Tag: demographics
-
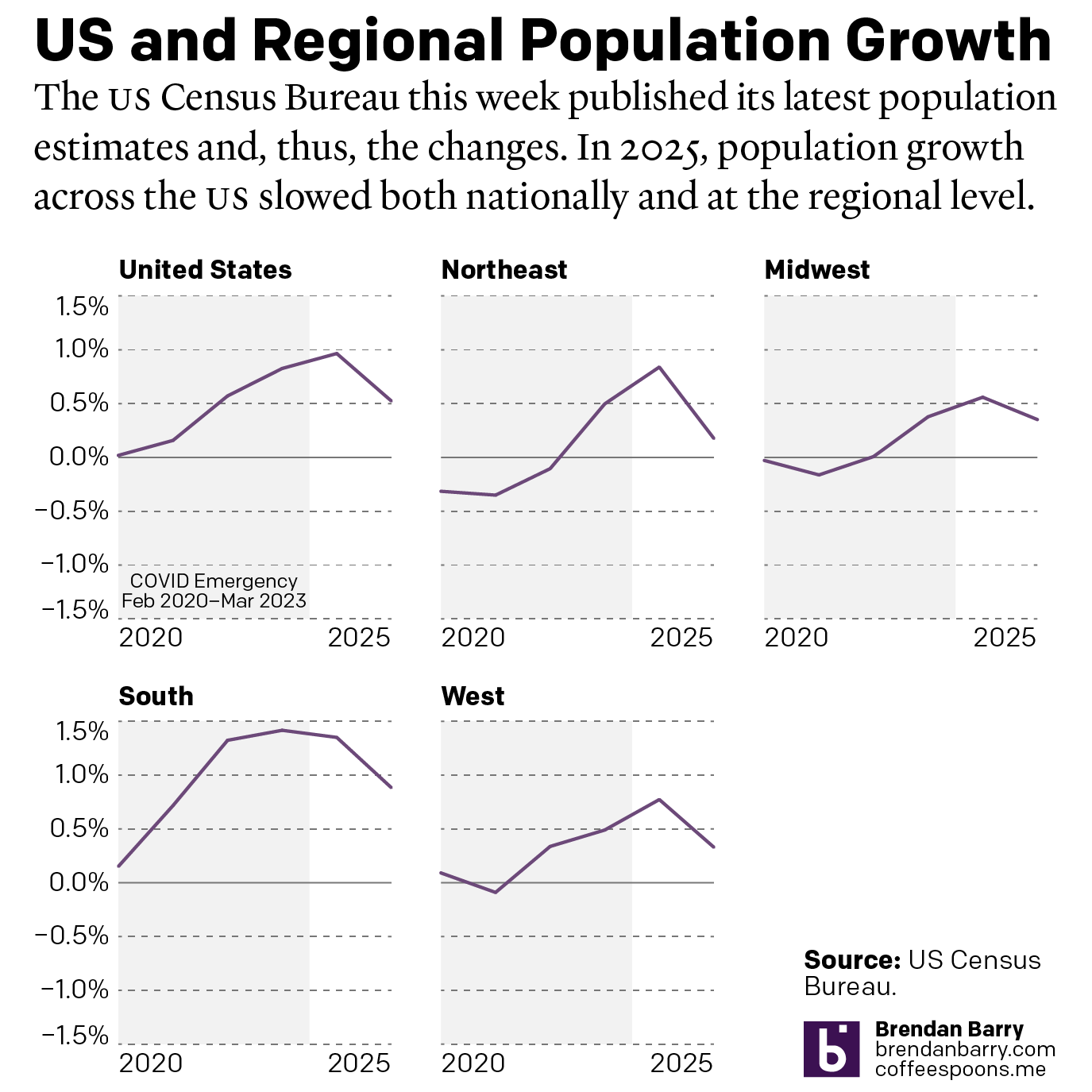
The Slowing of the Growth
This week the US Census Bureau released their population estimates for the most recent year and that includes the rate changes for the US, the Census Bureau defined regions, and the 50 states and Puerto Rico. I spent this morning digging into some of the data and whilst I will try to later to get…
-
2020 Census Apportionment
Every ten years the United States conducts a census of the entire population living within the United States. My genealogy self uses the federal census as the backbone of my research. But that’s not what it’s really there for. No, it exists to count the people to apportion representation at the federal level (among other…
-
Can We Pop Our Political Bubbles?
It’s no secret that Americans—and likely at least Western communities more broadly—live in bubbles, one of which being our political bubbles. And so I want to thank one of my mates for sending me the link to this opinion piece about political bubbles from the New York Times. The piece is fairly short, but begins…
-
Choropleths…Again
Admittedly, I was trying to find a data set for a piece, but couldn’t find one. So instead for today’s post I’ll turn to something that’s been sitting in my bookmarks for a little while now. It’s a choropleth map from the US Census Bureau looking at population change between the censuses. The reason I…
-
Another Look at 500,000
Yesterday we looked at how the New York Times covered the deaths of 500,000 Americans due to Covid-19. But I also read another article, this by the BBC, that attempted to capture the scale of the tragedy. Instead of looking at the deaths in a timeline, the BBC approached it from a cumulative impact, i.e.…