Last week the Boston Red Sox won the 2013 World Series. I did a wee bit of celebrating and so I did not have the chance to post today’s post until, well, today. A company called Statlas charted each game of the World Series. One of my coworkers pointed me in the direction of these visualisations, unfortuantely I missed out on most of them for the playoffs. Here, though, is when I started feeling a lot less nervous about Boston’s chances for winning Game 6.
When the Red Sox won the game and the World Series
There is a lot to see and look at in these games. And I will be curious to see where Statlas takes these—if they take them anywhere—for the 2014 season. Baseball is a game rich with statistics and data and teams and fans are increasingly using them to play and understand the play in the games. It’s about time somebody starts doing some valuable visualisations.
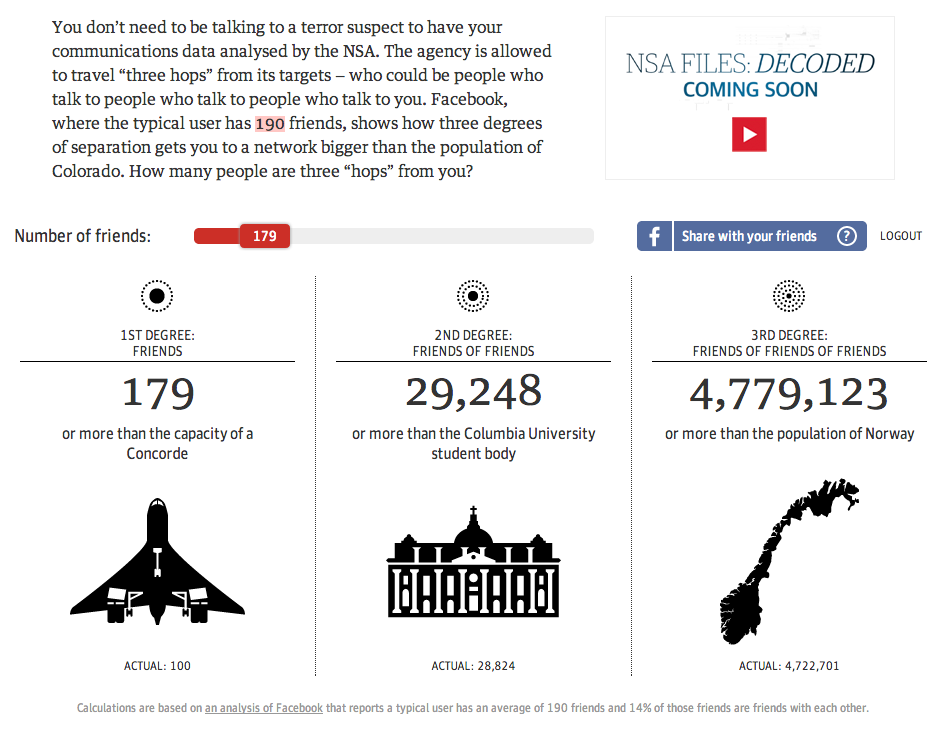
The thing with the NSA spy scandal is not that it collects data on Americans. But it collects data on the Americans that the Americans that the Americans know. Three degrees of separation can actually be quite a few people whose privacy is violated in the name of security. The Guardian has an excellent piece that shows you as in you yourself—if you grant access to your Facebook profile—how many people could be investigated because you know them.
My personal three hops
Well, I hate to tell you, Norway. But apparently, with me you are far from safe. Or at least a Norway-sized chunk of the American population. More seriously, this is a great piece that personalises an abstract sort of concept. Not just through the use of your own personal data, but by using (potentially) familiar items to contextualise scale. How many people is 190? Almost two Concordes worth. How many is 4,779,123 people? More than the population of Norway. You know, a country. Well done, Guardian.
Credit for the piece goes to the Guardian’s US Interactive Team.
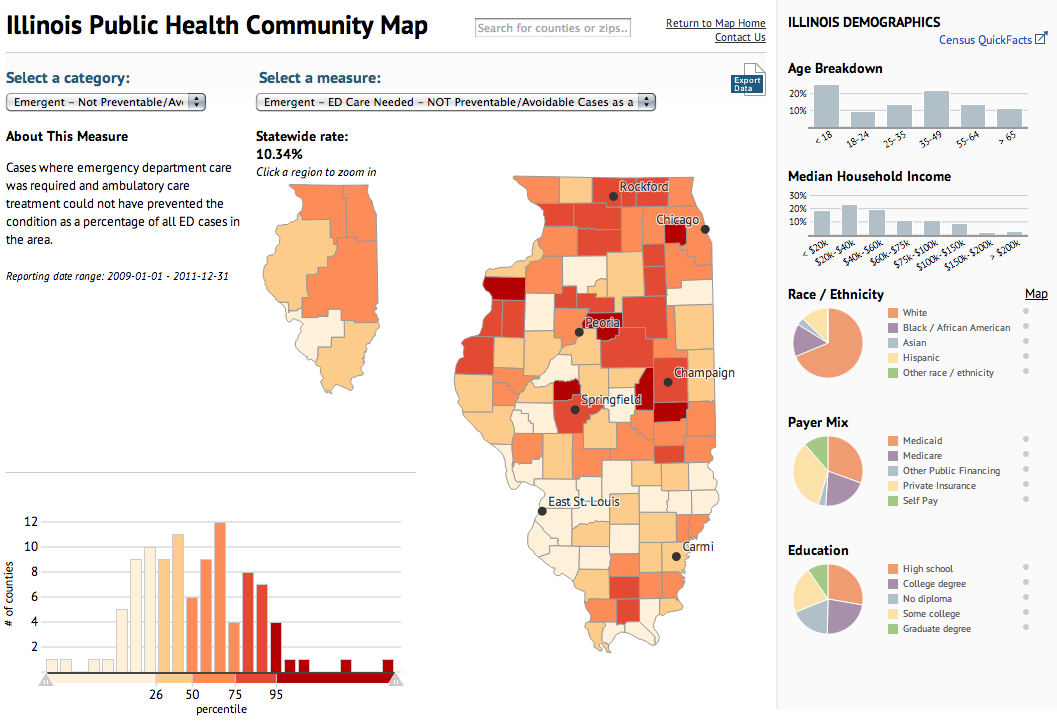
Today’s piece maps and charts comes from the Illinois Department of Public Health. The piece combines maps and charting components to detail preventable hospitalisations and emergency room use in the state of Illinois.
Public health map
Ordinarily I would prefer just one map, however, in this case the designers realised that a regional map—with its larger surface area—need not be as large as the county map. Some additional elements worth noting is the area devoted to the human explanation of the categories, which might otherwise be difficult to understand.
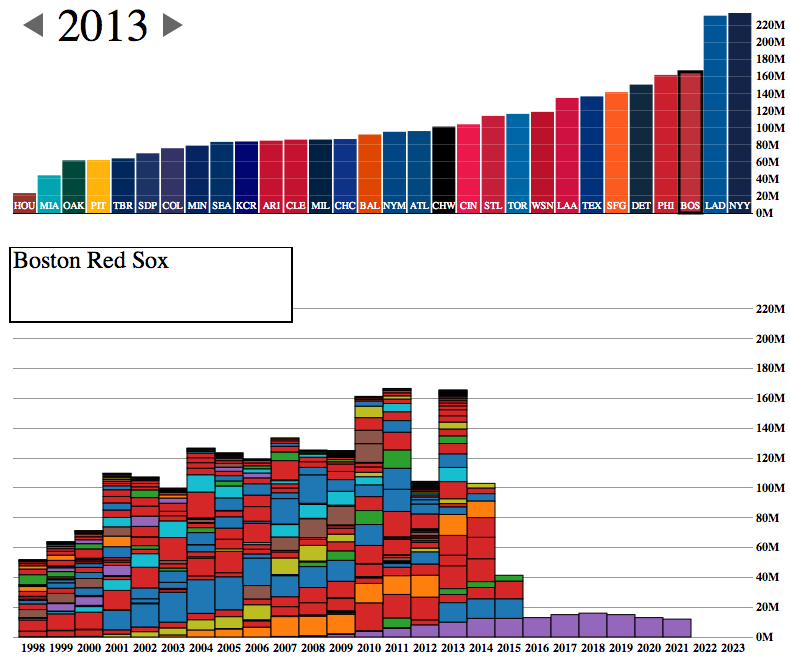
The World Series starts tomorrow night and for all but two teams, that means focusing on the upcoming 2014 roster. And rosters are often defined by payroll flexibility. A co-worker of mine forwarded along today’s interactive graphic that looks at team payrolls through stacked bar charts.
The Red Sox payroll
The design is certainly a bit clunky with heavy black outlines and garish colours. But the story told is clear, especially if you begin to look at different teams. Which teams have players locked up for the long-term and thereby have little flexibility?
The Red Sox, of course, sent most of that bar from 2011 to the Los Angeles Dodgers near the end of 2012. That allowed them to pick up the free agents like Mike Napoli, Johnny Gomes, Shane Victorino, and Koji Uehara. You know, the guys without whom the Red Sox would not have advanced to the World Series.
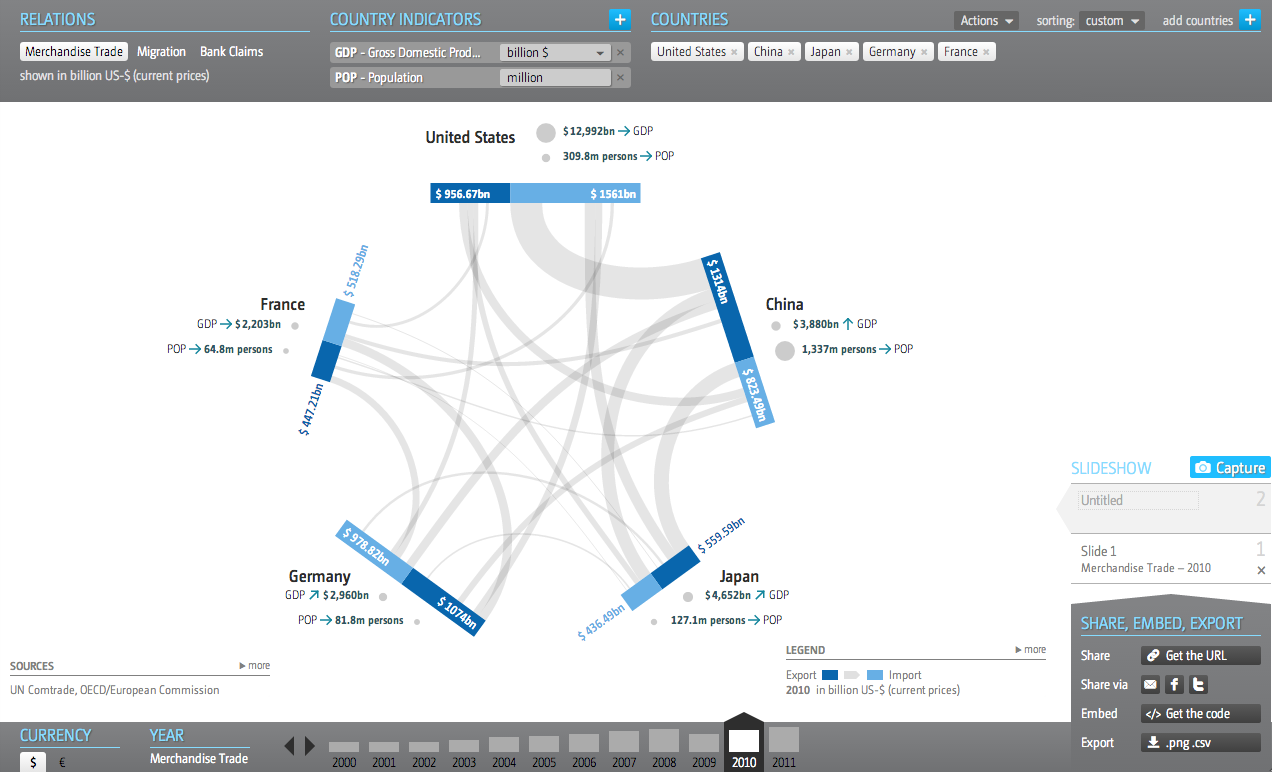
In the interests of transparency and full disclosure, for my employer I design interactive web-based applications that display significant amounts of data on various countries and industries—along with other design things. So I am always curious to see how others handle similar types and quantities of data. This interactive application—I hesitate to call something like this an interactive infographic because of its scale and scope—comes from the Global Economic Dynamics project.
The GED application
I commend the designers for opting not to use a map despite the nature of a dataset that focuses on countries. Especially in this application, where the full pattern of trade or migration would only be visible through multiple clicks to load maps of export/import markets of a particular country.
The user can add multiple countries, switch to a different dataset, change the year of the displayed data, currency, metrics, &c. There is quite a bit going on in this application and the controls are carefully placed in the margins of the piece.
And while I could probably write a lot more about this piece, I will end up the ability to share any insights made while using this application. Because what is the value of a kernel of knowledge if you cannot share it? Consequently, this piece offers a multitude of options. The usual social media options are present. You can also download a .png for use in a presentation, e.g. PowerPoint, or you can download the data. But fascinatingly, the application allows you to embed the piece into your own site.
Unfortunately, I cannot find any specific designers attached to the project. So credit goes to the Global Economic Dynamics project.
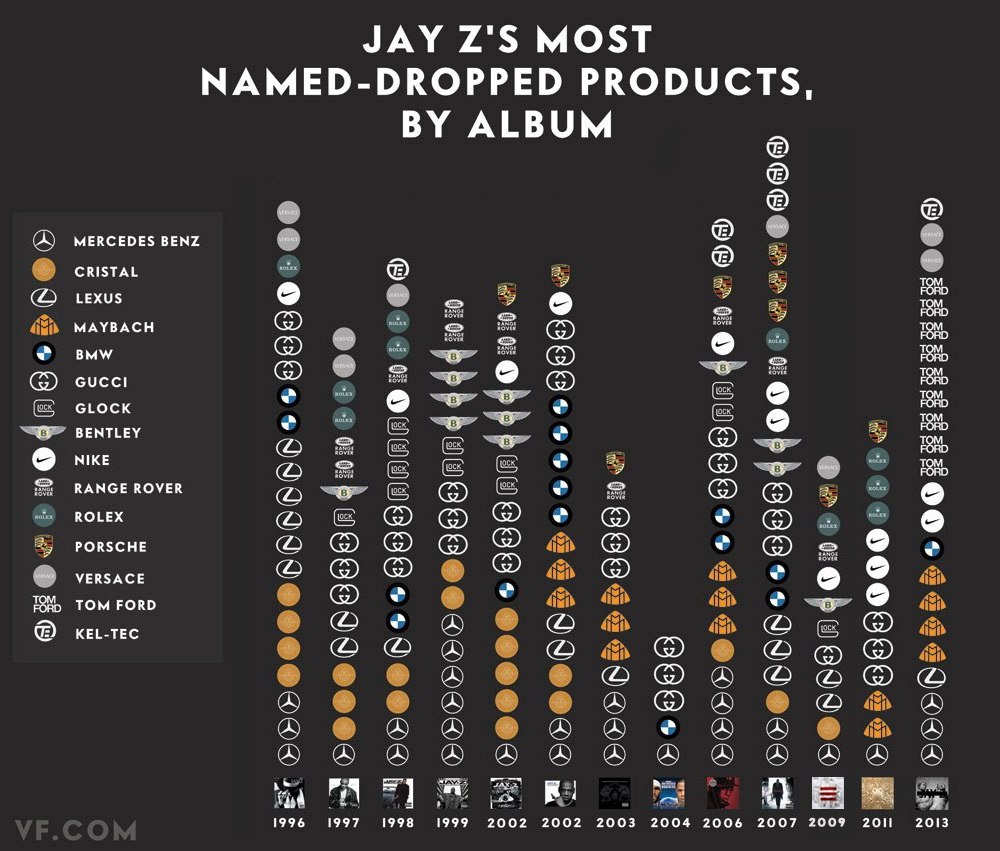
Happy Friday, everybody. Today’s post is a graphic from Vanity Fair that looks at the rapper Jay Z. (And for all those wondering, no, I have never intentionally listened to any of his music.) Specifically, this kind-of-stacked-bar-but-more-icon chart indicates how many times he name drops specific luxury brands in his albums.
Jay Z Brand Mentions
You can also file this under the graphics to which I cannot relate. Although maybe, just maybe, I once had a pair of Nike trainers. So at least Jay Z and I have that in common.
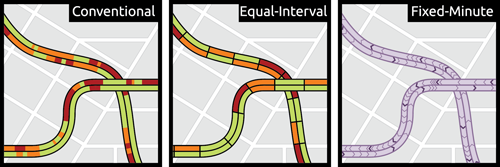
This small graphic is one of several from a very smart piece on redesigning the traffic map. Have you ever looked at a Google or an Apple traffic map to find the quickest route home or to get an idea of how long it will take you to get to the ballpark? According to Josh Stevens, your traffic map is lying to you.
Potential solutions
The article is a summary or overview of a research paper not-yet-published. When you have a few moments, the whole thing is worth the read for its analysis of popular transit map designs and the five big lies.
NBC News and Esquire magazine published results from their August survey of some 2000+ respondents that attempted to define the New American Center, i.e. the political persuasions of the majority of the country excepting the radical right and the loony left. For the purposes of Coffee Spoons, I am most interested in looking at the data visualisation and the infographics that result.
Both NBC News and Esquire visualised the results. While I could write two long blog posts looking at both of them, for today, it is more important to look more at the fundamental design difference between the two.
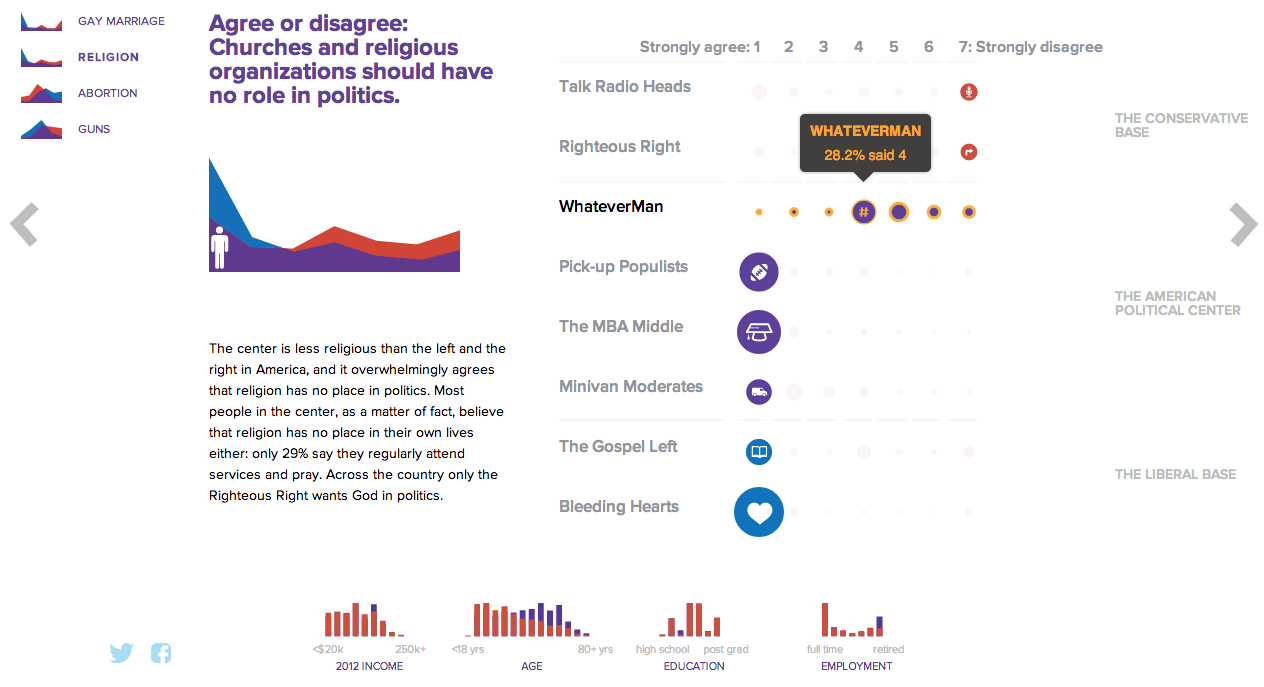
NBC News opted for a design direction emphasising data first. Perhaps because NBC is a news platform, their focus was on the clean communication of the data. Looking
NBC News results
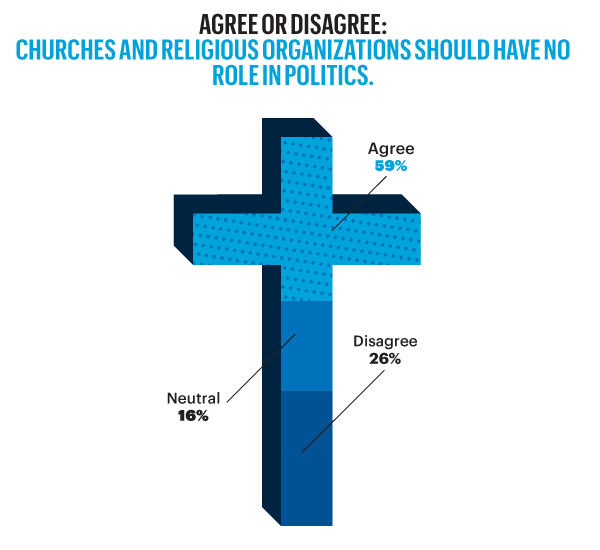
On the other hand, Esquire opted for a more sensationalised direction. The same data points used for the screenshot above creates this graphic below. Not only is less data is contained, less context given, less subtlety and nuance captured, it also is just difficult to read. Is the 59% supposed to be the area of the cross filled in? Its length? Why is it three-dimensional? Where are the Snowdens of yesteryear? At first glance, I ignore the horizontal wings and focus solely on the vertical length of the main bar.
Esquire results
For a useful representation of data, I think NBC News clearly wins. But that both organisations used the same data to craft their separate results, this story on the New American Center is useful for comparing two different design directions and the results thereof.
No designers are specifically mentioned, at least not that I could find, so credit for each piece goes to its respective owner, i.e. NBC News or Esquire.
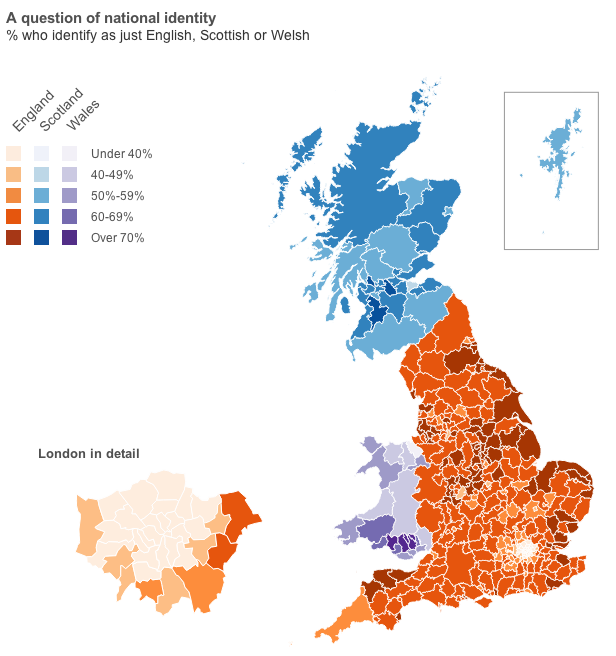
Well, you will have to click through to the article for that data visualisation. But, I will provide you with the choropleth map of national identities. That is, how English do citizens in English authorities consider themselves? Scottish in Scotland? Welsh in Wales?
Happy Friday, everyone. According to xkcd, I am failing the future test. That is to say, by 2019, I will be unable to communicate data through infographics or create data visualisations.