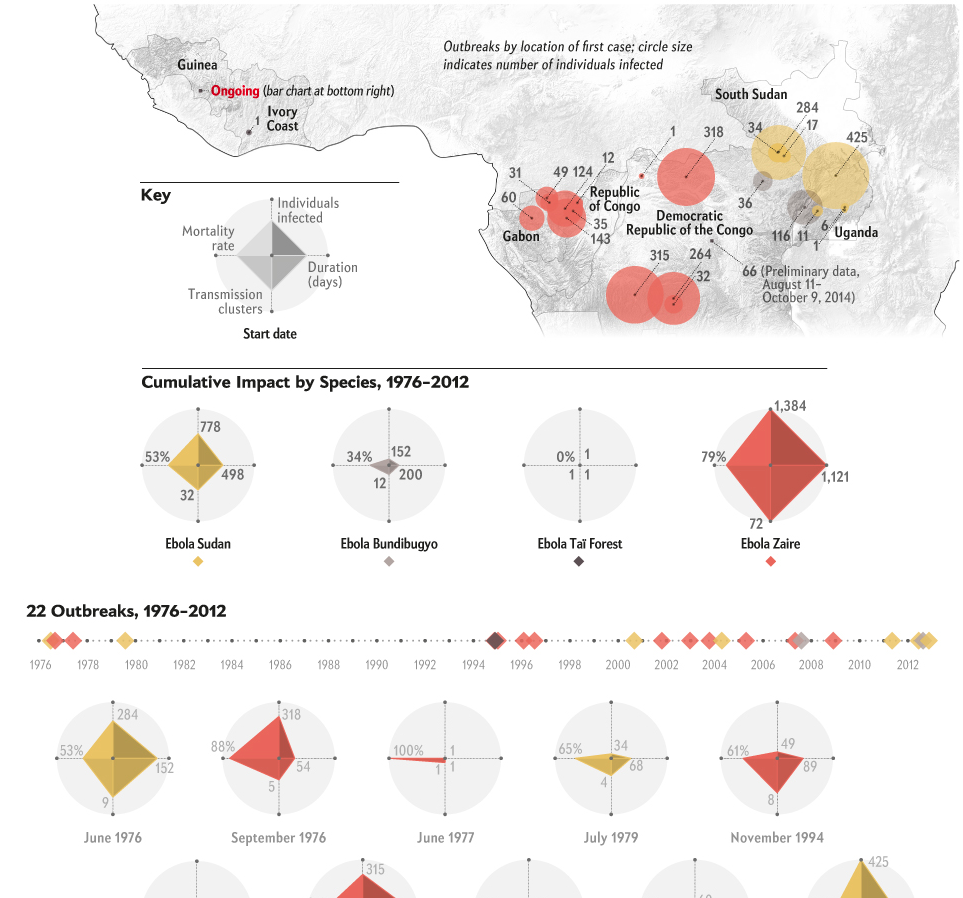
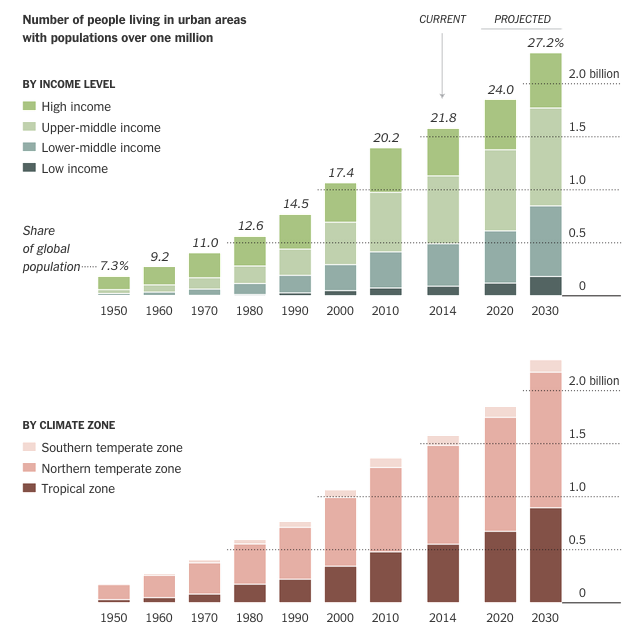
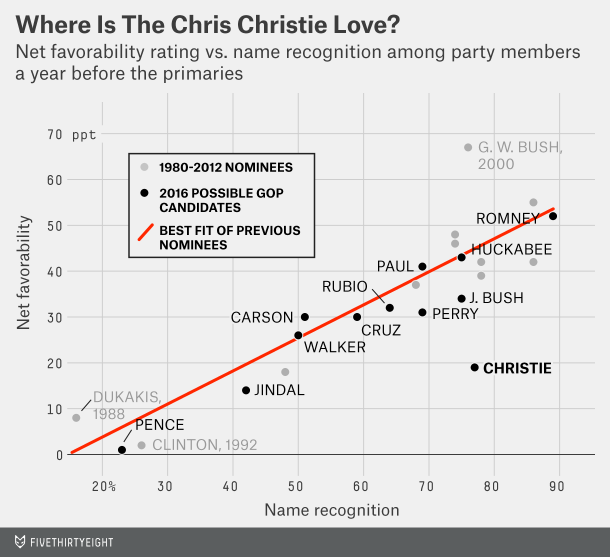
Readers of this blog know that I am a fan of rail travel. And in particular, how the rail system on the East Coast is brilliant when compared to anywhere else in the States. Unfortunately, the railway system on the East Coast is also old and in need of serious capital investment. The tunnels linking New York and New Jersey beneath the Hudson River are a prime example. But a few years ago, Governor Christie of New Jersey killed Amtrak’s plans to build new tunnels to provide a backup to the existing infrastructure and increase overall capacity. The Wall Street Journal takes a look at Amtrak’s new plan to cross the Hudson. Let’s hope this venture is a bit more successful.
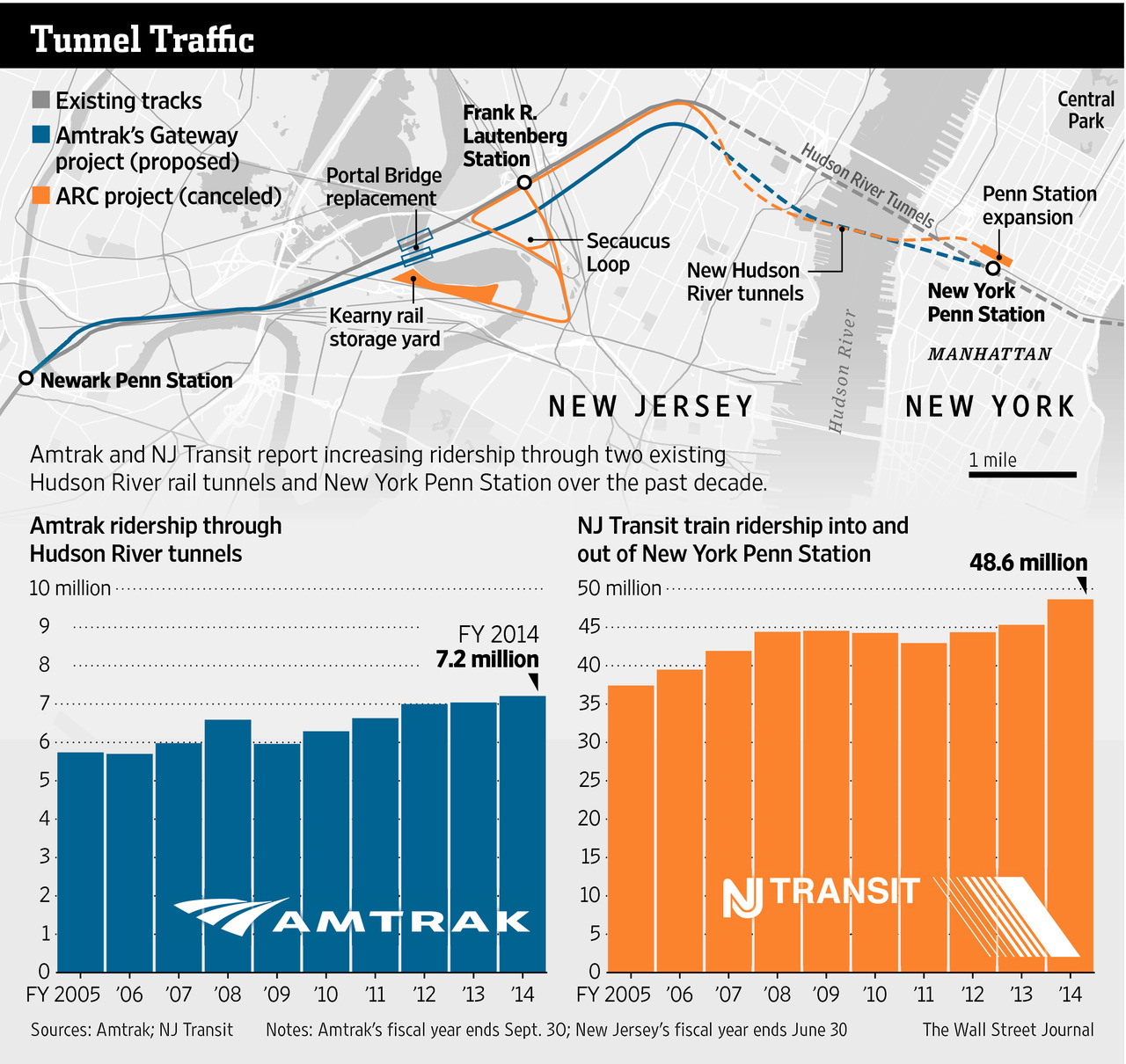
Credit for the piece goes to the Wall Street Journal graphics department.