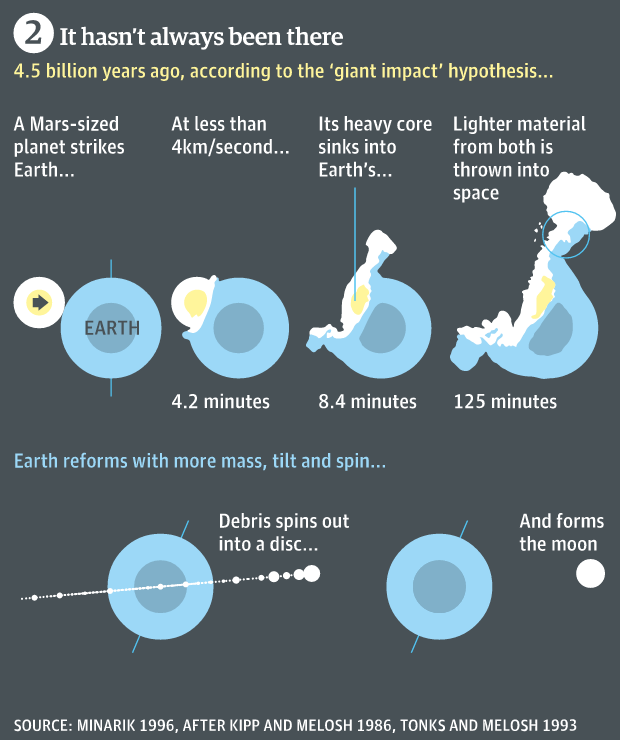
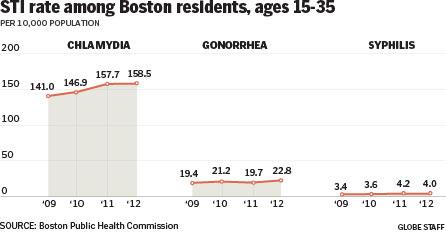Monday witnessed Super Moon. It’s not a bird, nor a plane. It’s the Moon. But bigger. Thankfully the Guardian put together a nice graphic that explains what was going on and puts the Super Moon into context of regular, average guy Moon.
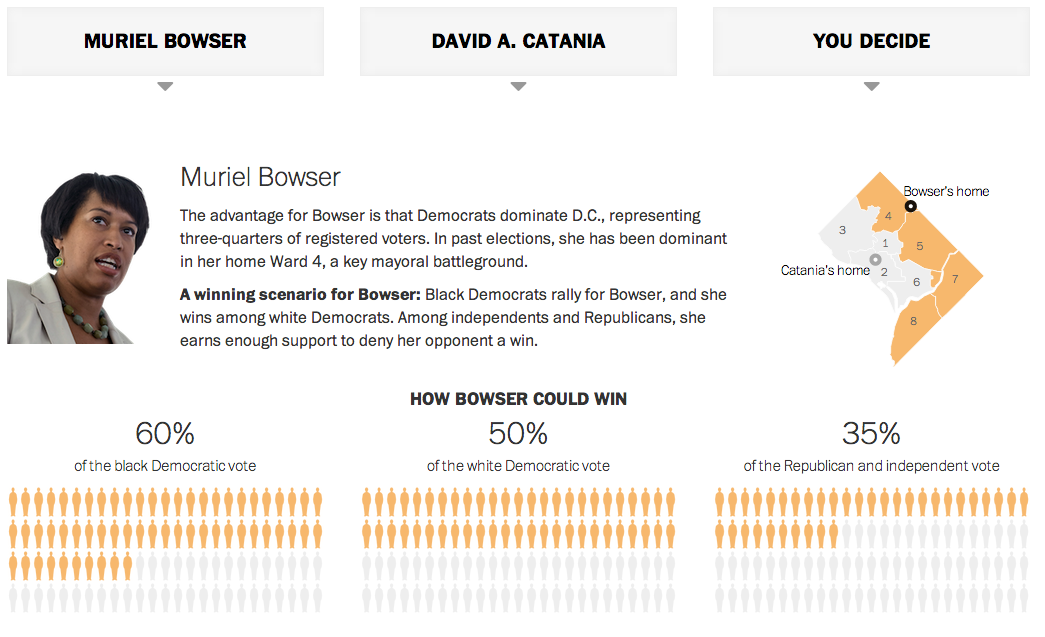
In November, among the many ballots will be that of the DC mayor. The Washington Post has a piece showing the power bases of the two main candidates. It also allows you to play with the vote allotment of the three key groups to show how you can build a 50% + 1 vote tally.
Vote scenarios
Credit for the piece goes to Denise Lu, Ted Mellnik, and Katie Park.
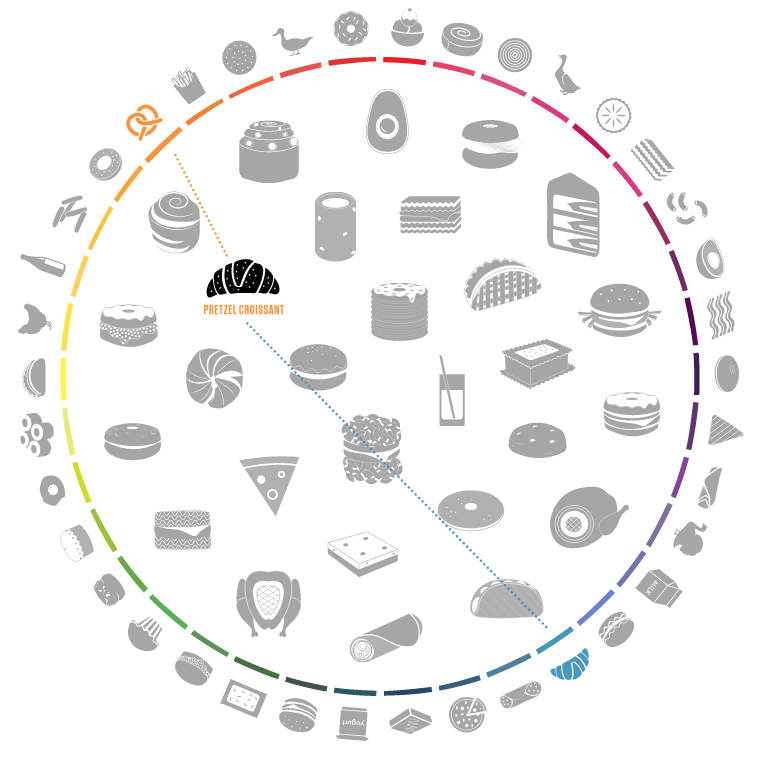
Everybody likes to eat out on the weekend. So from Co.Design comes an interactive diagram breaking down the constituent components of some of the best and worst food creations. Personally, I would have to go with the pretzel croissant.
In a piece of big news about Ukraine yesterday, the French government announced that it was halting the completion of the sale of two Mistral warships to Russia. The first such ship, the Sevastopol (yes, named after said city in Crimea), was due to be delivered in just over a month’s time. The two ships (the other named Vladivostok) would have given Russia the ability to launch amphibious invasions. The reason why this action was not taken earlier? Jobs. The construction of the two ships in French shipyards are a boon to the French economy. But after the recent “incursion” of Russian troops into Donetsk and Luhansk, Paris ultimately reconsidered the deal.
The Wall Street journal provides the graphic illustrating just how potent one of the ships would be.
Mistral design
Credit for the piece goes to the Wall Street Journal graphics department.
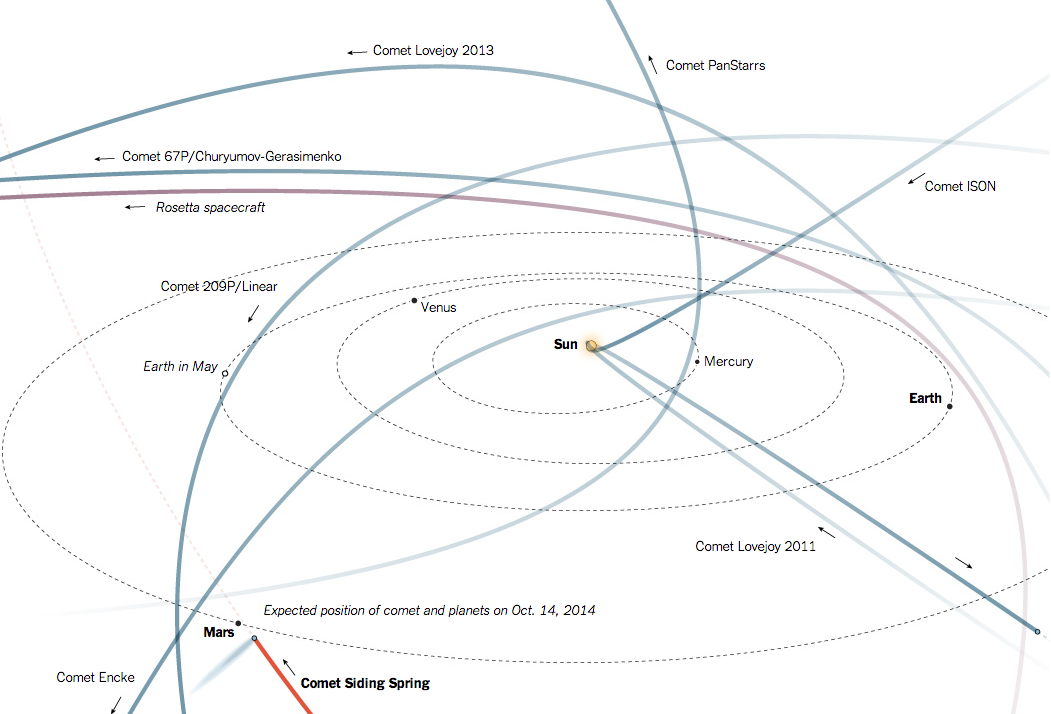
Today we head off to the stars. Well, more appropriately the comets. The New York Times had a piece a little while back that looked at the orbits of several comets that pass near the Sun. Siding Spring in particular is highlighted because of its near approach later this autumn.
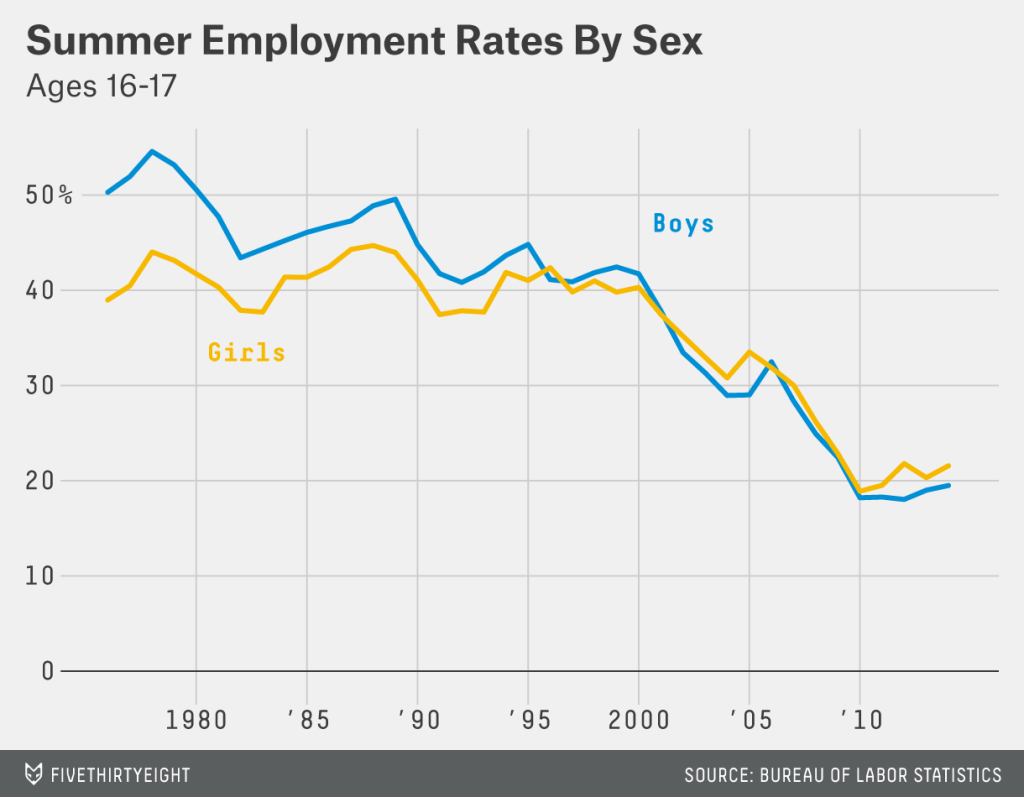
Sorry (American) folks, but Labour Day just came and went. And for us (Americans) that means summer has “officially” ended. Back in the day, for your humble author, that meant preparing to wrap up my summer employment at the Jersey Shore. The Sidewalk Sale was the great clearing of summer stock and most of us teenagers’ last working day. Fast-forward a decade and it turns out most teenagers are no longer working summer jobs. Five Thirty Eight put together a small set of graphics to support an article explaining the decline. (It’s not all recession-related.)
Your humble author has returned to Chicago from several days spent in Boston—among other places. So what better way to follow up on yesterday’s post about prostitution than a small piece from the Boston Globe about the increase in sexually transmitted infections (STIs) in Boston. The cause? Hook-up apps. Because, technology and young people.
Rise in STIs in Boston
Credit for the piece goes to the Boston Globe’s graphics department.
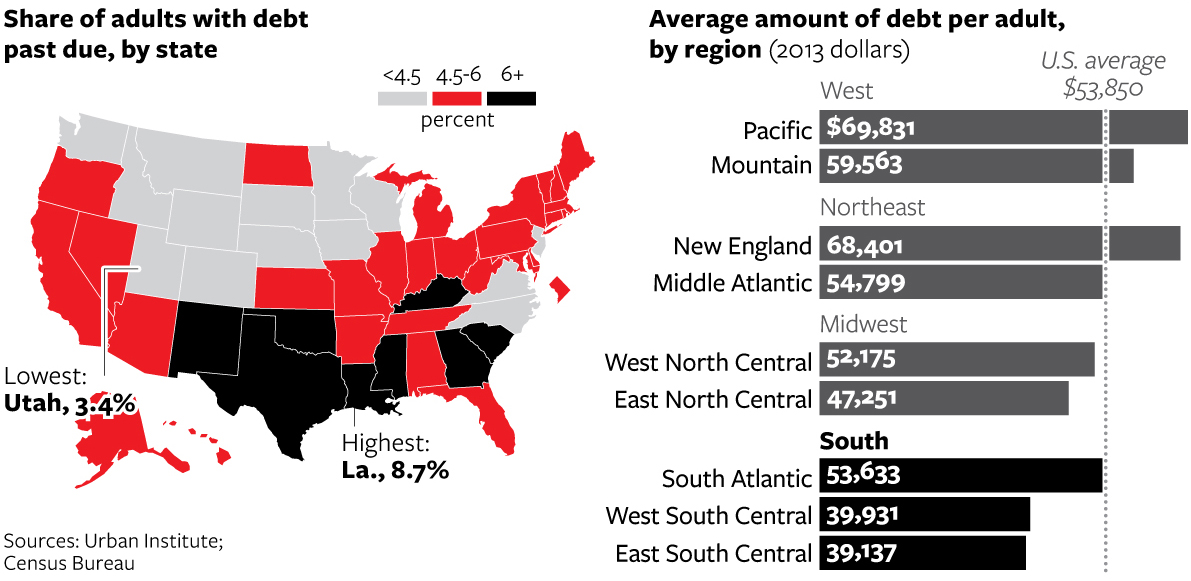
In a good example of comparing share versus actuals, the National Journal looks at the state of debt across the United States. The choropleth map shows adult share of debt while the bar charts show the regional value of said debt. While the south holds more debt, the west and east coasts have more debt. They also, however, have higher incomes that make servicing or paying off said debt easier than lower income adults in the south.
The South’s victory is debt
Credit for the piece goes to Nancy Cook and Stephanie Stamm.