This Friday I want to highlight a graphic from xkcd that, strictly speaking, isn’t really data visualisation, but it does speak to that world because it’s about the underlying data.
And as with the best humour, there’s an element of truth in it.
In 2014, what became known as little green men invaded Crimea, Ukraine. No, these were not aliens, but what we’ve later learned were unmarked Russian Army soldiers. They routed what little resistance Ukraine mustered in 2021 Crimea is de facto Russian, though de jure it remains Ukrainian.
Following Crimea, insurrections erupted in the Donbas, part of the mainland—yes, Crimea is connected through a thin strip of land, but in many ways it’s effectively not part of the mainland—bordering Russia. We suspect these too also included Russian Army regular, most notably the downing of Malaysian Airlines Flight 17. That civilian passenger airliner, filled with 298 people, was shot down by an SA-11 Gadfly, in use by the Russian Army across the border. But overall, the feeling is that in Ukraine, Russia uses paramilitary forces and private mercenaries, or at worst, soldiers “on holiday” to do Russia’s dirty work.
I covered the invasion of Crimea and the operations in Donbas extensively. Well, extensivelyforme.
In the years since, we’ve seen the emergence of the Wagner Group, a private mercenary group similar in concept to Blackwater. You have some fighting to do, they’ll do it for cash. But Blackwater, whose name has changed several times over the years, was largely staffed by ex-soldiers and had some infantry weapons to support them. Wagner Group is different.
And to see how different, you need only read this great BBC article that exposes some of the group’s details because of a tablet left behind by a Wagner mercenary. It is a bit of a lengthy read, but it’s well worth it. Wagner has been engaged/hired in Ukraine, Syria, and now Libya where it fights against the UN-backed government in Tripoli.
The data visualisation and information design here is mostly around forms and some illustrations of mines—the blow up and kill/main people kind, not the mineral extraction kind. But what sells the idea that Wagner is really more a shadowy appendage of the Russian state than some rogue private mercenary army are things like this document.
You get a tank, and you get a tank, and you…
It, as the file photo hints, shows that Wagner is requesting a T-72 main battle tank for their operations in Libya. Blackwater committed crimes in foreign countries, but it never operated modern main battle tanks.
I also highlighted two other requisitions contained above the T-72. In purple we have an ask for two BTR-82s. These are more modern versions of the Soviet staple, BTR-80, a wheeled armoured personnel carrier. Then in orange we have a request for one BMP-2. This is a tracked infantry fighting vehicle.
In other words, Wagner is requesting the equipment necessary to field a scaled down version of a modern armoured division with heavy tanks and supporting infantry vehicles, both tracked and wheeled. It also contains requests for 120mm mortars, highlighted by the BBC. These are not things that a private mercenary army would have floating around a warehouse.
For this and other funding-related reasons, Wagner Group is increasingly seen as a part of the Russian government’s, i.e. Putin’s, foreign and security policy apparatus. The Russian state might not be able to be officially involved in Libya or Chad or the Central African Republic, where rumours abound of Russian-speaking mercenaries, but Wagner can because officially it doesn’t exist.
Yesterday was maybe the last election day for the 2020 US General Election. (There are still a few US House seats yet to be called, most notably a contested race in upstate New York.) These were a pair of runoff elections in Georgia for the state’s two US Senate seats (one for a full, six-year term, the other to finish out the final two years of a retiring senator).
I spent most of the night eating pizza and tracking results. One thing that I keep tabs on (in the sense of open tabs in the browser) is the New York Times needle forecast. It has its problems, but I wanted to highlight something I think was new last night. Or, if it wasn’t, I didn’t notice it back in November.
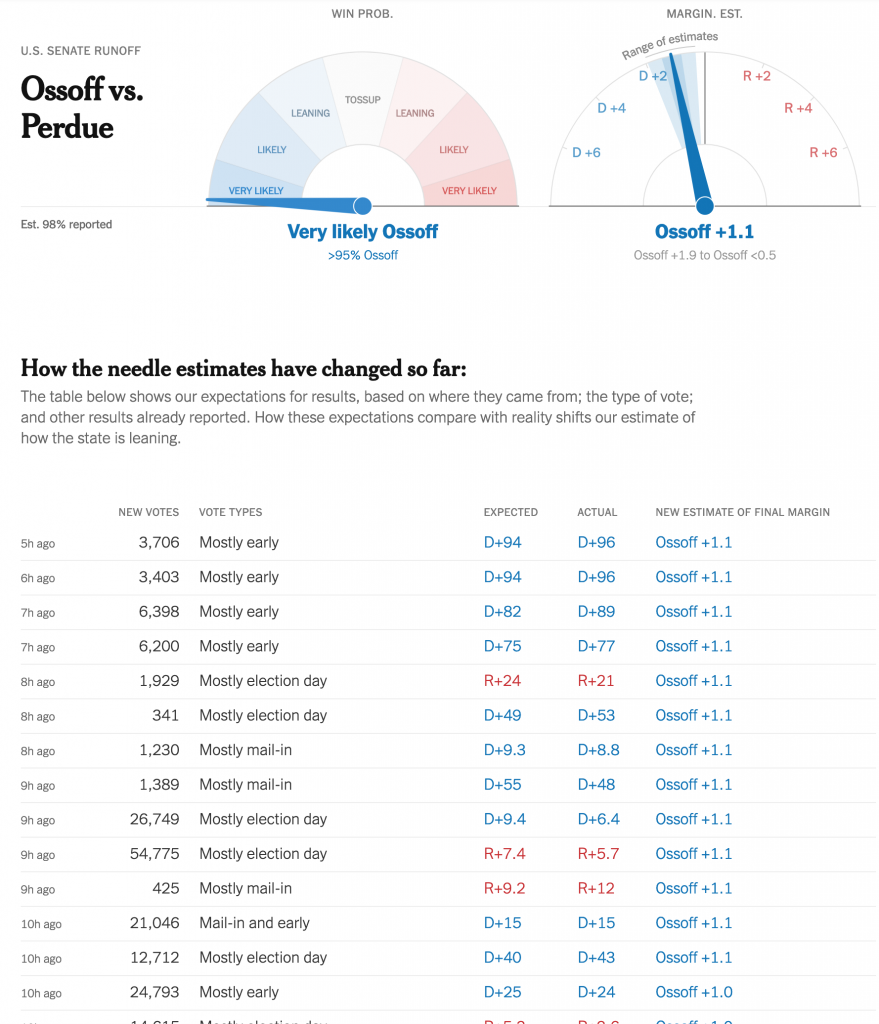
Below the needle was a simple table of results.
The needle speaks
In the past, the needle was a bit opaque and it consumed data and spat out forecasts without users having a sense of what was driving those forecasts. Back in November, there were a few instances where states published incorrect data—that they later fixed—and when the needle consumed it, the needle forecast incorrect results.
But now we have a clear record of what data the forecast consumed in the table below the needles. It’s fairly straightforward as tables go. But tables don’t have to be sexy to be clear and effective.
The table lists the time when the data was added, the number of votes added, the type of vote added, and then the actual data vs. what was expected. And ultimately how that changed the needle. This goes a long way towards data transparency.
Simple colour use, bright blues and reds, show when the result/data favoured the Republican or Democrat. Thin, light strokes instead of heavy black lines for rows and columns place the visual emphasis on the data. And smaller type for the timestamp places the less important data at a lower level of importance.
It’s just very well done.
Credit for the piece goes to Michael Andre, Aliza Aufrichtig, Matthew Bloch, Andrew Chavez, Nate Cohn, Matthew Conlen, Annie Daniel, Asmaa Elkeurti, Andrew Fischer, Will Houp, Josh Katz, Aaron Krolik, Jasmine C. Lee, Rebecca Lieberman, Jaymin Patel, Charlie Smart, Ben Smithgall, Umi Syam, Miles Watkins and Isaac White.
Monday I examined a chart from the BBC that in my mind needlessly added confusing visual components to what could have been a straight table. So here we take a look at some other options that could have been used to tell the same story. The first is the straight forward table approach. Here I emphasised the important number, that of those killed. I opted to de-emphasise the years and the injured in the table. Also, since the bulk of my audience is from the United States, I used the two-letter states codes.
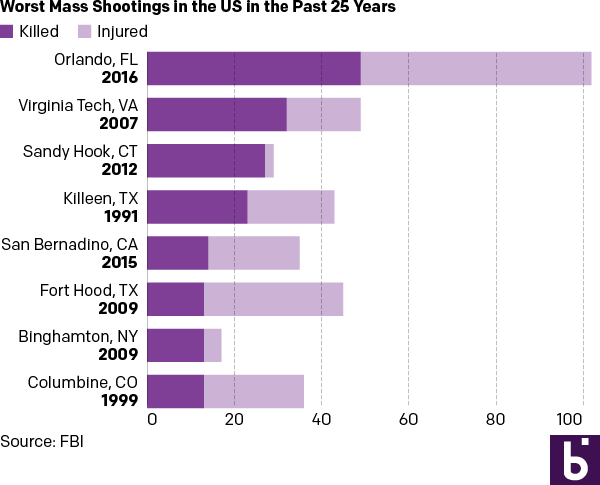
But let us presume we want a graphic because everyone wants everything to be visual and graphic. Here are two different options. The first takes the table/graphic from the BBC and converts it into a straight stacked bar chart, again with emphasis on the dead. I consolidated the list into a single column so one need not split their reading across both the horizontal and vertical.
As a stacked bar chart
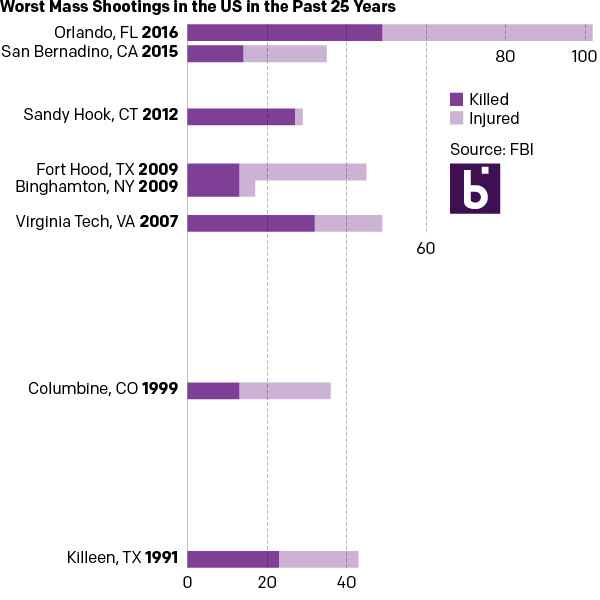
And then if you examine the dates, one can find an interesting component of the data. Of the top-eight shootings, all but two occurred within the last ten years. So the second version takes the graphic component of the stacked bars from the first and places them on a timeline.
In a timeline
For those that wonder about the additional effort needed to create three different options from one data set, I limited myself to an hour’s worth of time. A little bit of thought after examining the data set can save a lot of time when trying to design the data display.
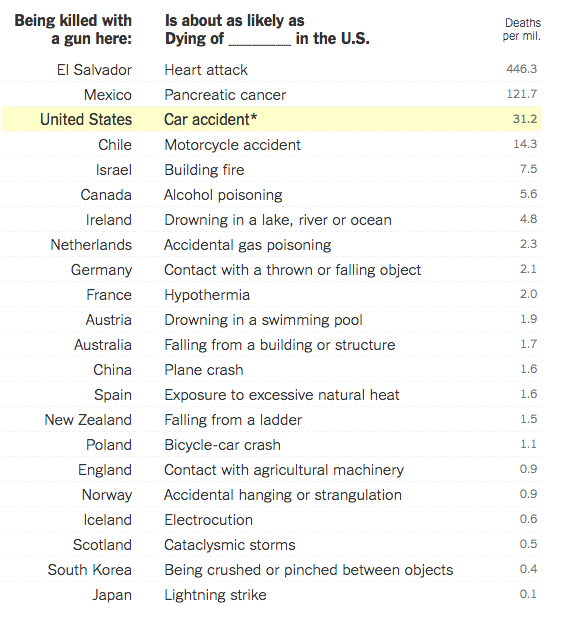
Yesterday I opined about how simple tables can convey meaningful information without the aid of unnecessary chart elements. And while we will get back to that post, I did want to take a moment to share an older piece from the New York Times I recalled and that has been updated since Orlando.
The piece uses a table to compare the gun homicide rates for various countries and compares it to other causes of death. Being killed by a gun in the Netherlands is as likely as dying by accidental gas poisoning in the United States. It puts the absurdly high gun homicide rates in the United States in a new light.
A table of death
Credit for the piece goes to Kevin Quealy and Margot Sanger-Katz.
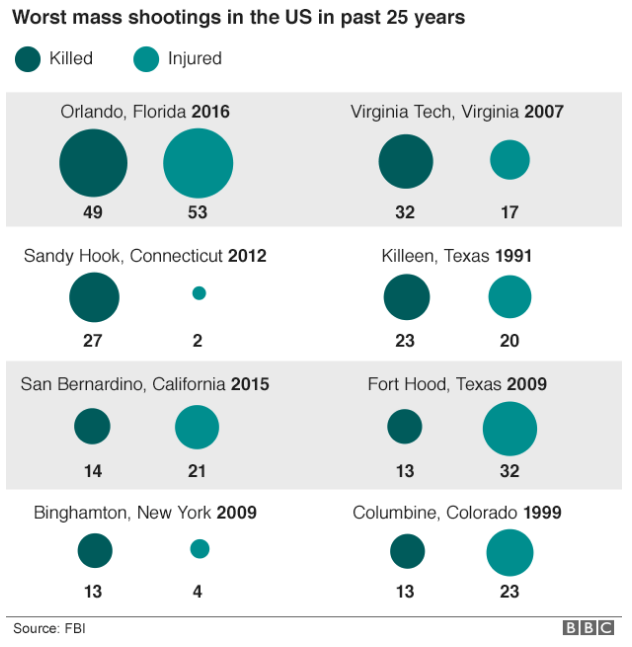
I will be trying to do a longer piece on the data visualisations surrounding the shootings in Orlando later this week. But for starters, a simple point through this piece from the BBC—not that they are the only culprits of this. Not all data-driven stories need visualisations. Sometimes a nicely typeset table will do the job better and faster.
Green circles?
An actual table with typographic emphasis on the tables would have been better and clearer than this. Or with a little more time and effort—not that those always exist in a journalism organisation—something more appropriate to the type of data could have been designed.
Credit for the piece goes the BBC graphics department.
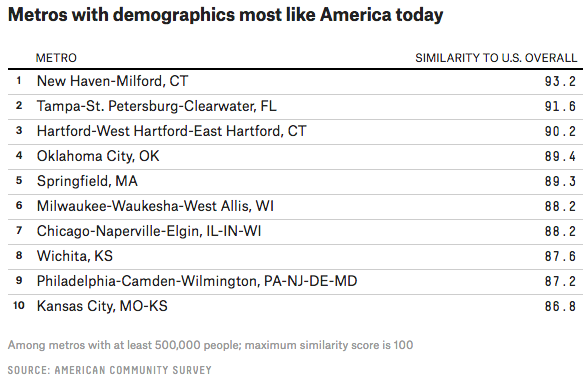
Not every graphic information graphic is a sexy chart or map. Sometimes tables communicate the story just as well. Maybe even better. Today’s post comes from FiveThirtyEight, which examined a claim about what places represent “Normal America”. Turns out that when one looks at the data, here age, race, ethnicity, and education, Normal America is found in the eastern half of the country. And it includes some big cities, notably both Philadelphia and Chicago. The whole article is worth a read, as it goes on exploring states representing Normal America and then places that represent 1950s America.
Where is Normal America?
So where is Normal America? New Haven, Connecticut.
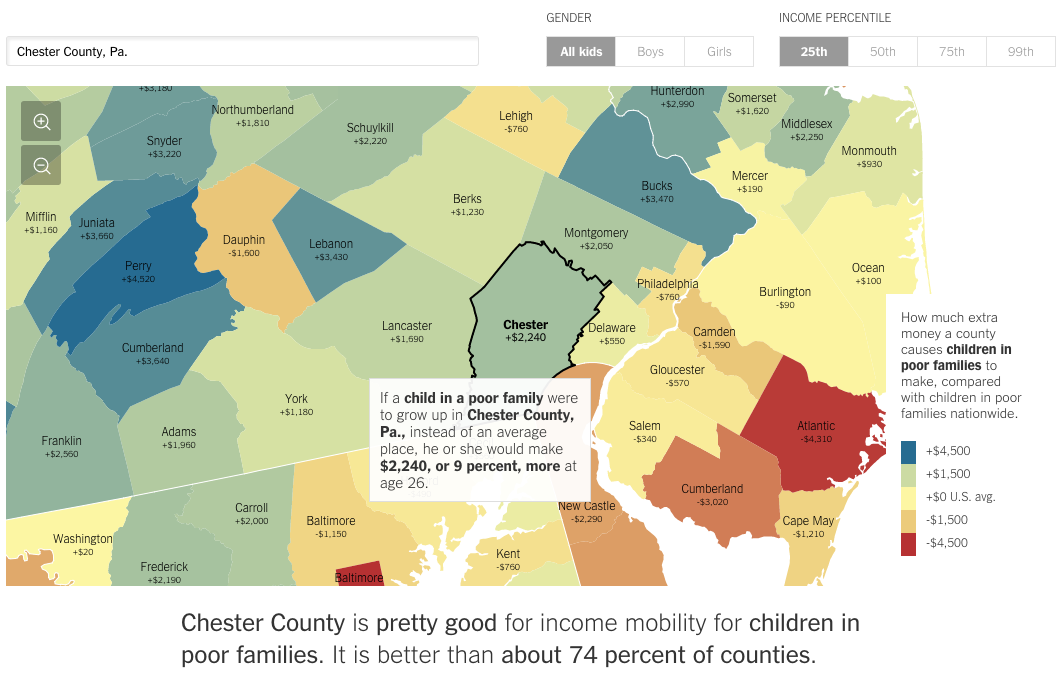
Today we have a really interesting piece from the New York Times. In terms of visualisations, we see nothing special nor revolutionary—that is not to say it is not well done. The screenshot below is from the selection of my hometown county, Chester County in Pennsylvania. Where the piece really shines is when you begin looking at different counties. The text of the article appears to be tailored to fit different counties. But with so many counties in the country, clearly it is being done programmatically. You can begin to see where it falls apart when you select rather remote counties out west.
How the poor in Chester County fare
But it does not stop simply with location. Try using the controls in the upper right to compare genders or income quartiles. The text changes for those as well.
Credit for the piece goes to Gregor Aisch, Eric Buth, Matthew Bloch, Amanda Cox, and Kevin Quealy.
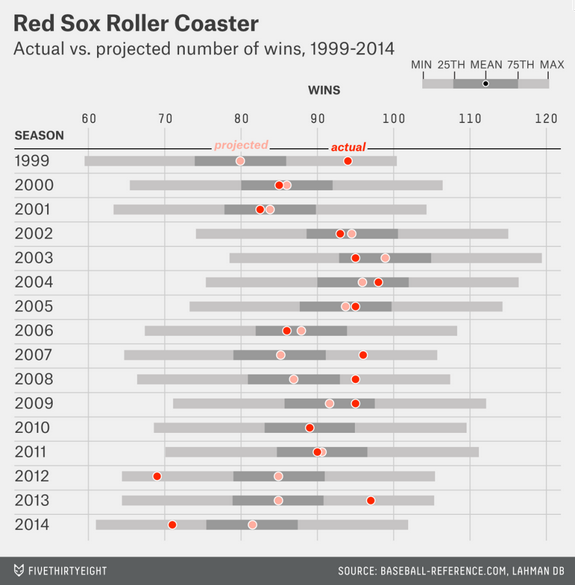
As Massachusetts and Maine celebrate Patriots’ Day, the Boston Red Sox are set to play their earliest game of the year with an 11.00 start time. (Yes, there is also a marathon today.) So after two weeks or twelve games, the question people want answered is what Red Sox do we get this year? FiveThirtyEight looked at what they called roller-coaster seasons of late, primarily using a box plot graphic to show just how much whiplash Boston fans have endured of late.
Projected vs. actual wins
So who are the Red Sox this year? The cellar dwellers of 2012 and 2014? Or world champions like in 2013? Who knows?
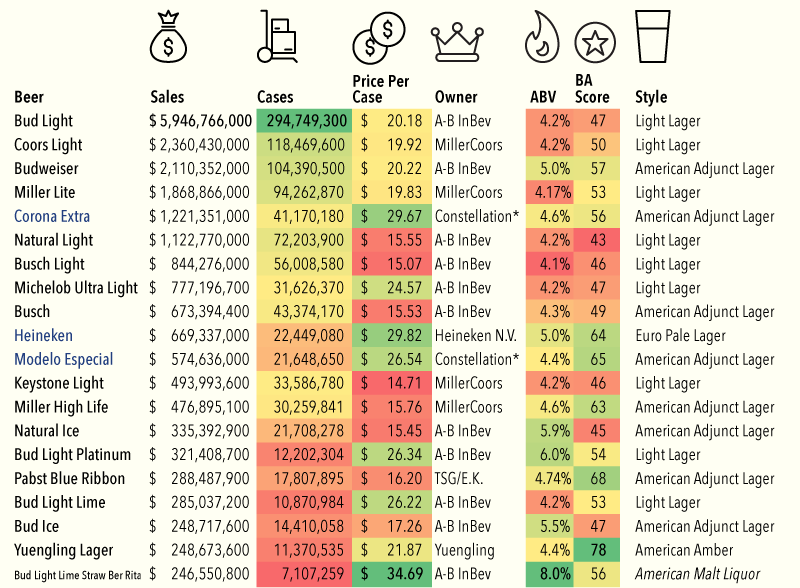
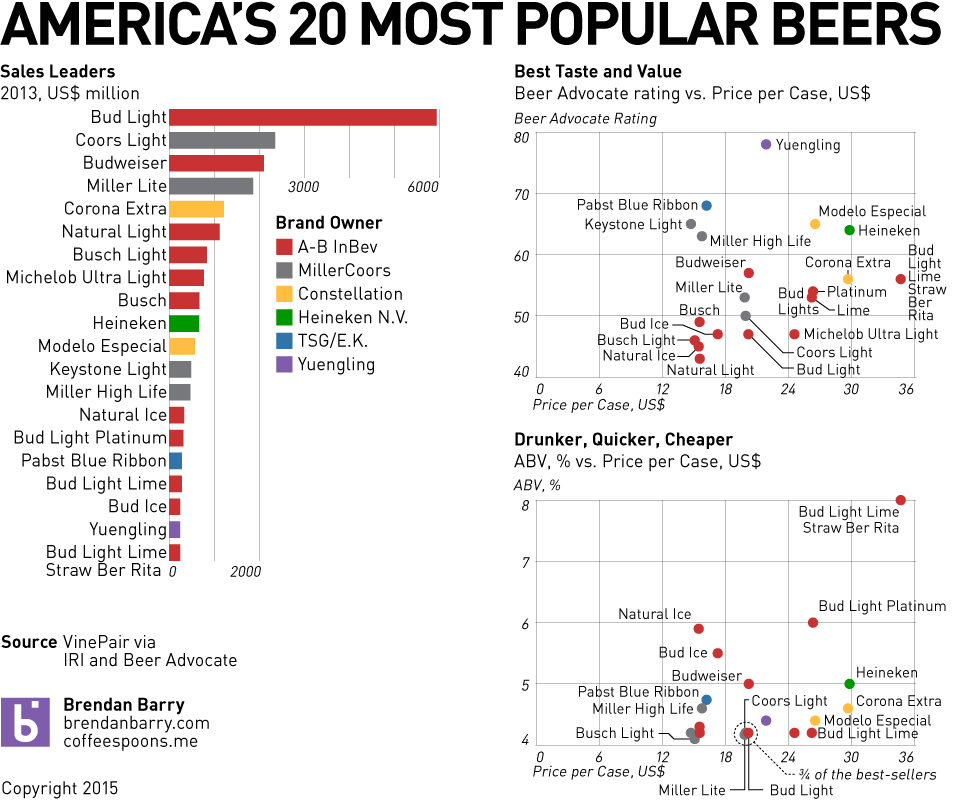
Or so says Adweek. I would heartily disagree about their inclusion of Yuengling in their group of crappy. Though the other nineteen, yeah, I would tend to agree. Regardless, the infographic that sparked the Adweek post is quite blah. I do enjoy the illustrations of the bottles and labels, but the data visualisation below is weak.
The 20 best in table form
So because of Yuengling, I decided to take a quick stab at ways to improve it. My first finding in the data was that the different brands were assigned a Beer Advocate rating, and Yuengling rated the highest—though not terribly high overall. Still, unless you are looking to get drunk, it does offer a good taste/cost value among the consideration set.