Tag: immigration
-
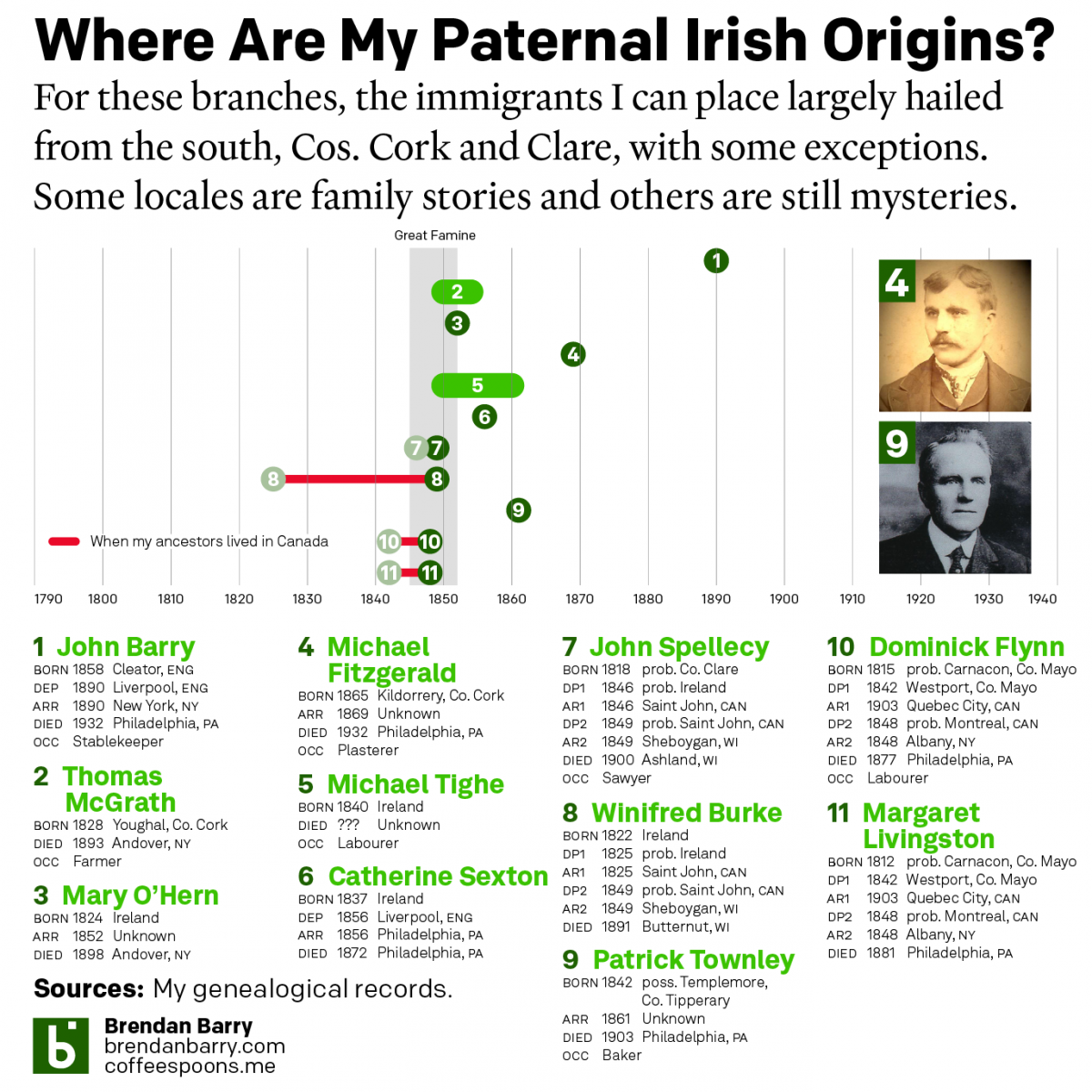
My Irishness
Yesterday was Saint Patrick’s Day and those who have followed me at Coffeespoons—or more generally know me—are well aware that my background is predominantly Irish. Those same people probably also know of my keen interest in genealogy. And that’s what today’s post is all about. Irish genealogy is difficult because of the lack of records…
-
Changes to Immigration Enforcement
Almost two weeks ago I read a piece in City Lab that used three maps to look at the changes to immigration enforcement in the first year of the Trump administration. I was taken by this final map in particular. While the map does have some large areas of N/A, it still does show some…
-
Immigrations Impact on Economic Growth
Initially I was not going to post this work, if only because other things came up and I do have to prioritise what I post on my site. It had nothing to do with the work’s quality, which I think is actually quite good. What am I talking about? Well today’s piece is from a…
-
Trump’s Wall
Another day, another story about the administration to cover with data-driven graphics. We are approaching Trump’s 100th day in office, traditionally the first point at which we examine the impact of the new president. And well, beyond appointing a Supreme Court justice, it is hard to find a lot of things President Trump has actually…
-
Undocumented Irish Immigrants
You know, I was trying to find a nice and funny graphic that related to the Irish for today since today is St. Patrick’s Day. But, I keep circling back to that piece I posted last year. Because, unfortunately, these are not terribly uplifting times. We make a great big deal about how we need…
-
Irish Immigration
Illegal immigration is one of the big topics in the American presidential election. Some of us want to build a wall to keep out illegal Mexican immigrants. Today’s graphic is a number. Illegal immigrants are not limited to Latin America, but they come even from places like Ireland looking for a better life. The number is…