Tag: table
-

The Long, Winding Road
At the beginning of the week I wrote about a table as a chart, for which I designed a light-duty interactive bar chart. Tables can be great, when used well, but they are not ideal for showing trends in data—hence the term data visualisation. But today is now Friday and we made it to the…
-
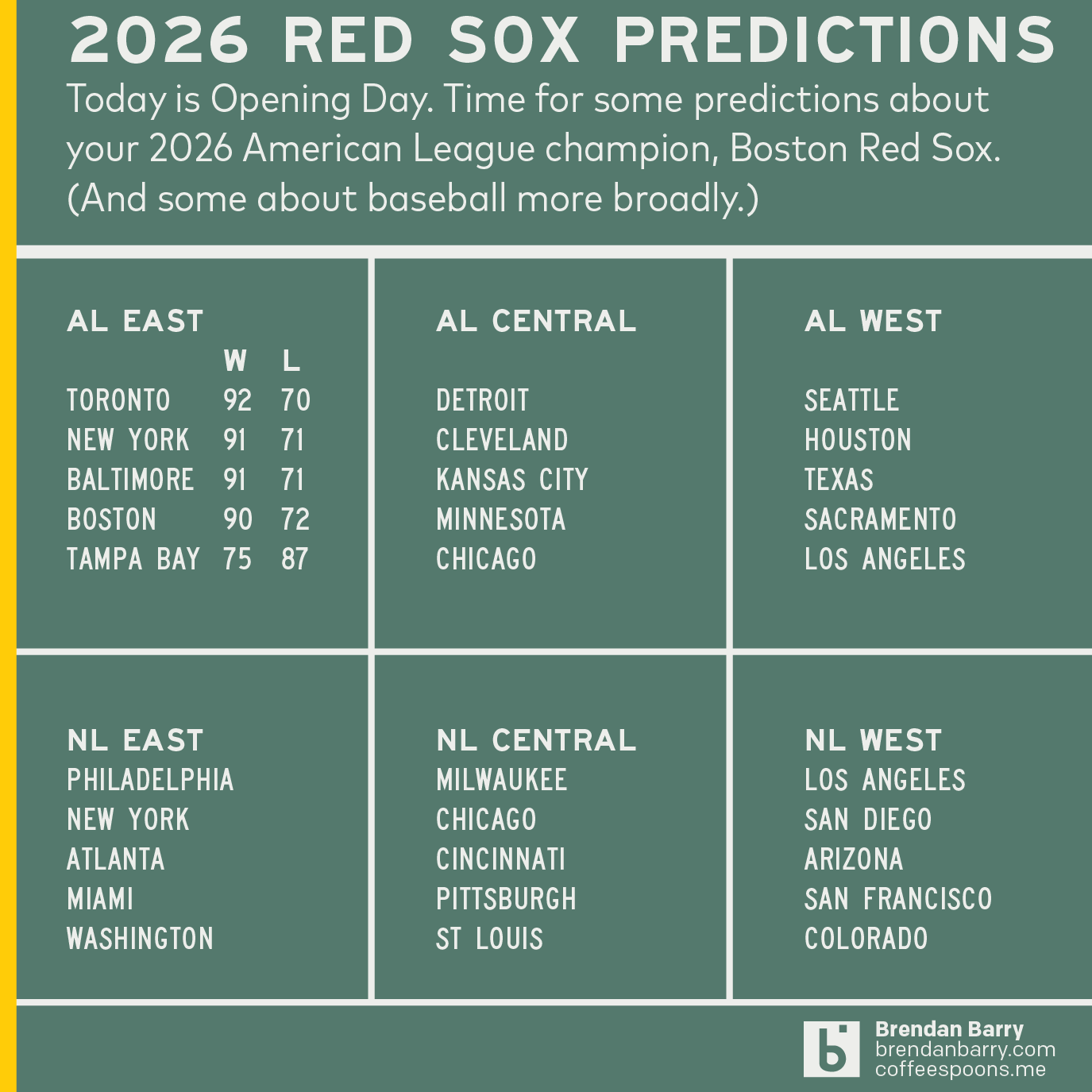
Opening Day
Happy Opening Day, everyone. Baseball is back. The Red Sox are back. Last year, I only posted my predictions on social media because they don’t include charts or graphs really. (But I did revisit them at year’s end.) These are mostly just tables. But, why not? Last year, shortly after Opening Day, I wrote about…
-
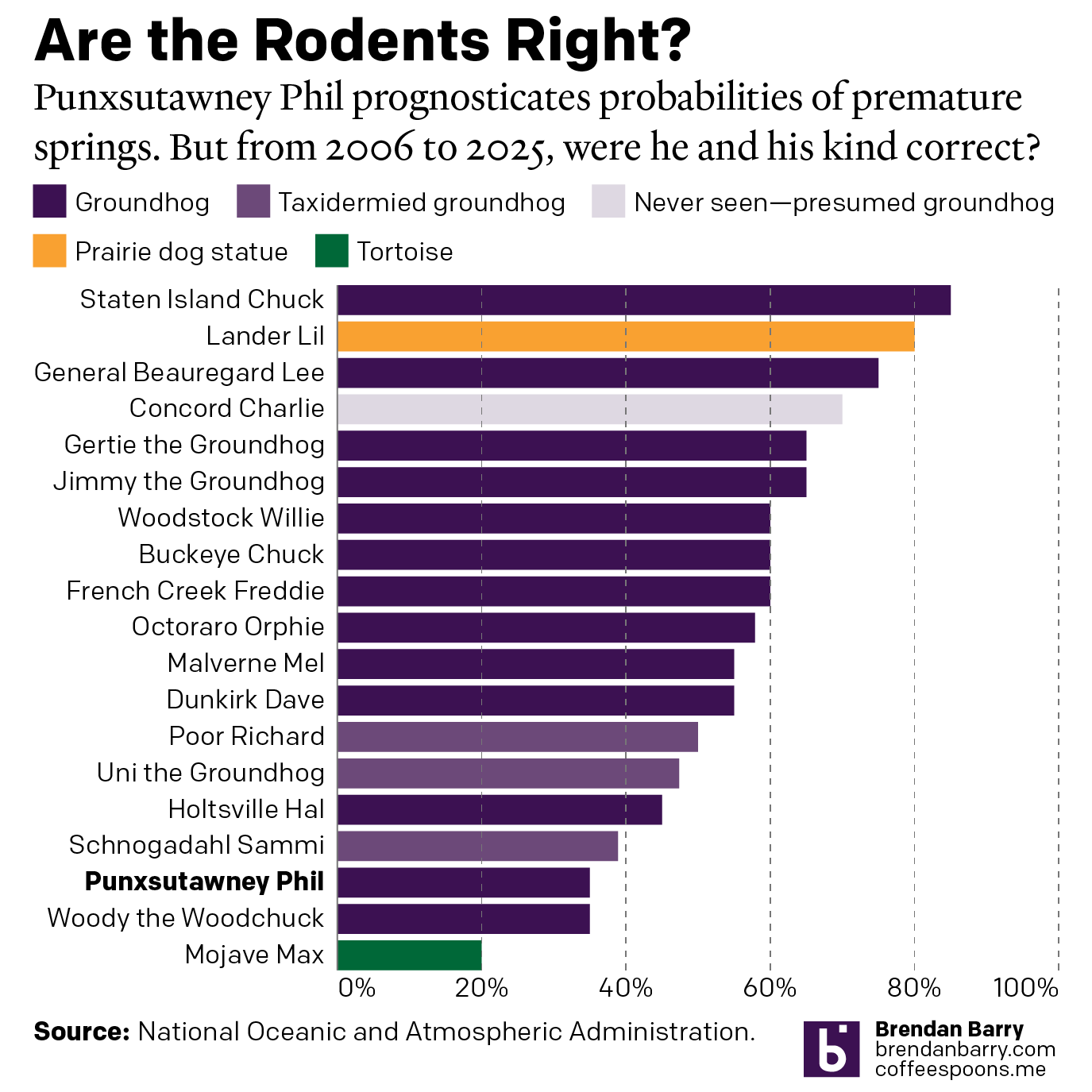
Do We Do This Every Year?
Every year on Groundhog’s Day I feel as if more and more critters crawl up from the Earth to offer their portents of prolonged winter. And every year we look backwards with the fullness of meteorological observations to evaluate the accuracy of these armchair—armburrow?—forecasters. This year, the Philadelphia Inquirer’s required article on the matter included…
-
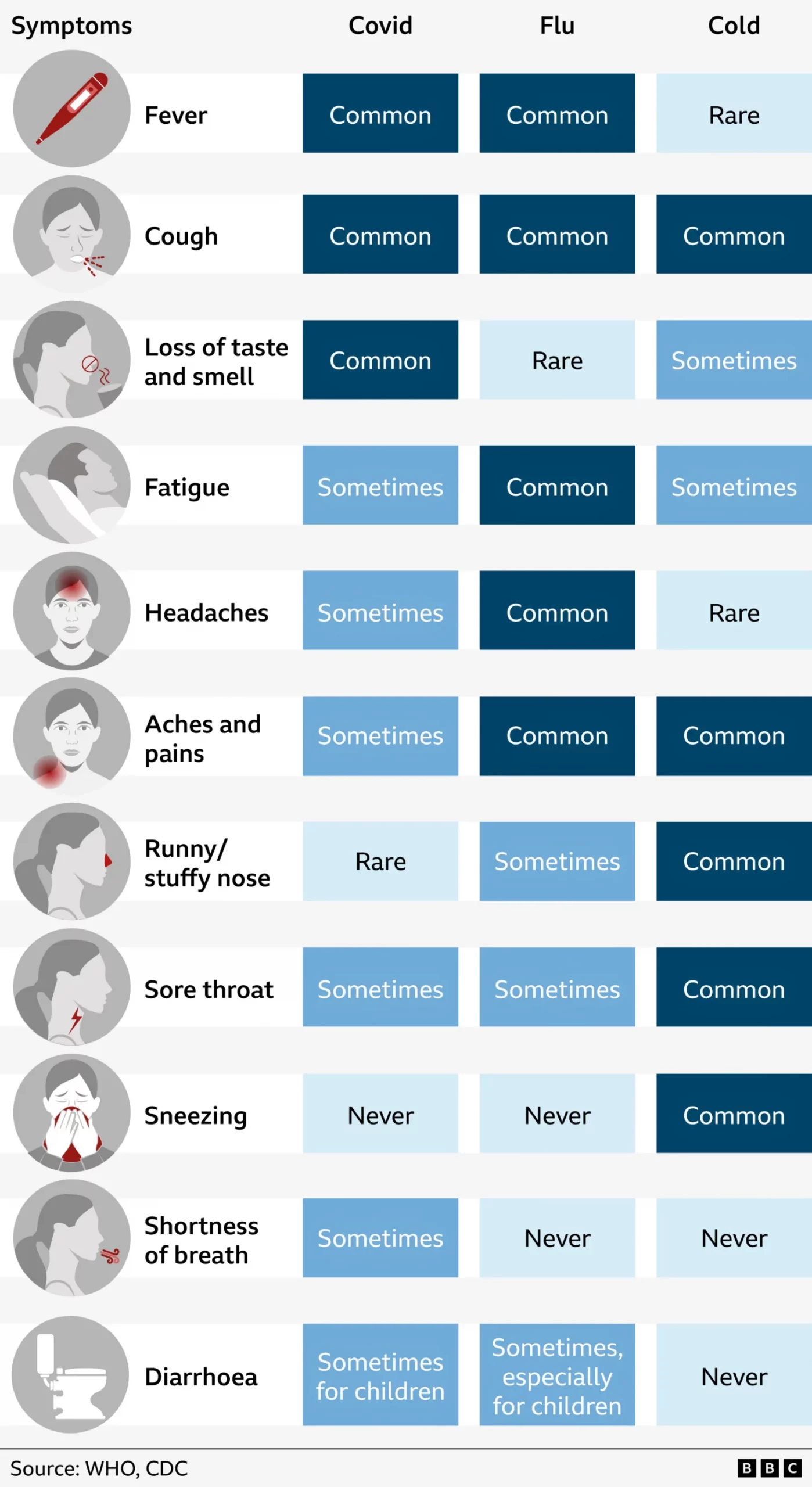
Aches, Fevers, and Chills, Oh My!
Last week I suffered from the aforetitled and wondered what just might be ailing me. My sore throat woke me up in the middle of the night with intense, sharp pain and reminded me of stories I had read earlier this flu season about “razor blade” sore throat associated with the latest COVID strain, Nimbus.…
-
The Observation Table
We made it to the end of yet another week. Before the weekend begins for most of my audience—though for my UK readers, enjoy the extended bank holiday and God save the Queen—I wanted to take a look at a graphic from xkcd that shows one can use different types of scopes to make different…
-
How Accurate Is Punxsutawney Phil?
For those unfamiliar with Groundhog Day—the event, not the film, because as it happens your author has never seen the film—since 1887 in the town of Punxsutawney, Pennsylvania (60 miles east-northeast of Pittsburgh) a groundhog named Phil has risen from his slumber, climbed out of his burrow, and went to see if he could see…
-
How the Globe’s Writers Voted
Yesterday we looked at a piece by the Boston Globe that mapped out all of David Ortiz’s home runs. We did that because he has just been voted into baseball’s Hall of Fame. But to be voted in means there must be votes and a few weeks after the deadline, the Globe posted an article…
-
What’s in a Corporate Name?
Last Thursday I wrote about the Wagner Group, an off-the-books semi-private army the Kremlin uses wage war where plausible deniability is desired. During that piece I mentioned Blackwater, one of the more infamous American private security contractor firms. The day before I had seen a tweet, this tweet, where Samantha Stokes created a matrix to…
-
2020 Census Apportionment
Every ten years the United States conducts a census of the entire population living within the United States. My genealogy self uses the federal census as the backbone of my research. But that’s not what it’s really there for. No, it exists to count the people to apportion representation at the federal level (among other…