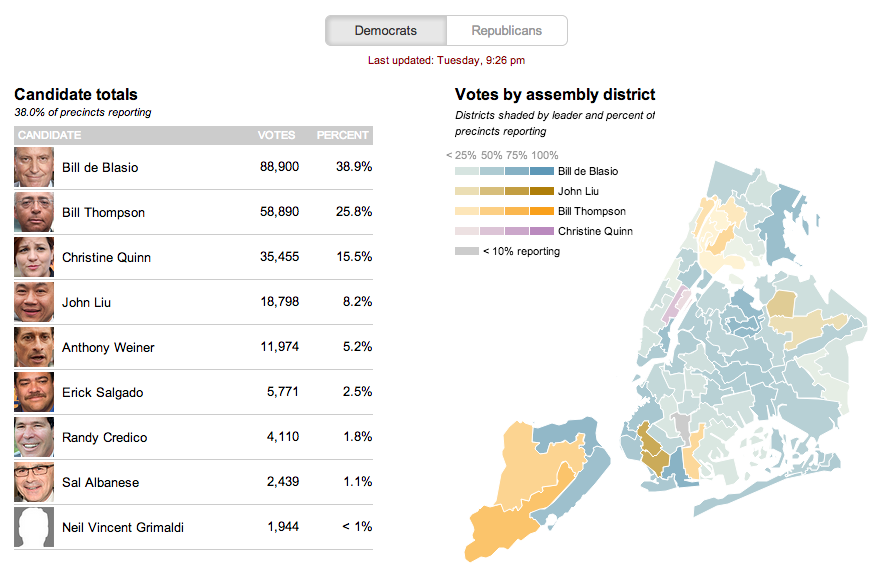
The second is from the Wall Street Journal. This uses a choropleth map with different colours assigned to a select few persons running—also the only ones with a real chance of winning. Tints of these colours in each district indicate how much of the district has voted.
The Wall Street Journal reports at the district level
From WNYC we have our third example—another choropleth where different colours represent different candidates. However, unlike the Wall Street Journal, the colours here have only one tint. And instead of showing assembly districts, WNYC provides a further level of data and looks at precinct results. It does not represent the amount of the precinct that has voted, but rather whether the candidate is winning by a plurality or by a majority. Beneath the legend a second charting element is used; this details the breakdown of the vote by districts as separated into racial majority. This is an interesting addition that hints at filtering results by related data.
WNYC looks at who’s winning and how
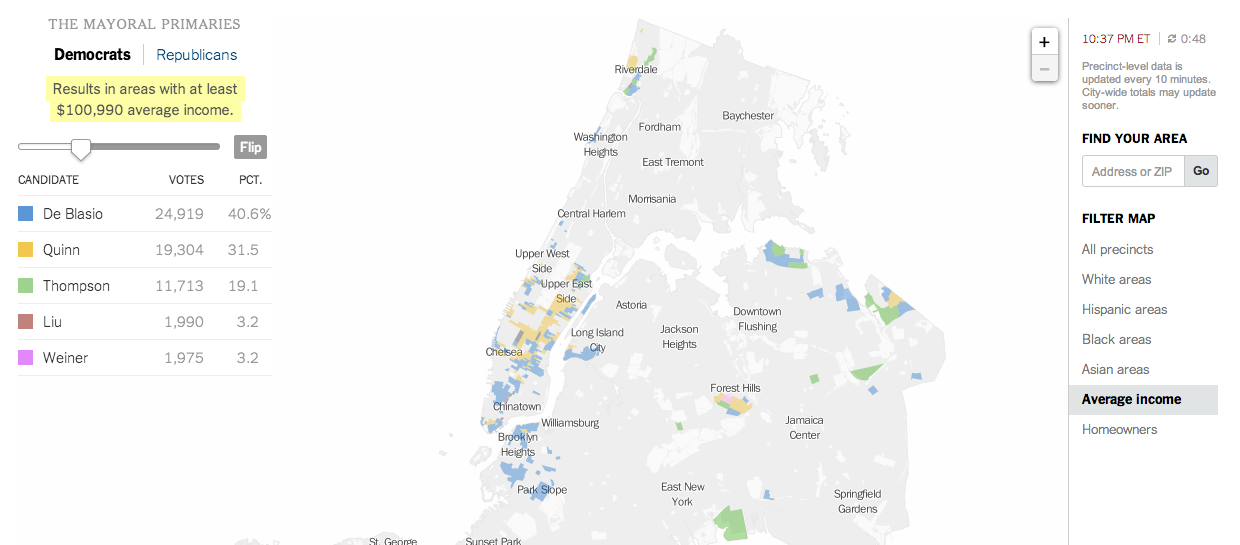
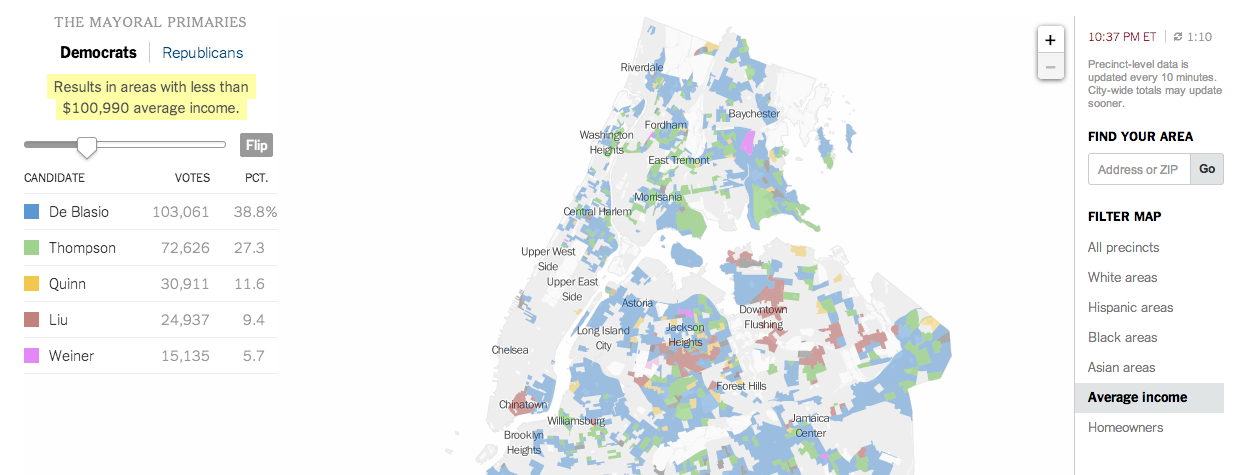
And that filtering brings us to the New York Times’ piece, which does offer filtering. It highlights districts on its maps—also precinct-level and not district aggregates—based upon the metric and the specific properties of said metric. In this case, I have chosen income. And the story of different voting patterns (at this particular point in the evening) based on income is quite clear. Look at Christine Quinn’s support.
Results from people earning more than $100kVotes from people earning less than $100k
Credit for these:
Huffington Post: Aaron Bycoffe, Jay Boice, Andrei Scheinkman, and Shane Shifflett
Wall Street Journal: the Wall Street Journal’s graphics team
WNYC: Steven Melendez, Louise Ma, Jenny Ye, Marine Boudeau, Schuyler Duveen, Elizabeth Zagroba, and John Keefe
New York Times: New York Times’ graphics department
…it’s an Aeroscraft! This interactive, diagrammatic infographic from the Los Angeles Times explains just how the aeroscraft is part zeppelin, part plane, and part chopper.
Internal frame of an aeroscraft
Credit for the piece goes to Raoul Ranoa and Anthony Pesce.
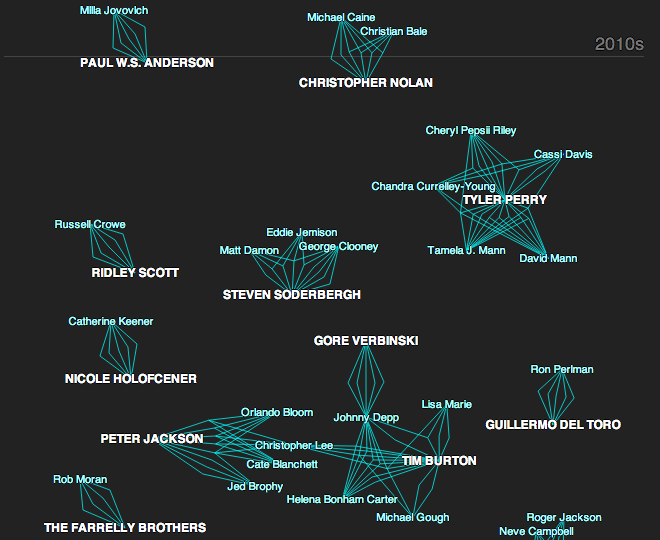
Of the acting and directing world over time. This interactive piece from the New York Times charts the networks between actors and directors. The networks on the right while examples and stories are located to the left. When you scroll to an example, the network to the right is highlighted in yellow. If you click a link, you are taken to the IMDb page for that particular film. A really nice piece.
Networks of actors and directors
Credit for the piece goes to Mike Bostock, Jennifer Daniel, Alicia DeSantis, and Nicolas Rapold.