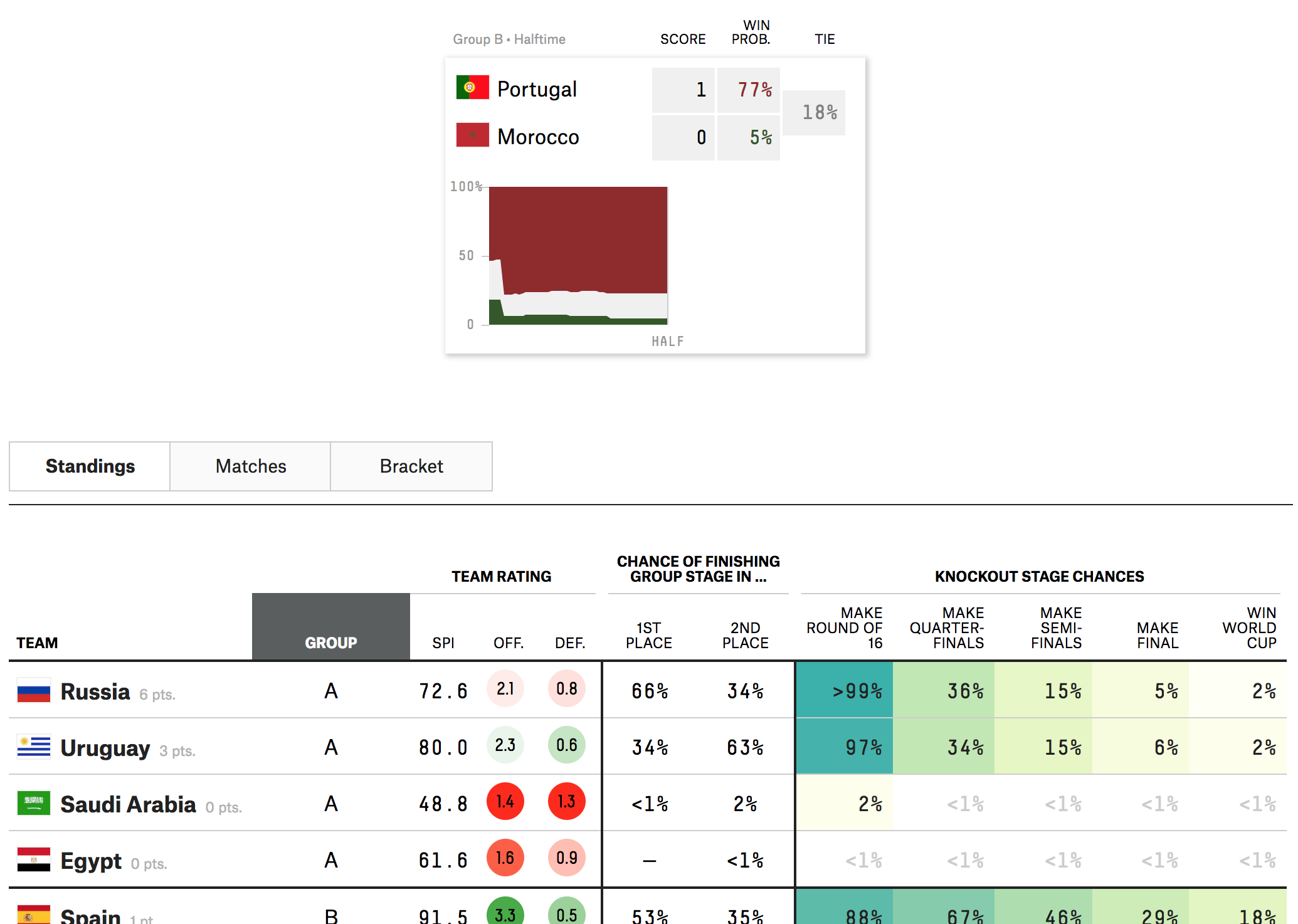
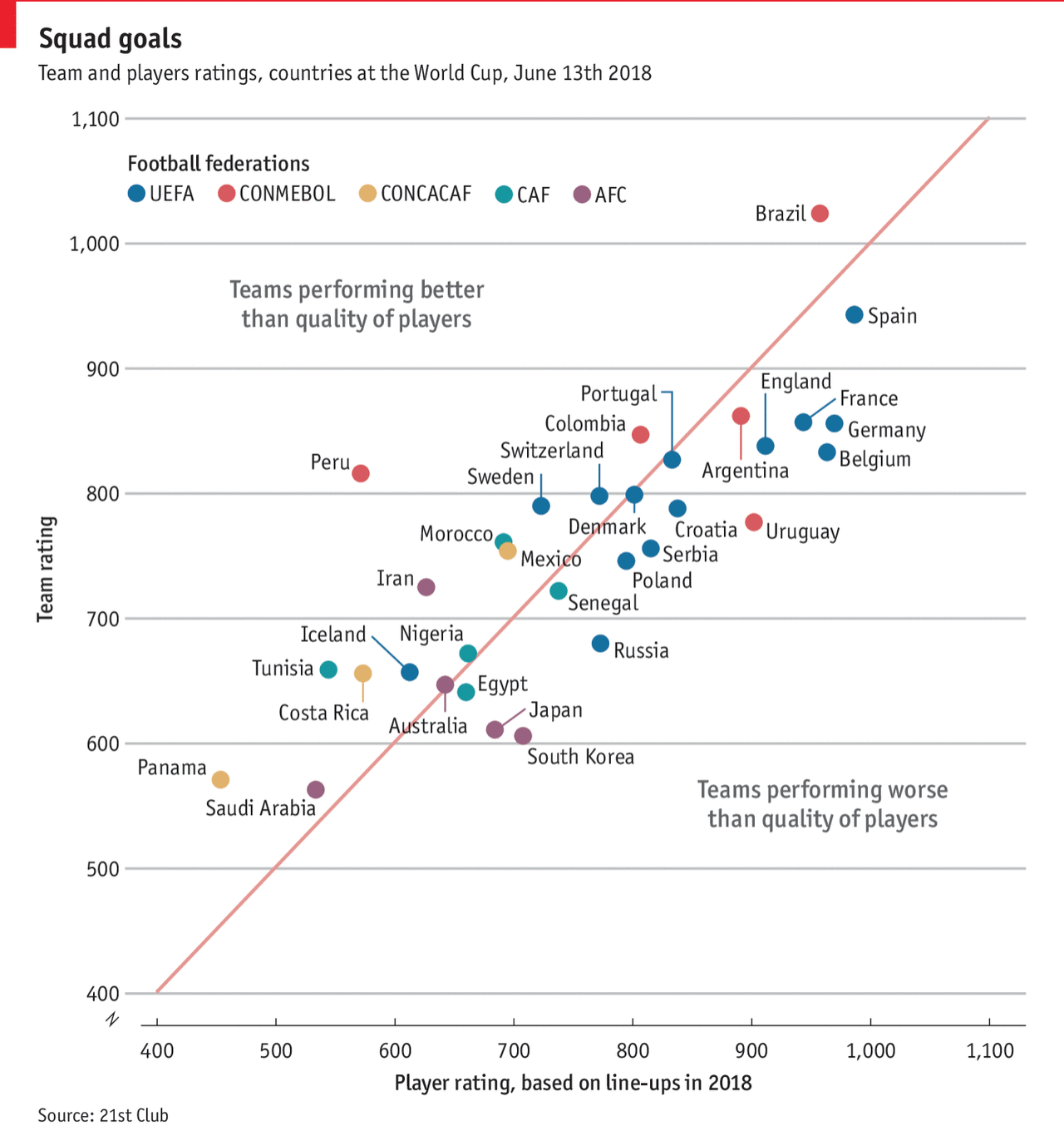
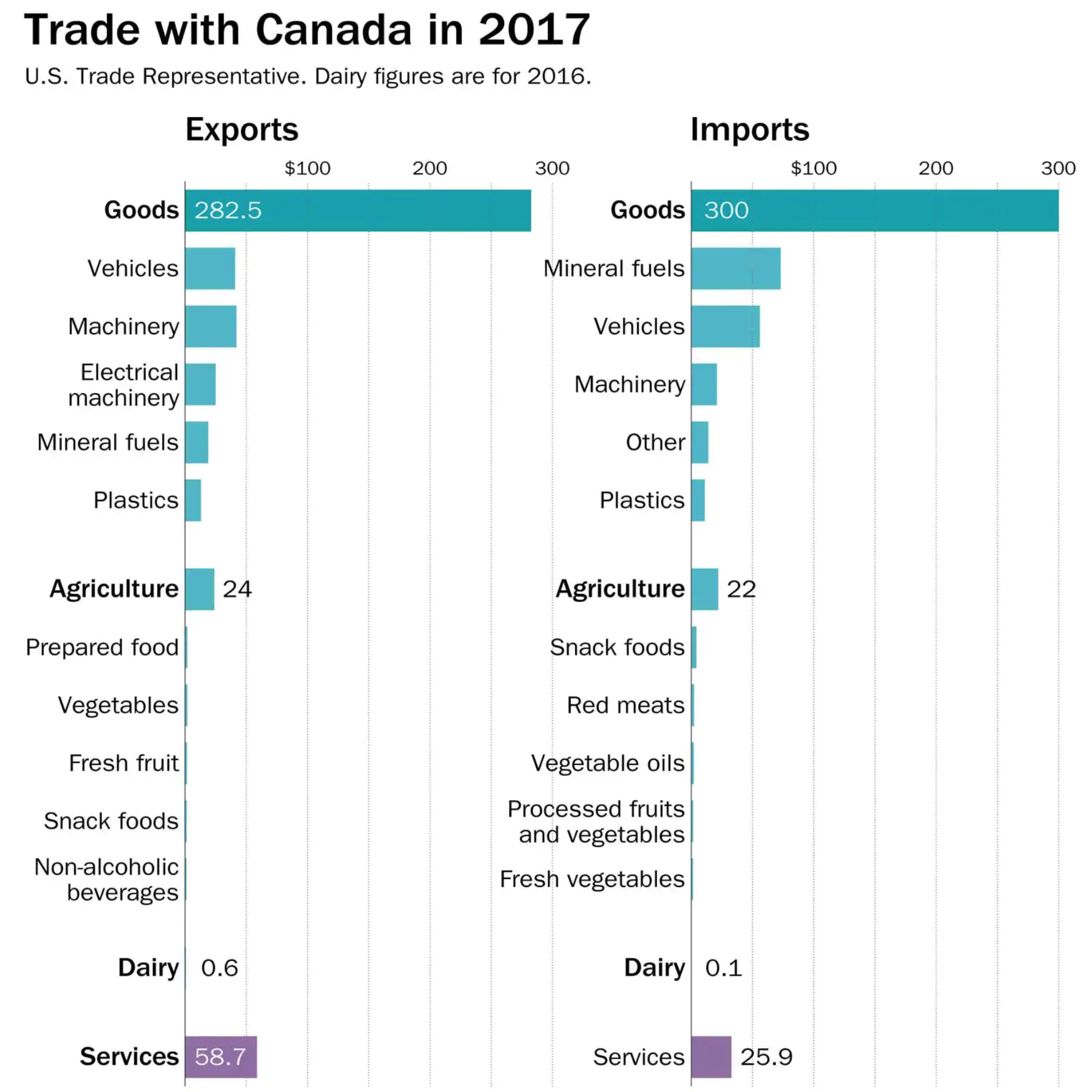
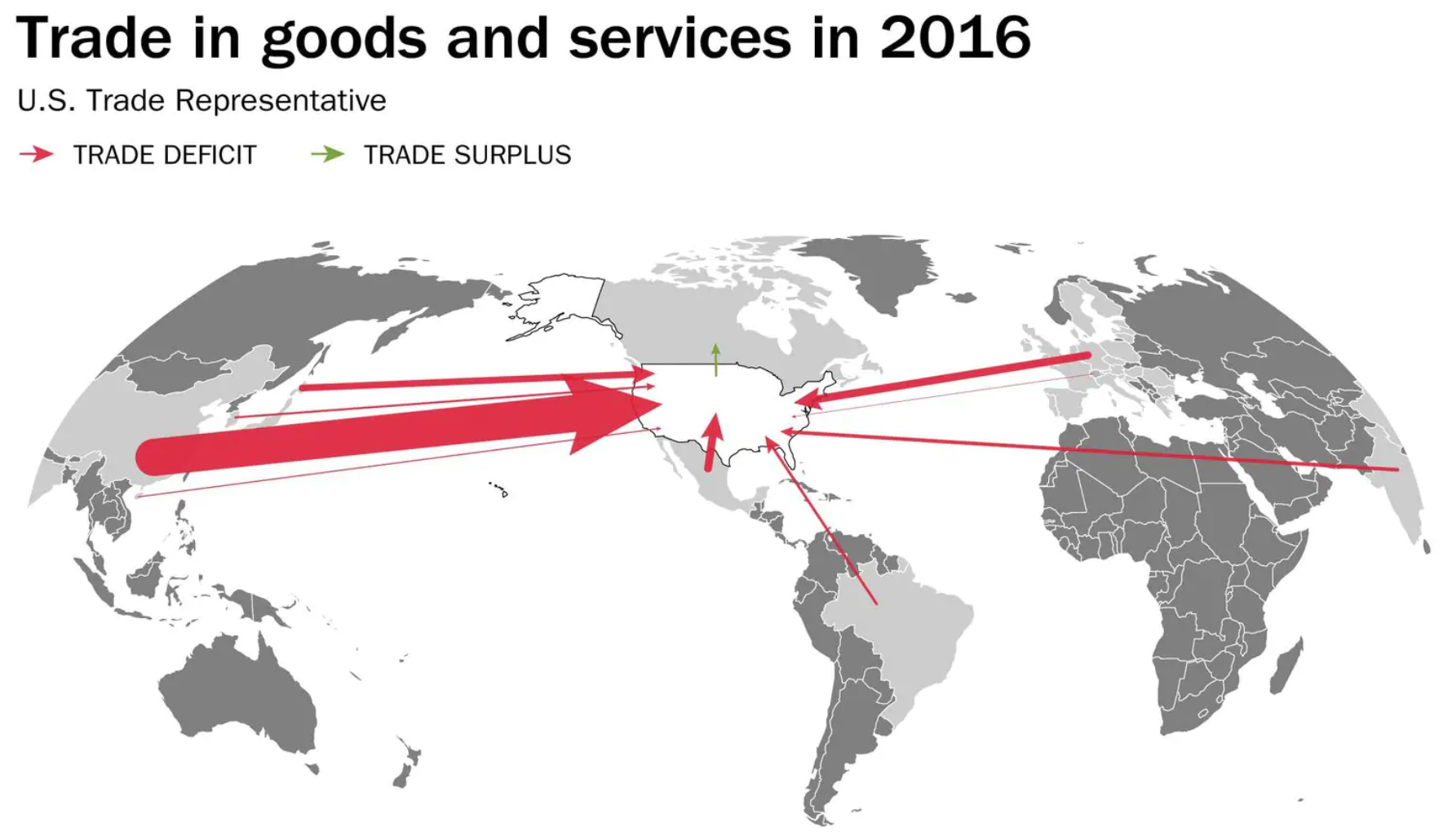
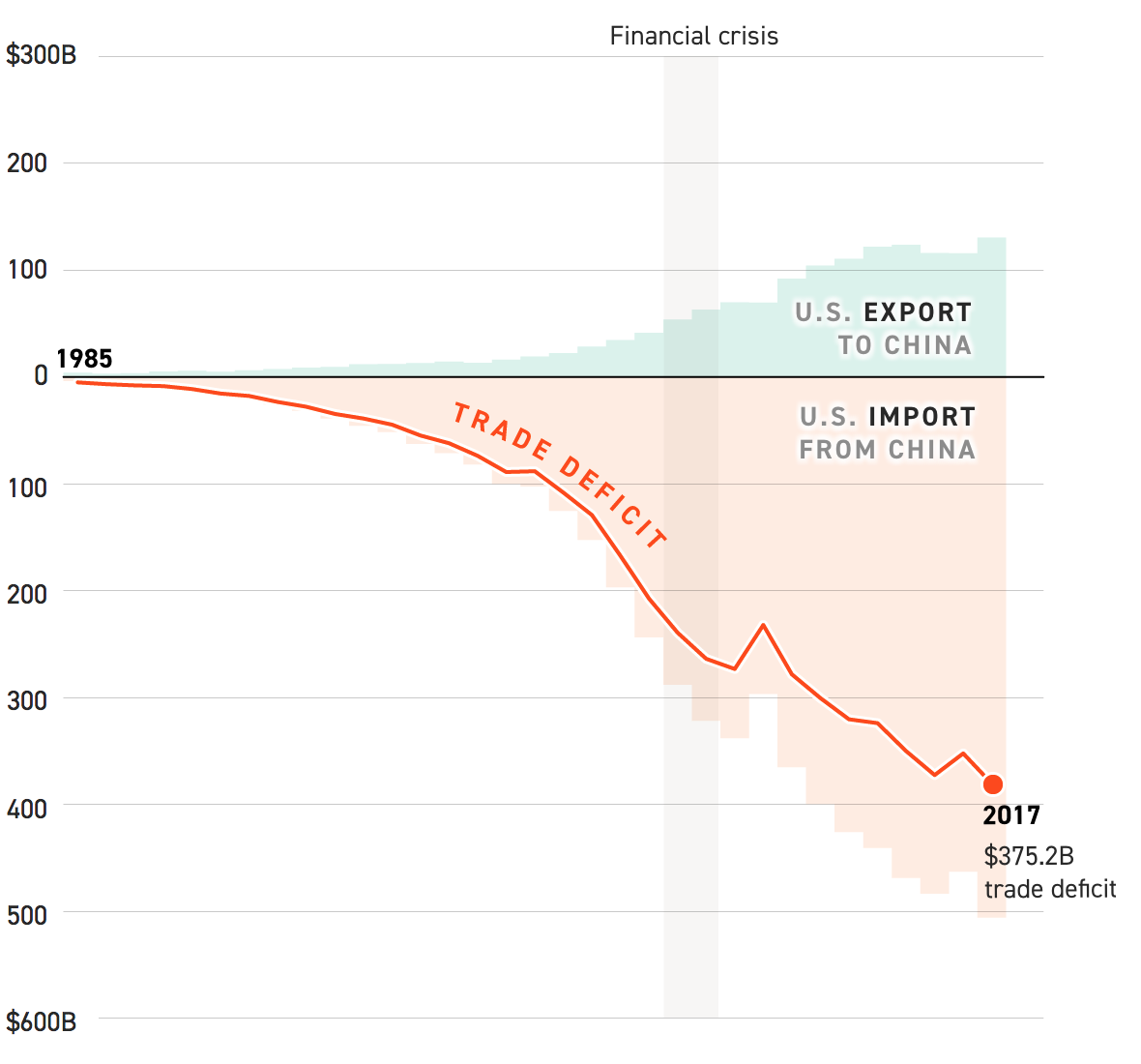
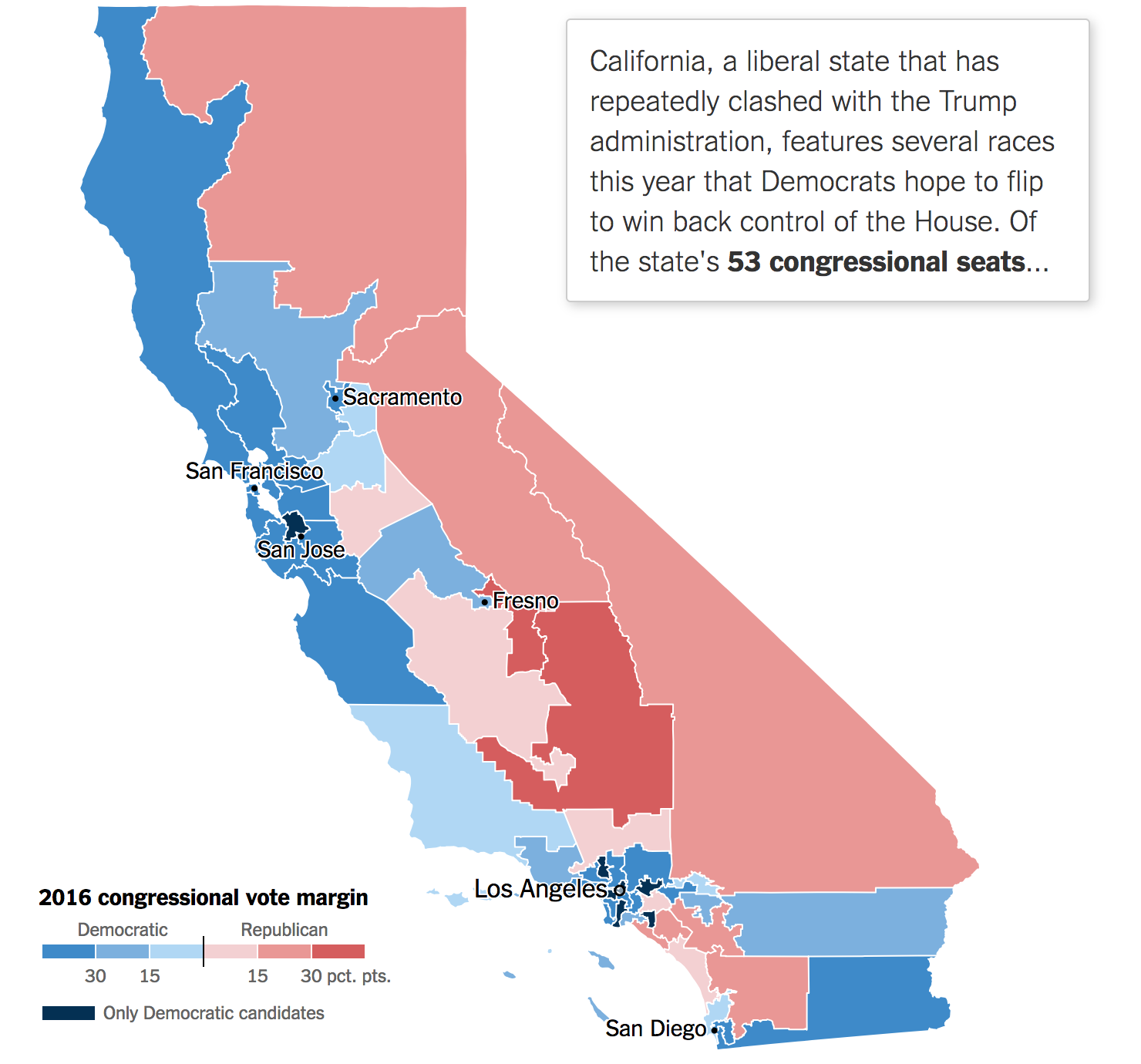
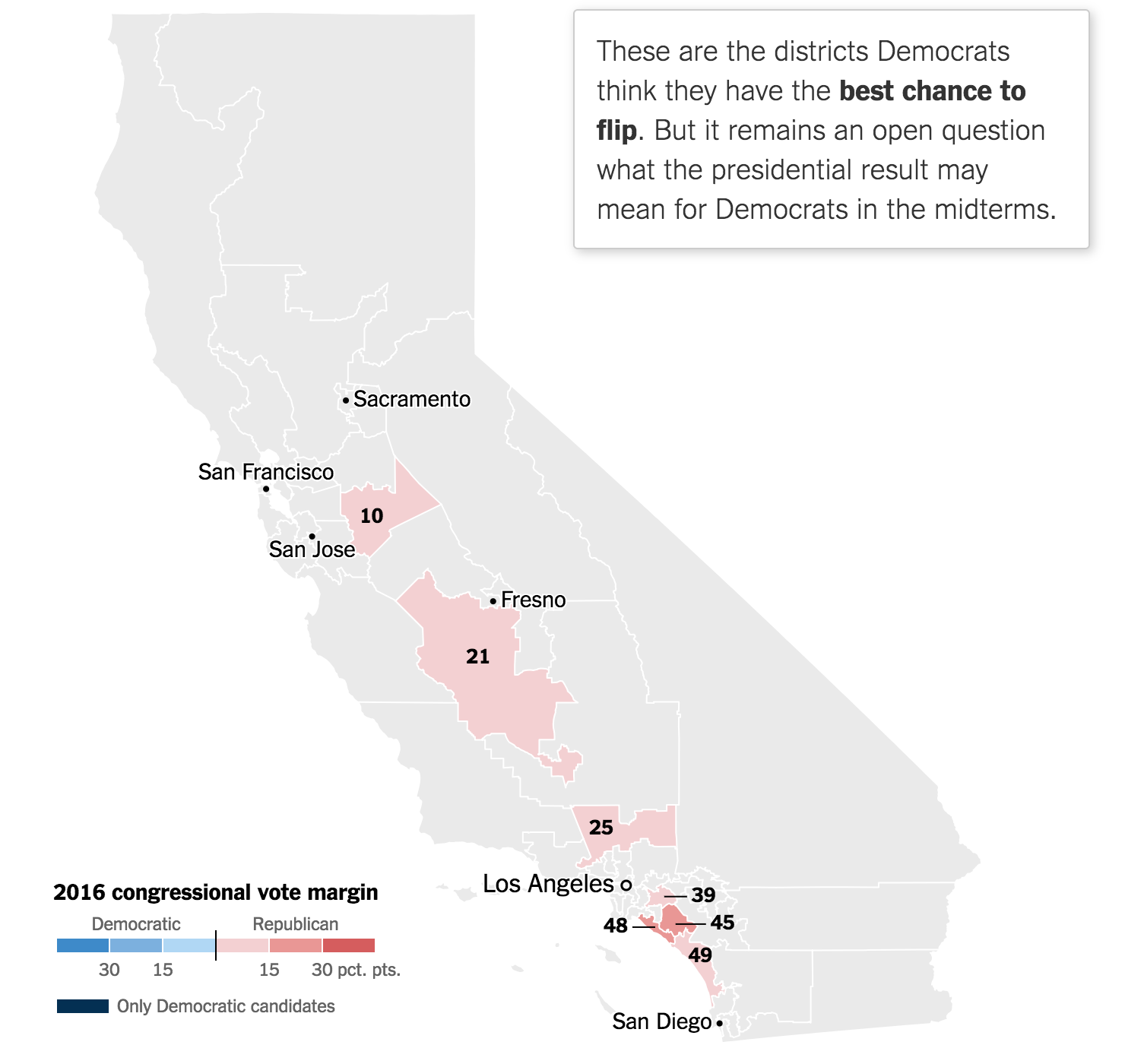
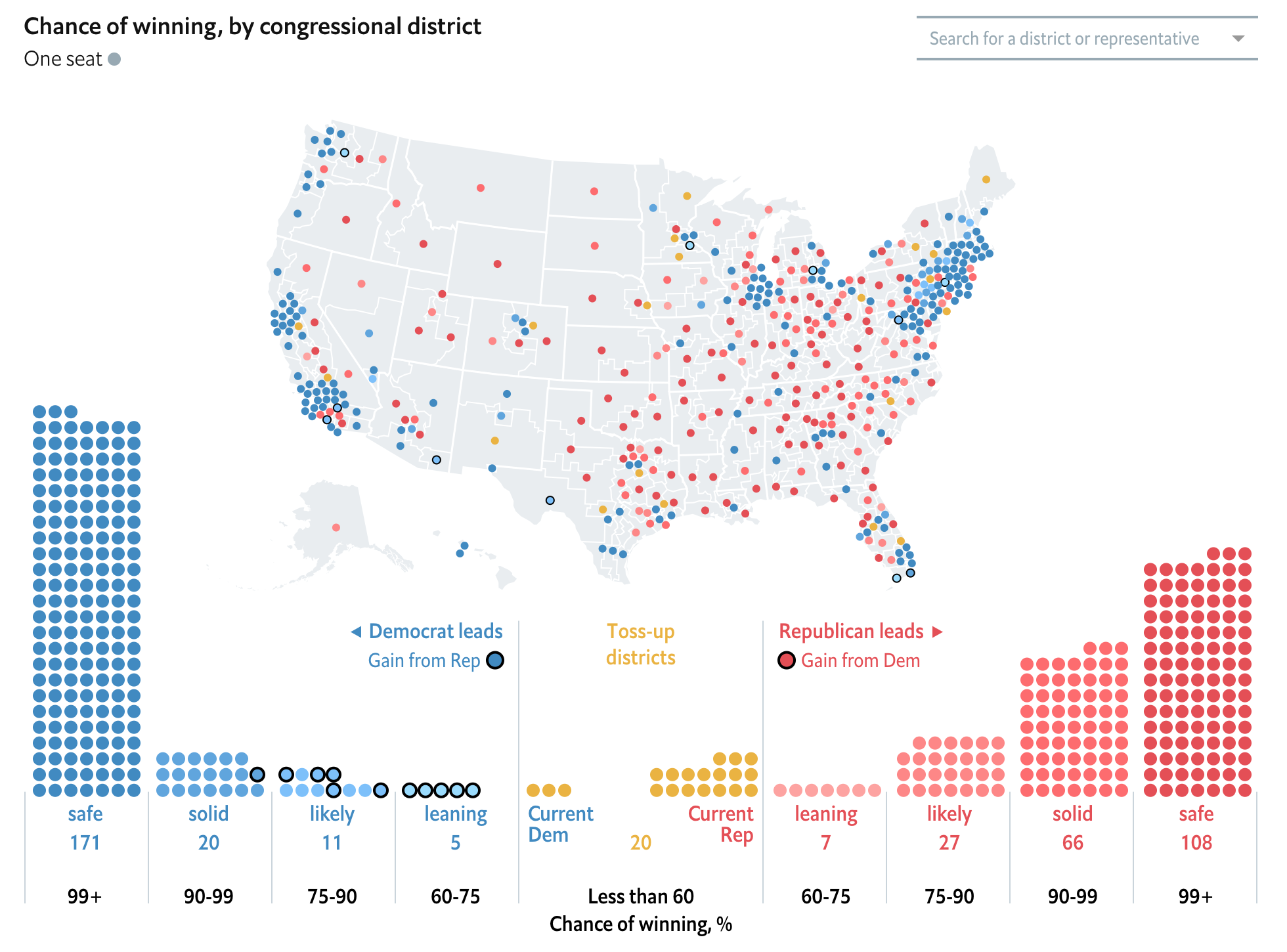
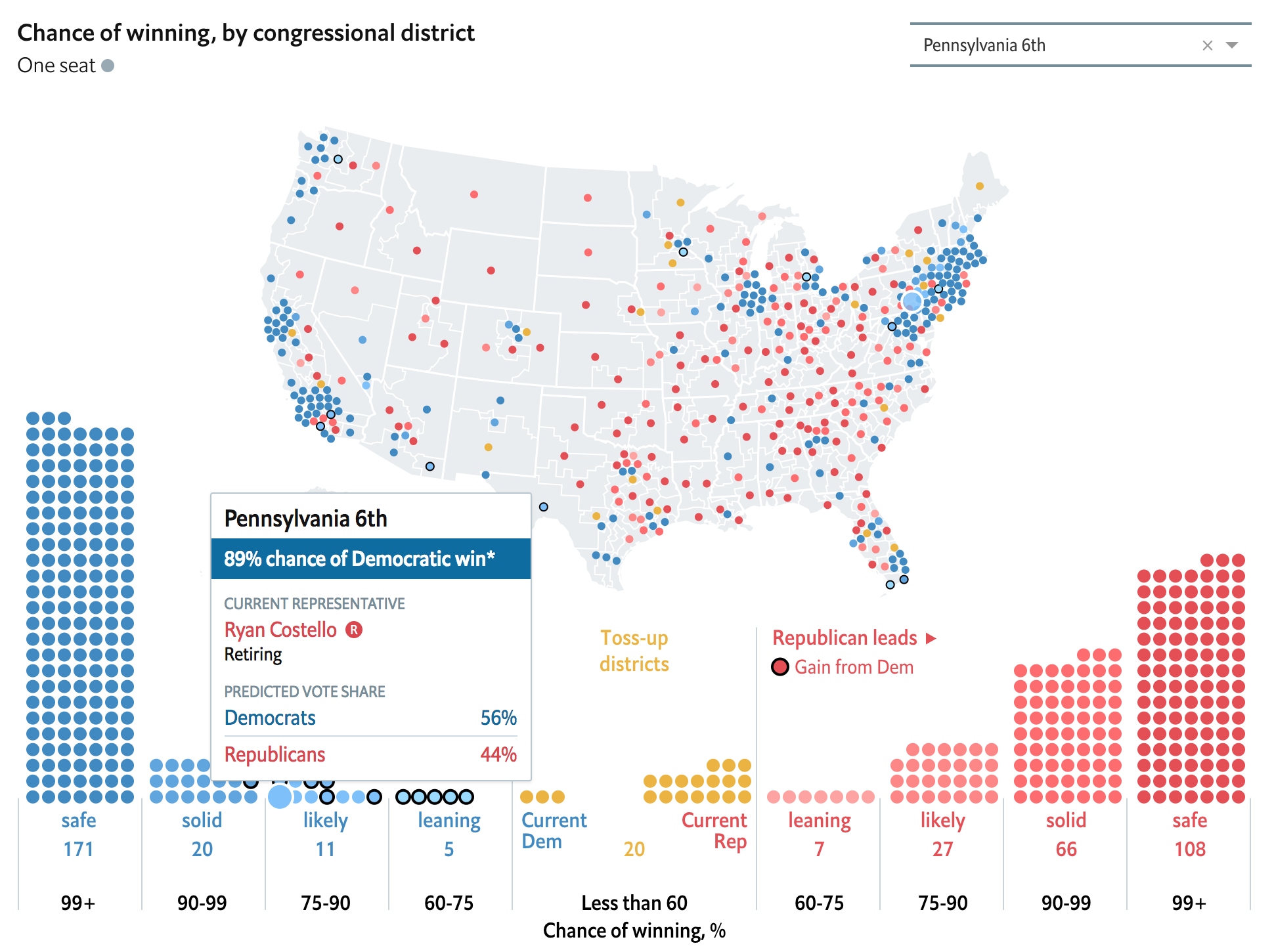
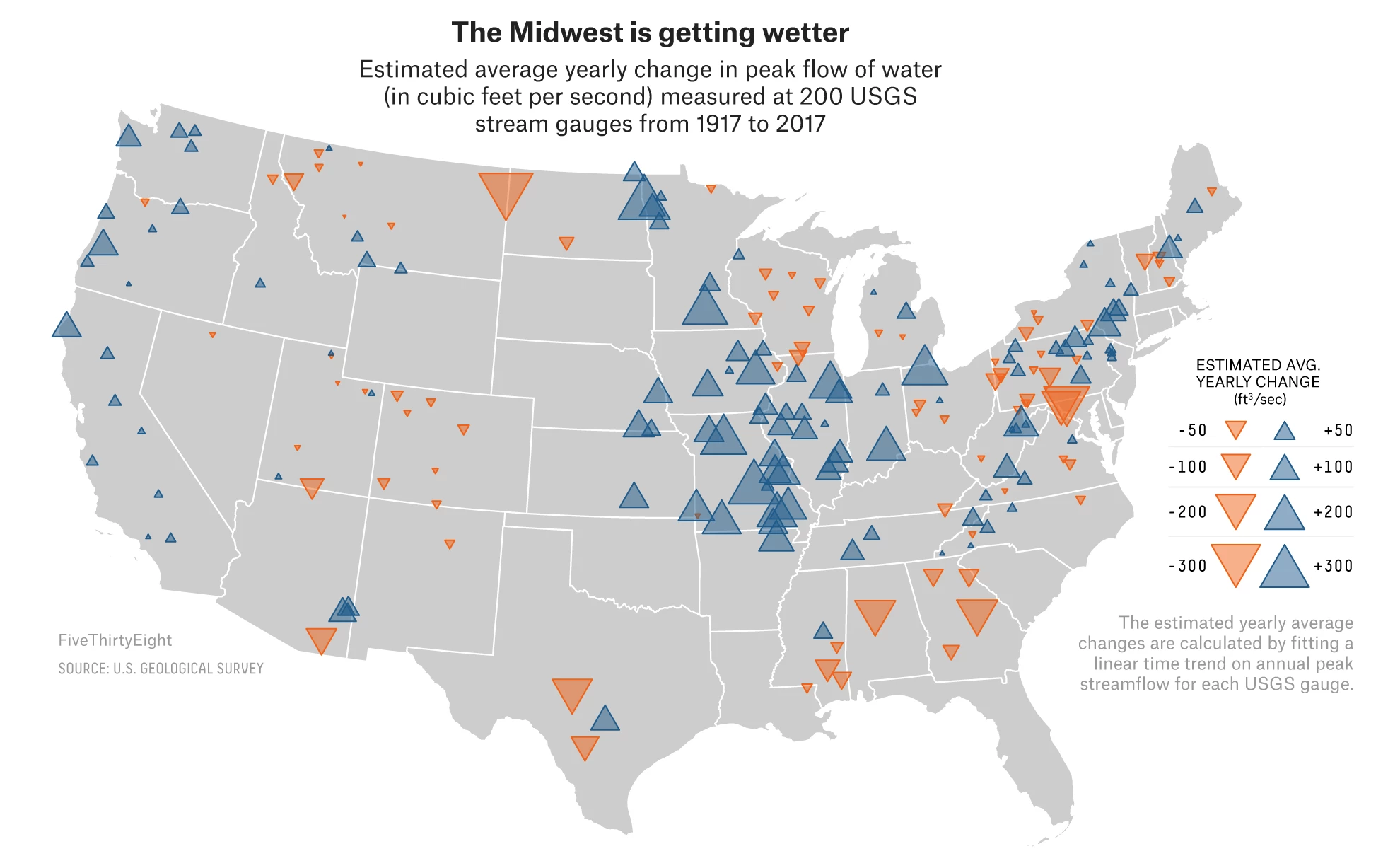
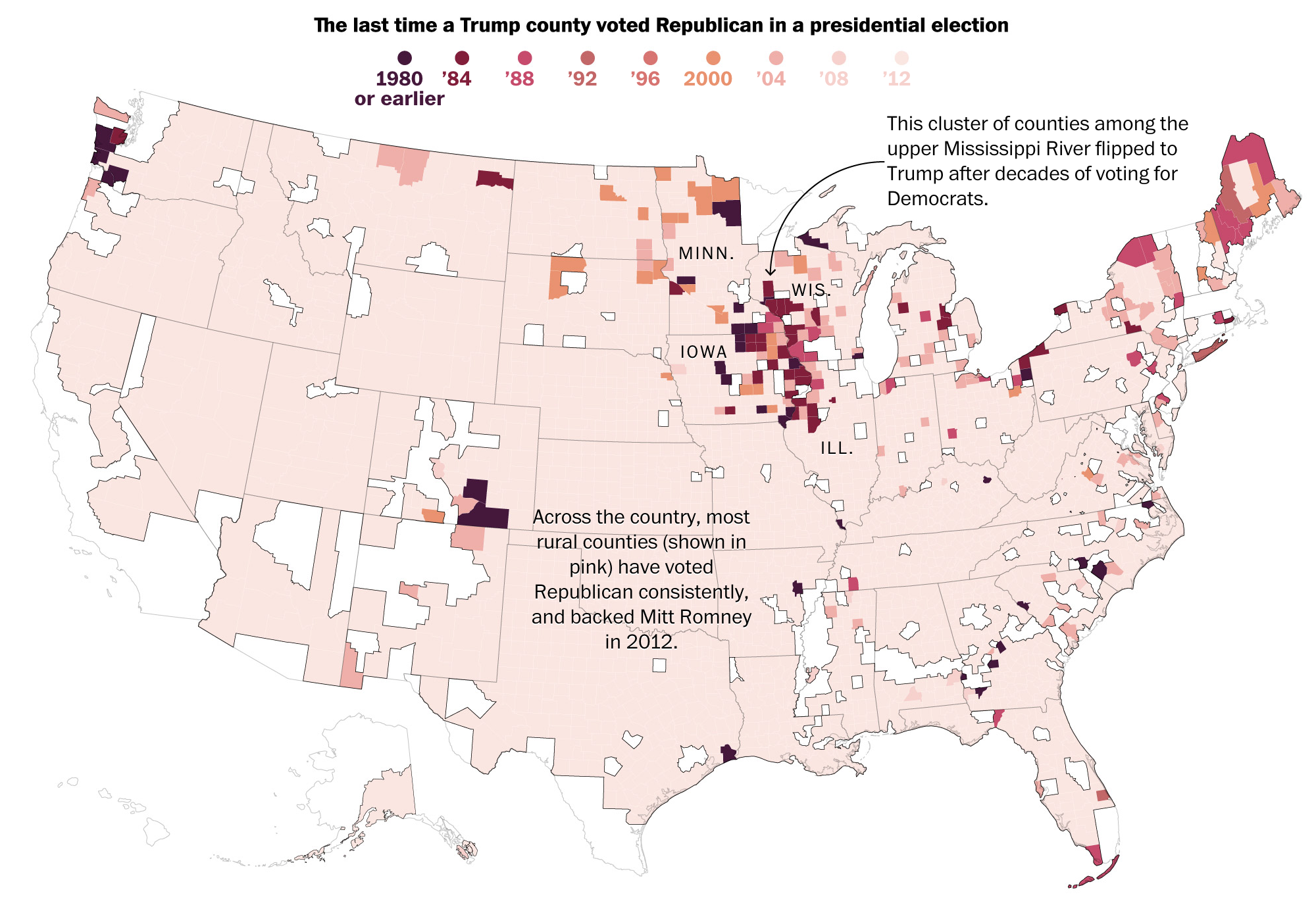
The World Cup continues. Well for a few teams. Some have already been eliminated from the Round of 16. But for those Americans rooting for Team America, well, if you have not yet figured it out, you got knocked out well before the World Cup even started by…Panama. And so you are stuck in the question of who’s next? Thankfully FiveThirtyEight, in addition to their fantastic live probabilities that we looked at the other day, put together a little quiz to help you find your new team.
You answer seven questions and you are told your new allegiance. Questions like this:
Naturally I took the quiz and discovered that in addition to England, I am cheering for…

Yep. Fantastic since I was just there in December and happened to love Stockholm. But what I love about this piece is how it uses data to create the newfound bond I have with Sweden. Often times you take a quiz and are given an answer without any sense of why the answer was correct. Here, FiveThirtyEight plots the seven different variables used to create your newfound personality and then shows you how you scored.
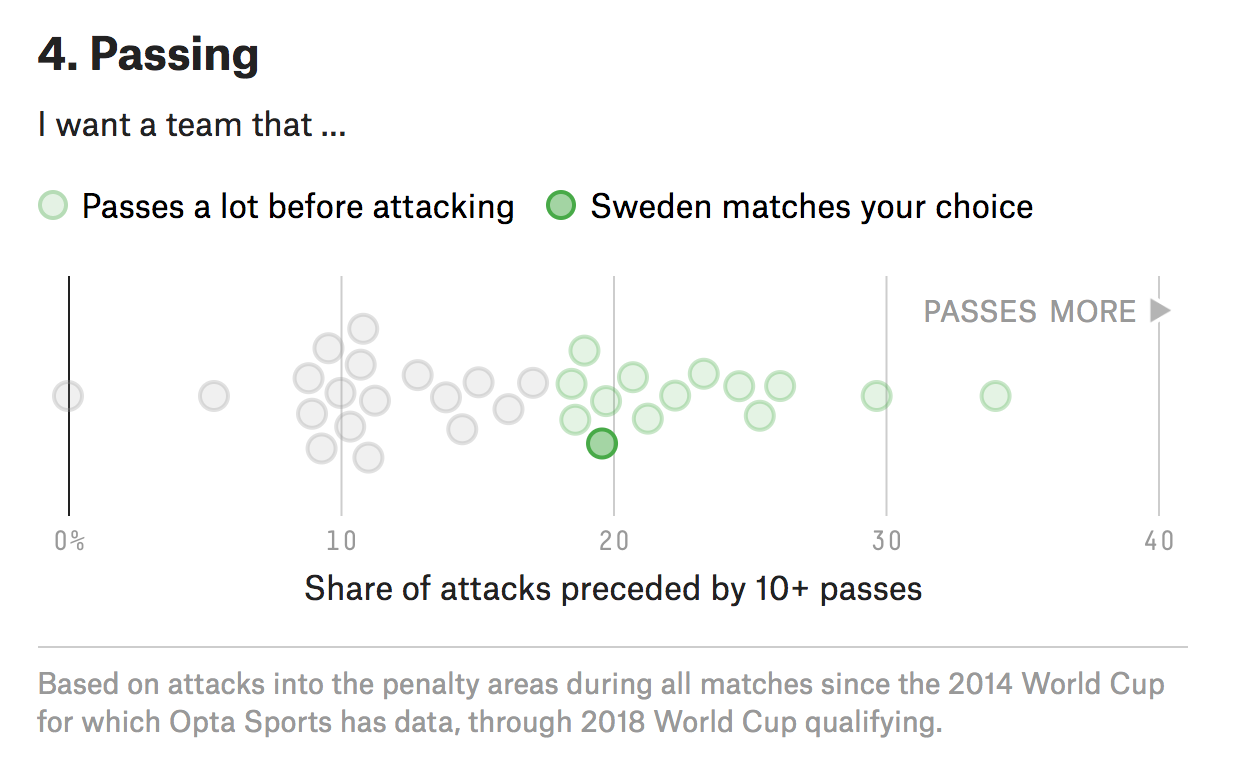
It’s Friday, it’s the World Cup. Have a great weekend. And in addition to England on Sunday, I’ll now be cheering for Sweden against Germany on Saturday.
Credit for the piece goes to Michael Caley, Rachael Dottle, Geoff Foster, Gus Wezerek, Daniel Levitt, Emily Scherer, and Jorge Lawerta.