Tag: interactive design
-
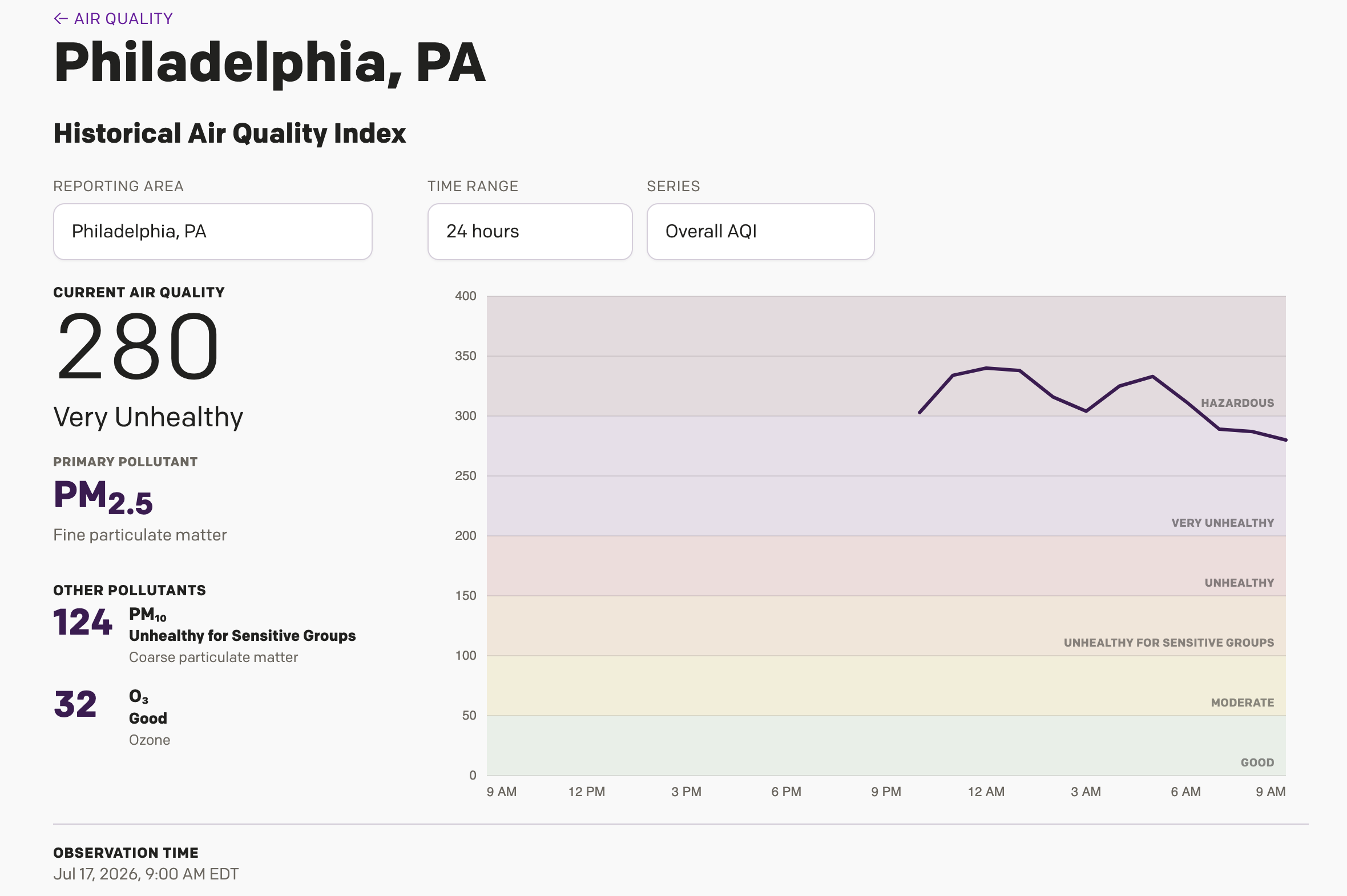
Is It Always Smoky in Philadelphia?
Yesterday I wrote about a Philadelphia Inquirer article, which included an interactive display showing different monitoring stations around the Philadelphia area cataloguing just how bad the Minnesota/Canadian wildfire smoke is in the region. I noted during my piece that it was unclear if the little bars were actually recording the AQI values or just a…
-
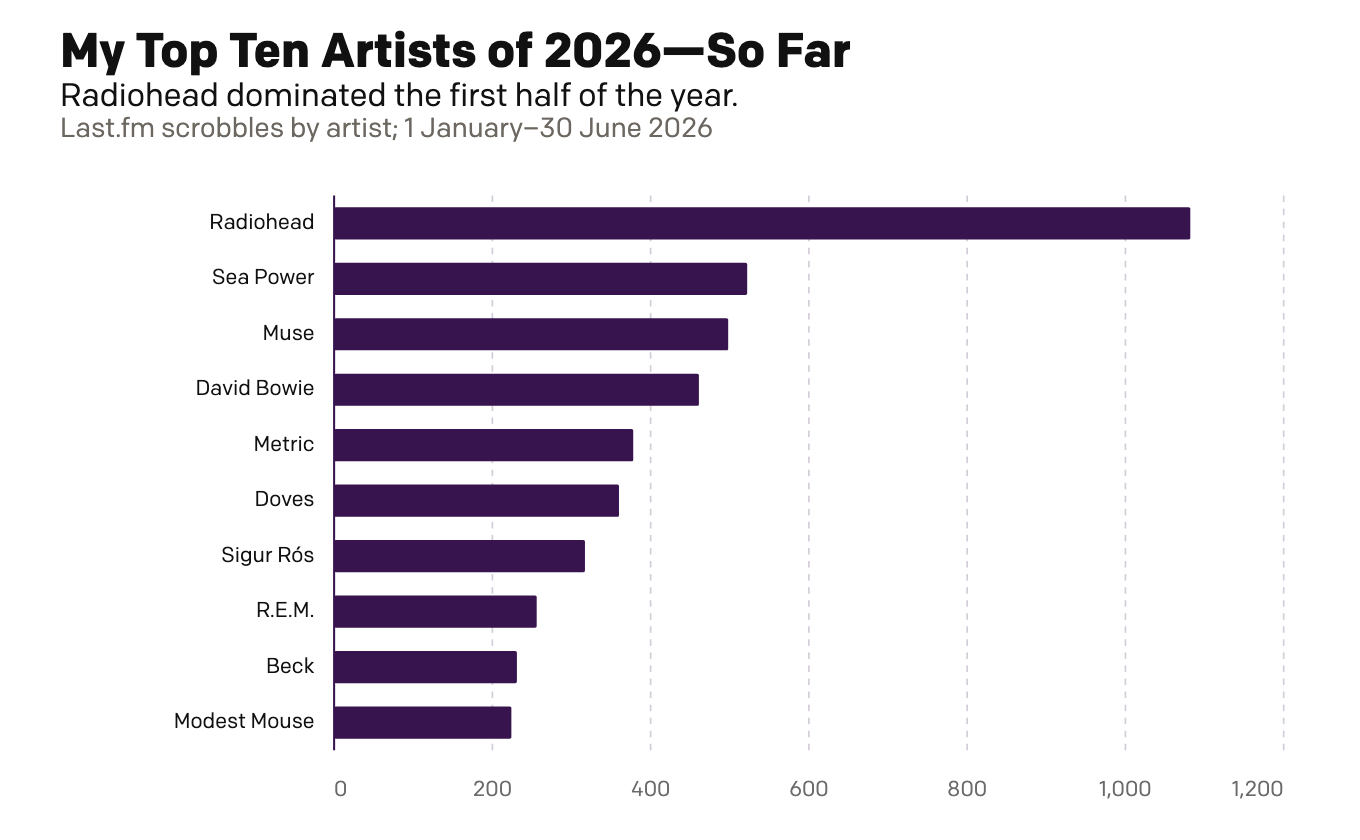
My First Half of Music (Streams)
Because I am headed out of town for several days, today is basically this week’s Friday post—just for fun. Last week I looked at my musical tastes via the vinyl. Today I look at the digital streams of music. This is far less surprising and arguably more representative of my tastes more broadly. Unlike records,…
-
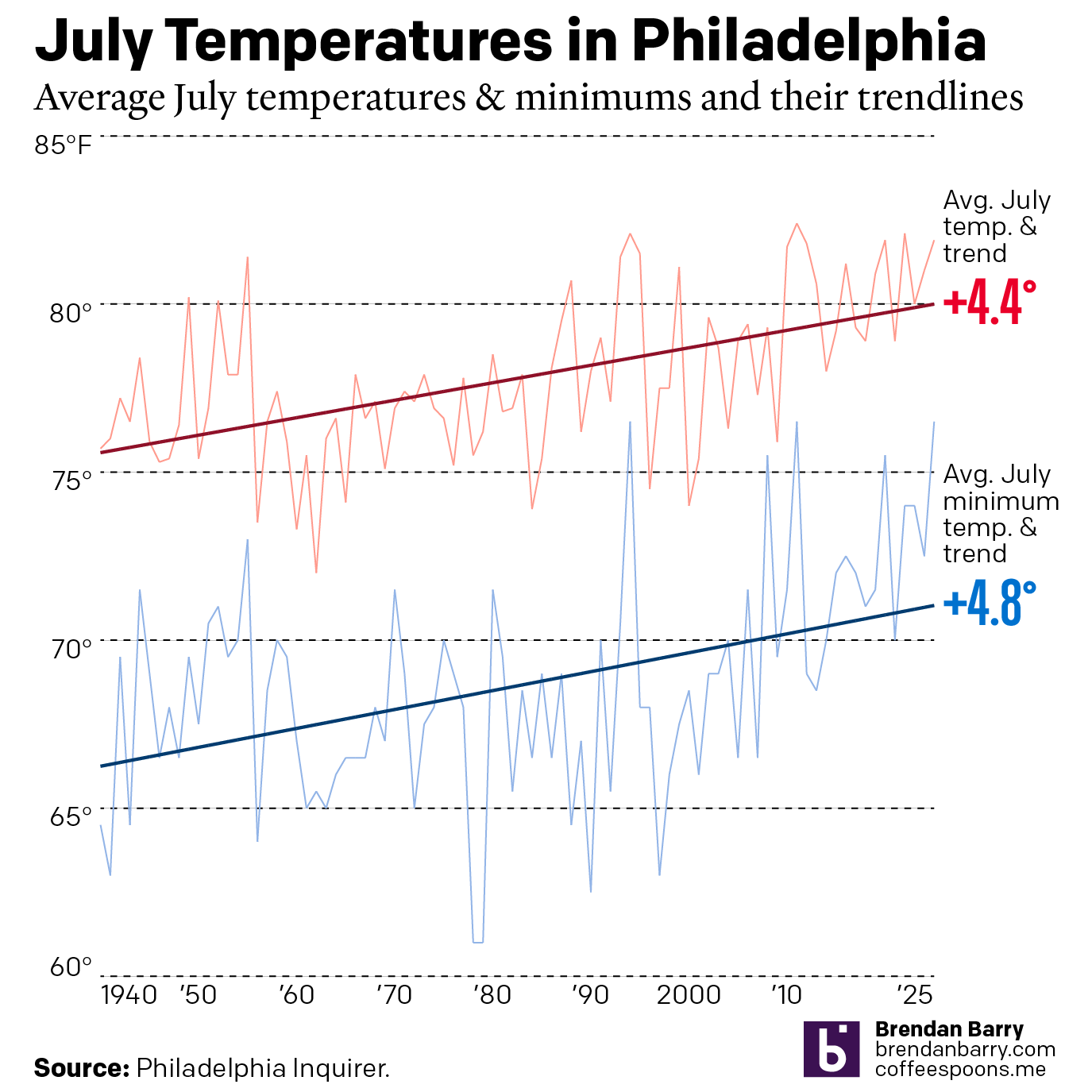
Just a Wee Bit Warm
This past weekend was a hot one in Philadelphia (and many other places across the eastern United States). As we enter July, the Philadelphia Inquirer published an article examining climate change’s impact on summer temperatures. Spoiler: it’s hotter. The article included two interactive line charts. The first one plotted the average high temperature of July…
-
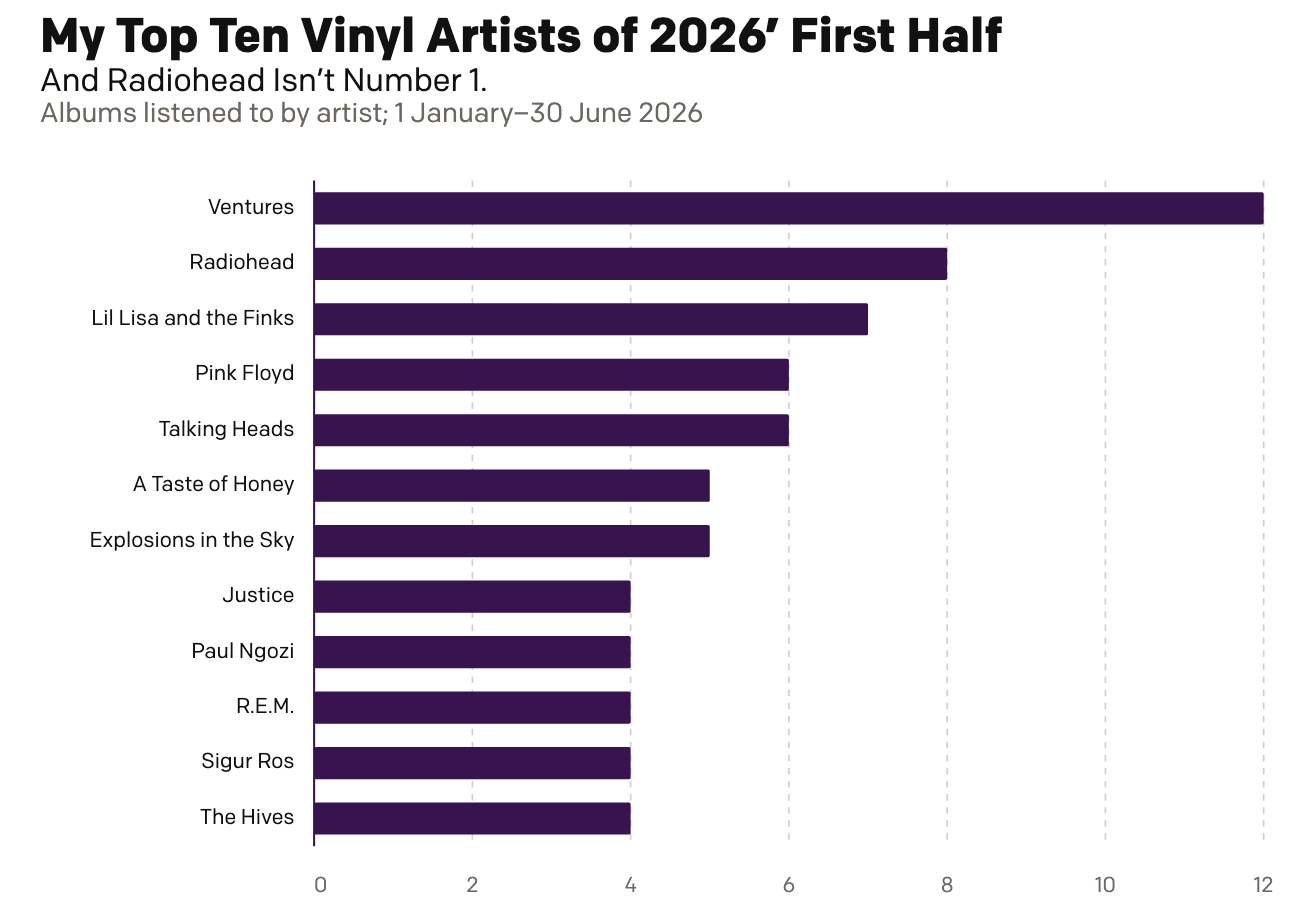
My First Half of Music (Records)
Two Christmases ago, my mother gifted me a record player. Ever since I have been slowly buying records—and then listening to them. And over the last year I have been recording those record plays and with 2026 now half over, I decided to run the numbers and see where I am at. As context, my…
-
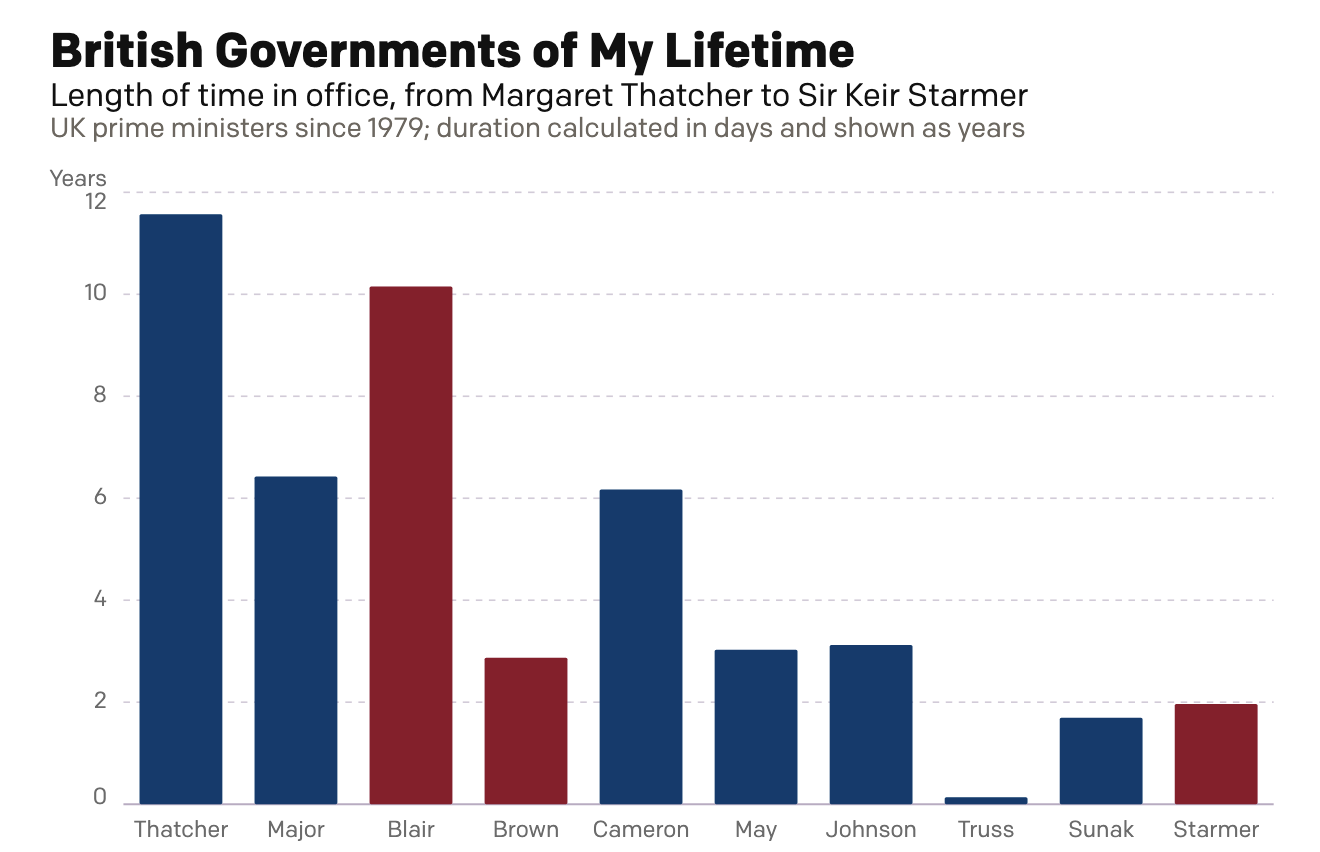
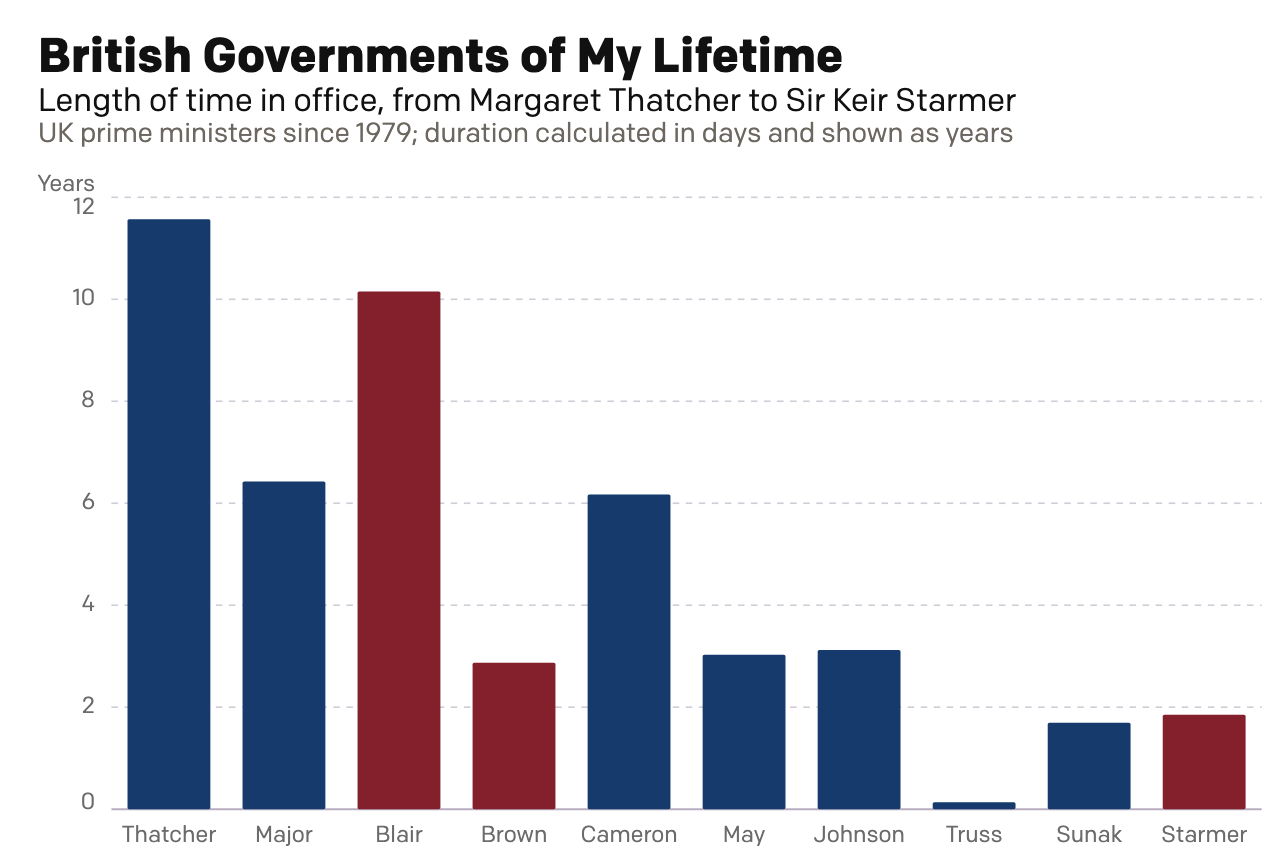
A Dan Miller Coronation?
Six weeks ago I created a small interactive chart on the news that Wes Streeting, the then British health secretary, resigned in order to challenge Prime Minister Sir Keir Starmer for the leadership of the Labour Party. Six weeks hence, Starmer has resigned. Lo and behold, my interactive graphic still works: British Governments of My…
-
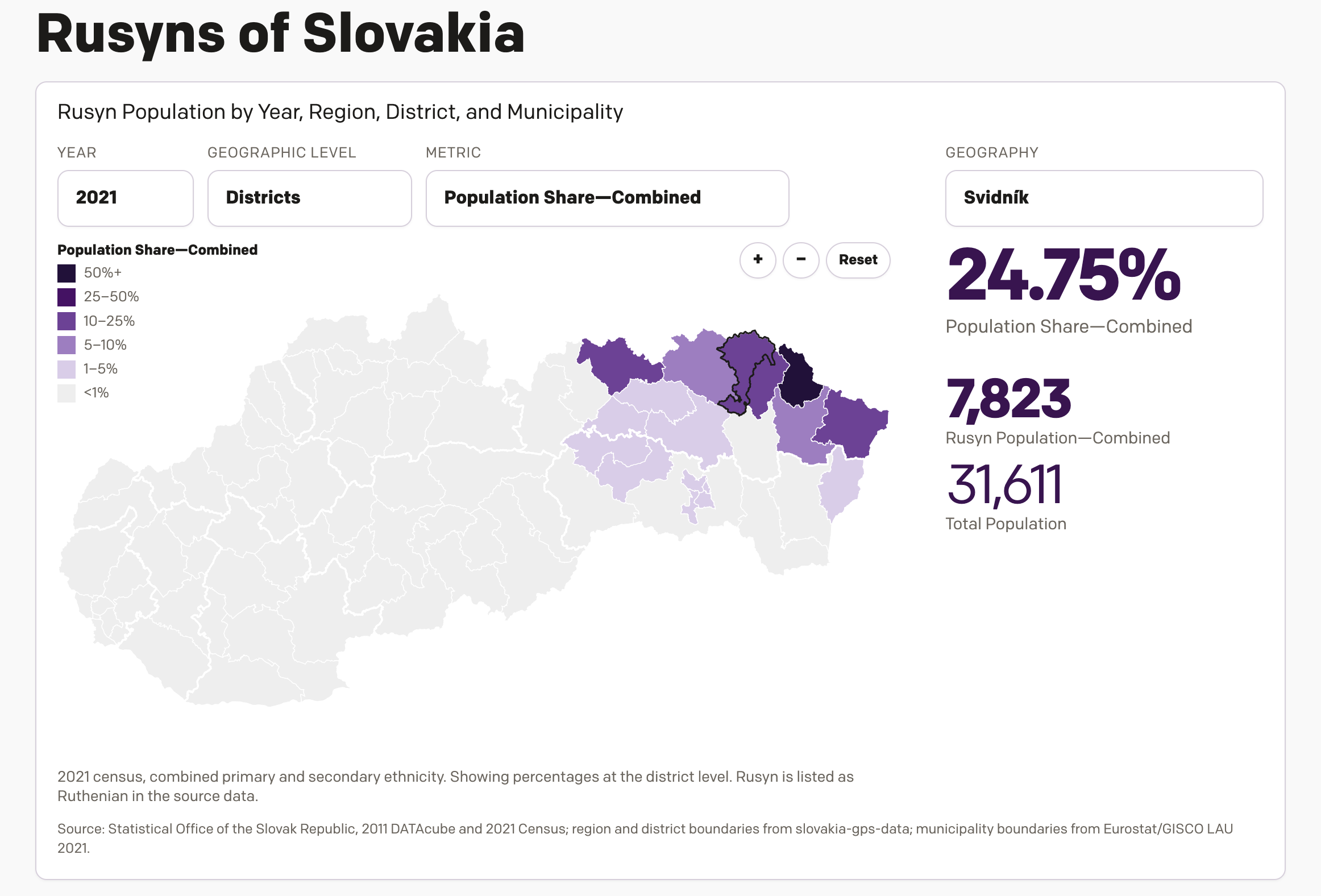
New(ish) Data for the Old Country
One of the most popular pieces of content on my website over the last several years has been a datagraphic I designed, which explores the Slovakian census data from 2011 on the Carpatho–Rusyns of Slovakia. I wrote about it for Coffeespoons back in 2012. The Carpatho–Rusyns, as they are known in the United States and…
-
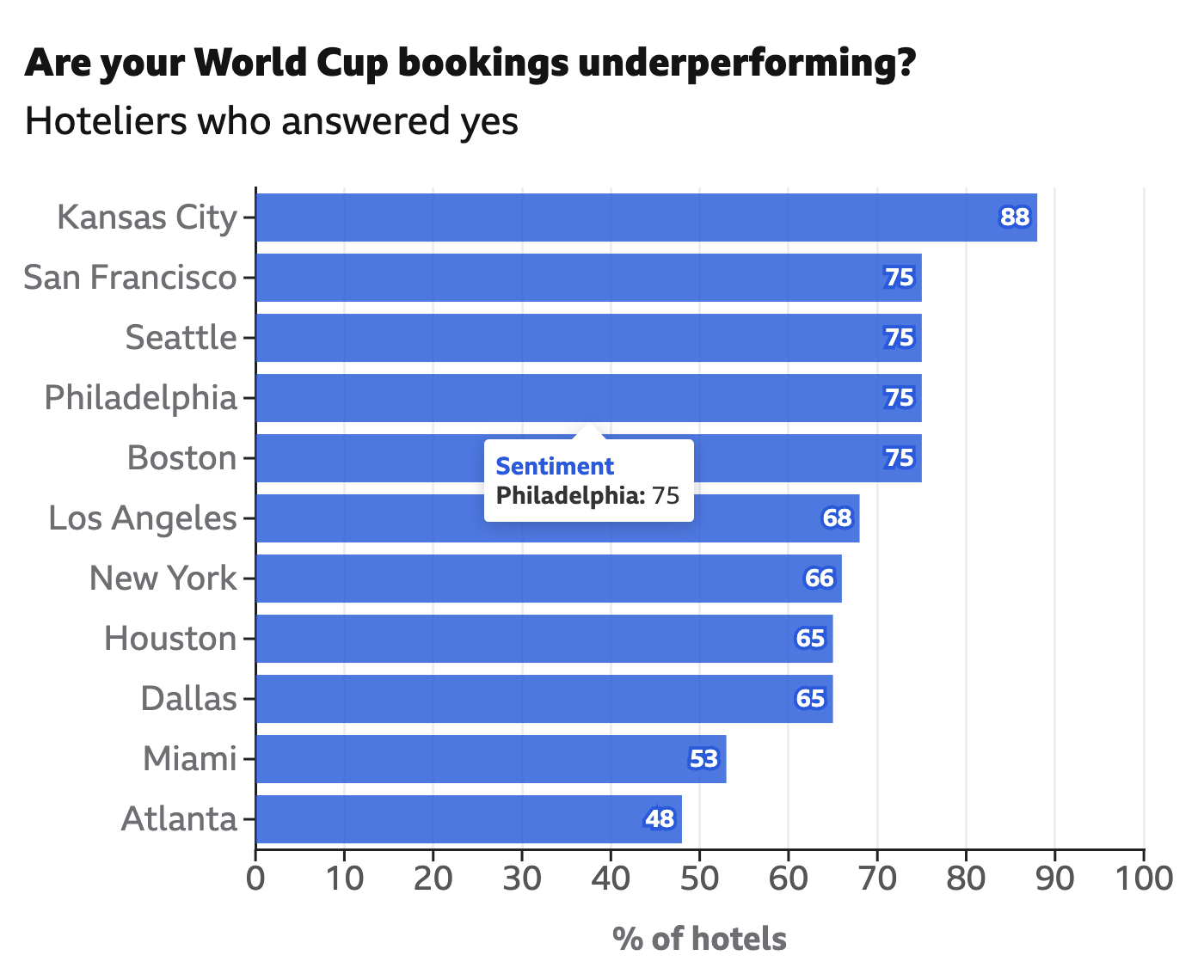
Unnecessary Extra Labelling
I frequently criticise labelling the data values on bar charts, a style seemingly everywhere on the internets. Labels provide precise values, but if you need to see the precise value in a graphic, you don’t really need the graphic—you need a table. Enter this interactive graphic in an article from the BBC exploring hotel bookings…
-
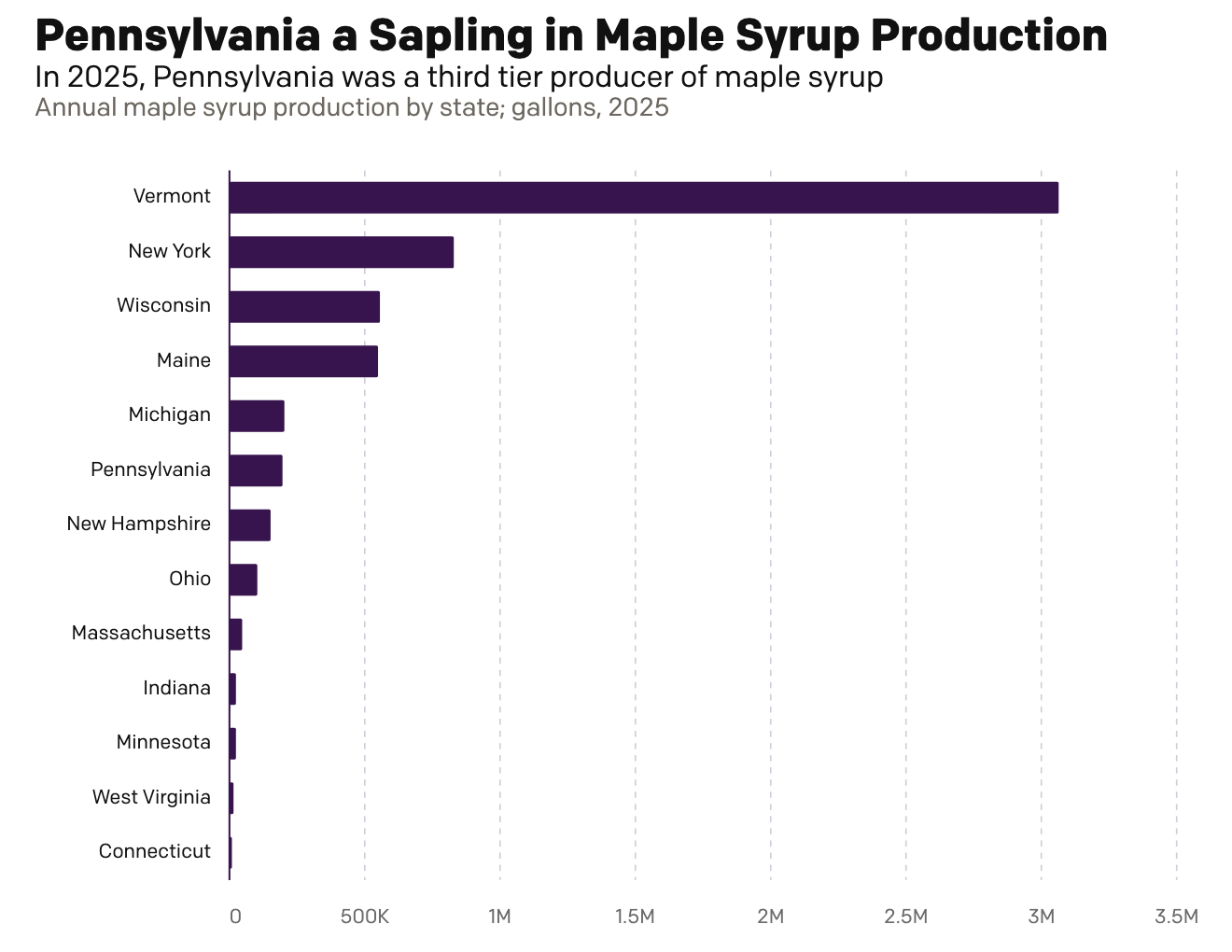
Maple Syrup Monday
This morning over breakfast I was reading an article in the Philadelphia Inquirer about Pennsylvania maple syrup production. My breakfast was oatmeal with maple syrup, cinnamon, and all space along with orange juice and a cup of tea. They talked about Pennsylvania’s production and compared it to Vermont’s, which made me want nothing more than…
-
Rise of the Nutters
For most of my life I have been interested in British politics. I can recall talking with my mates about Tony Blair’s Prime Minister’s Questions (PMQs) in high school and at university. During the Brexit debate, my American friends would frequently ask me just what was going on across the pond. Through that point in…