
Happy Friday. Credit for this goes to Randall Munroe, who helps you understand how often things happen.
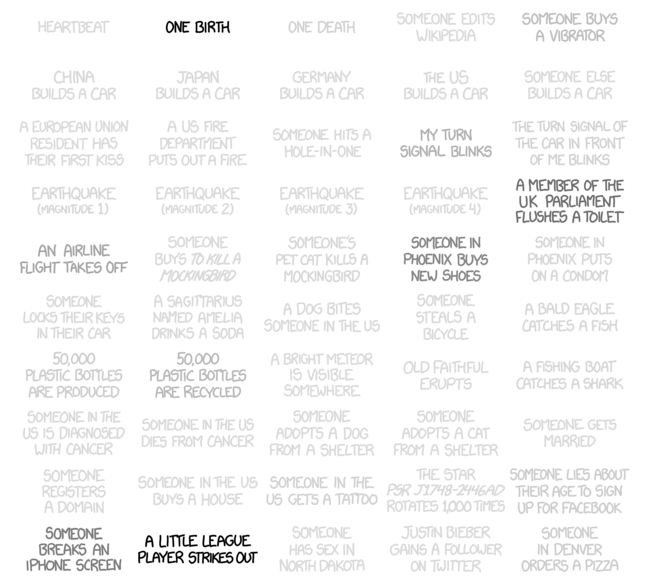
Happy Friday. Credit for this goes to Randall Munroe, who helps you understand how often things happen.
Sometimes when you are considering moving, you want to look at some broad statistics on the area in which you want to move. In Boston, the Boston Globe has put together a neat little application that does just that. Type in two settlements in the metro area and then get a quick comparison of the two.
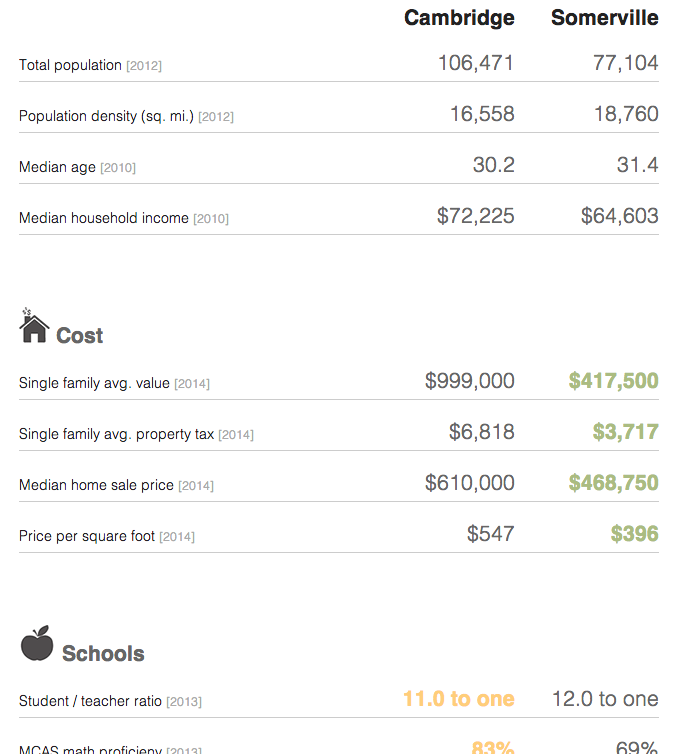
Credit for the piece goes to Catherine Cloutier, Andrew Tran, Russell Goldenberg, Corinne Winthrop.
President Obama has made a big deal recently about income inequality. The story in short is that the rich in the country are getting rich; the poor are getting poorer; and the people in the middle are fewer in number. Here in Chicago, this has meant that over the last few decades, many of the former middle-class neighbourhoods have been gutted of, well, the middle class. Daniel Kay Hertz has created a series of maps to show just how drastic the change has been since 1970.
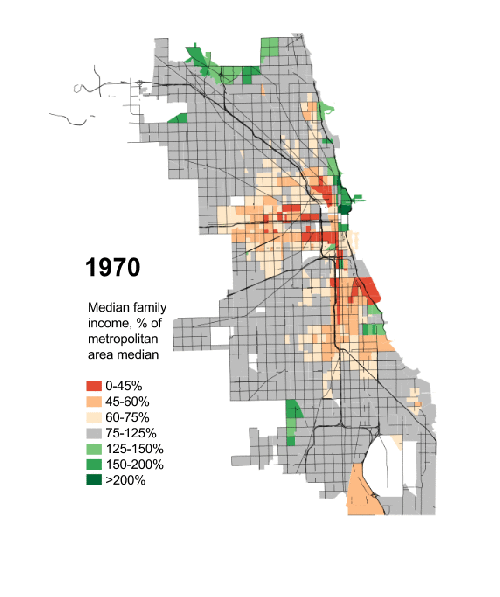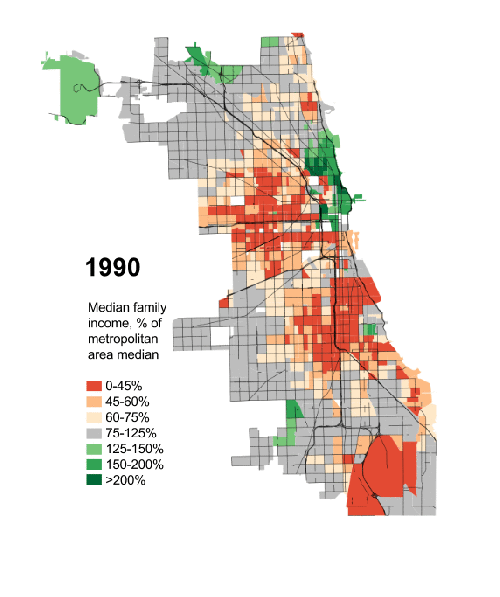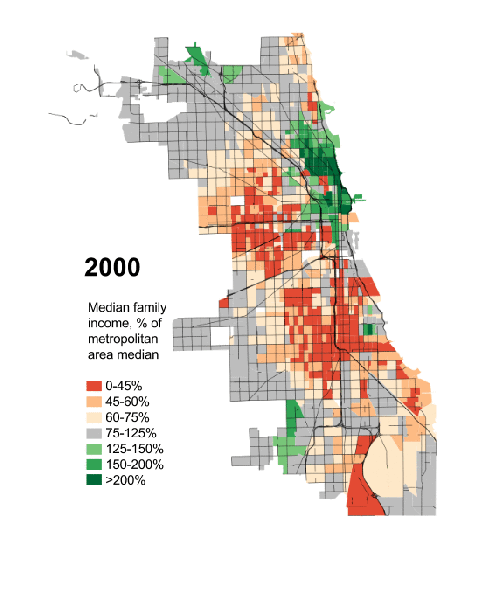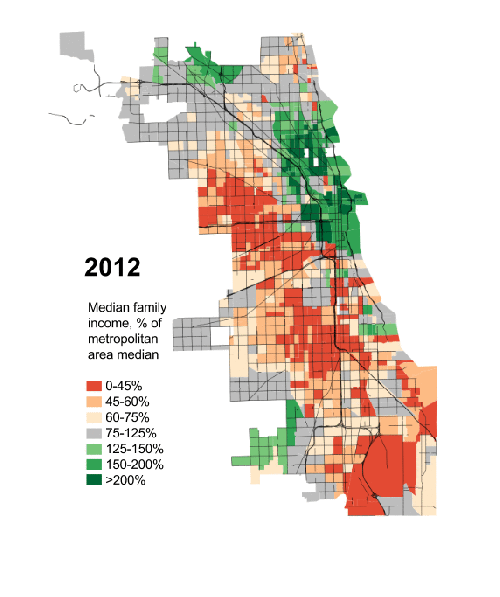
Credit for the piece goes to Daniel Kay Hertz.
Today’s piece does not involve any particularly crazy graphics or forms of data visualisation. Instead, the piece is a novel way of telling a story. People are increasingly familiar with what we might call here scrolling stories. Scroll down the page and suddenly you have glossy photos or high-definition videos. The New York Times, however, has taken this idea in a different direction for a story about motorcycle helmet laws.
Instead of glossy photos, we have clear and concise charts. Instead of lots of text blocks, we have just a few sentences. The story is told by the charts and the text offers the necessary context or background. Not all stories will have the data behind them to allow the story to be told—or shown—in such dramatic fashion. But, I can hope they do.
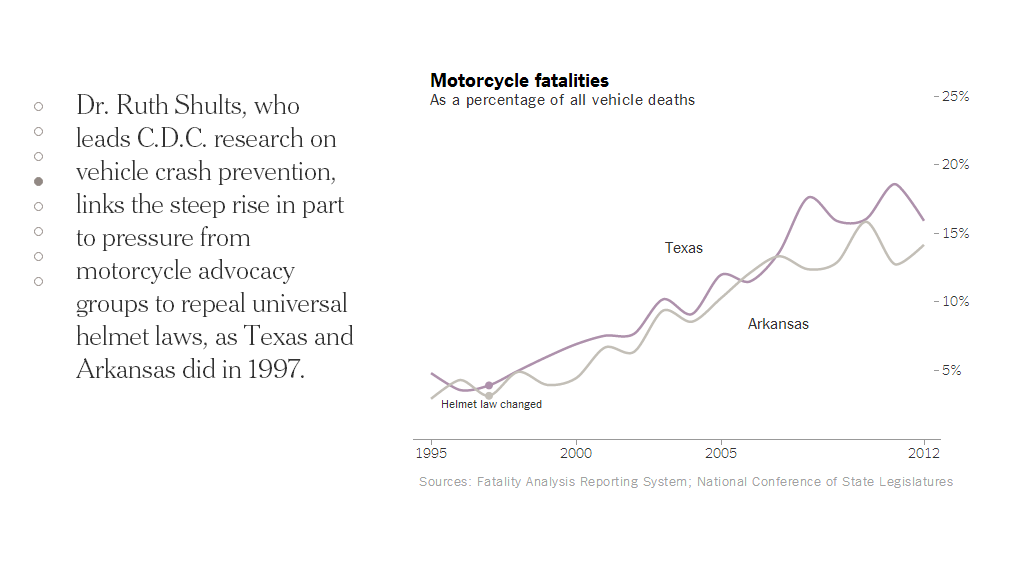
Credit for the piece goes to Alastair Dant and Hannah Fairfield.
Here’s a piece from the New York Times where I have to quibble with some minor design decisions. The story behind the graphic is various state actions on the minimum wage compared to where President Obama wants the minimum wage raised. This is a good story and broadly I like the execution. But these arrows, these arrows pierce my design heart. (Too much of a metaphor?) Instead, I think a simple dot plot would have sufficed. But as I noted above, this is more of a quibble than a shame-on-you.
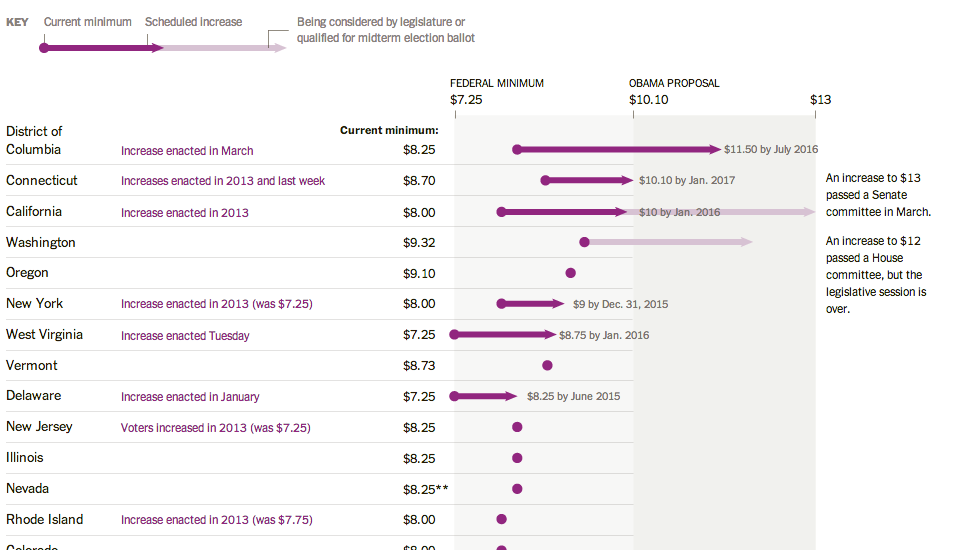
Credit for the piece goes to Alicia Parlapiano.
Today’s post is hosted on Brain Pickings. It’s diagrams made by Kurt Vonnegut that describe how basic plot lines work along two axes. There is a short video you can watch that goes over a few of them. But my favourite is, of course, not there. You have to read a bit further along to find it. Or just look below. But if you don’t read it, you’ll miss the written context.
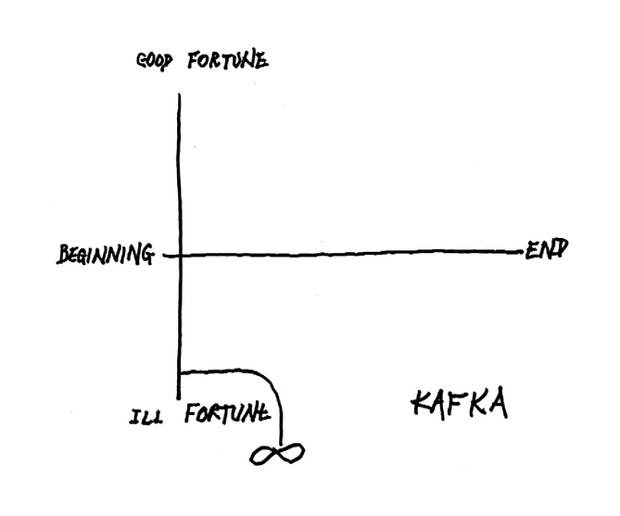
Credit for the piece goes to Kurt Vonnegut.
A little while back, the Economist posted an interesting slideshow piece that showcased the intricacies of London’s skyscraper problem and how many areas are restricted to preserve lines of sight. The user can click through each view and see just where on the map the view falls.
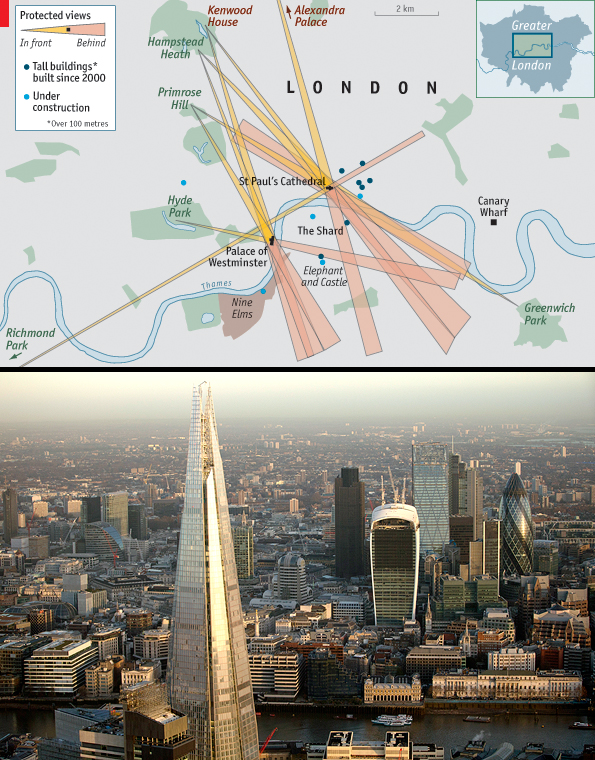
Credit for the piece goes to D.K., L.P., G.D., P.K. and R.L.J.
Last week Facebook acquired a company specialising in virtual reality. The Wall Street Post put together a timeline of technology company acquisitions over the last several years. Each line is a different company and sizes of dots represent the value of the different purchases.
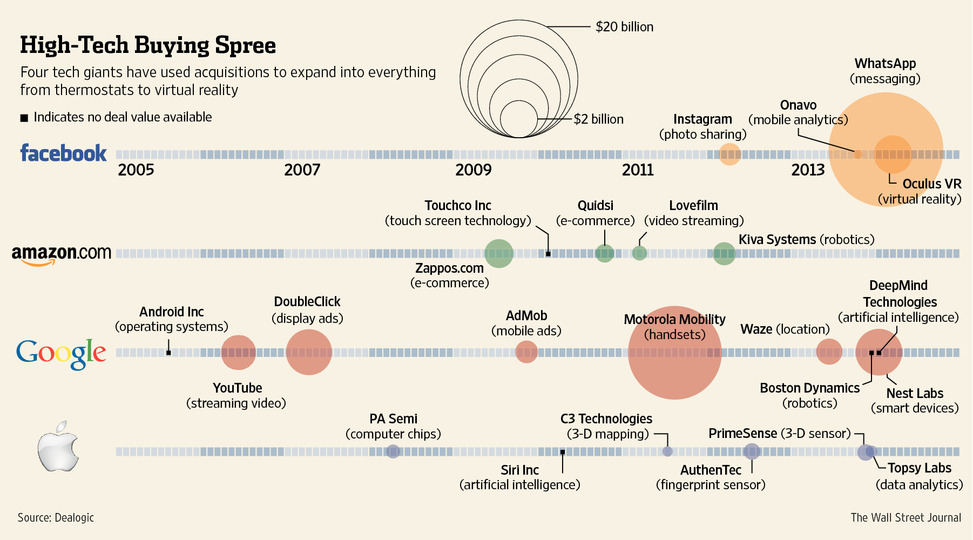
Credit for the piece goes to the Wall Street Journal’s graphics department.
The Crimean situation has highlight how much not just Ukraine is not ready to fight Russia, but also how much less Western Europe is prepared to fight. This piece from the Washington Post examines actual defence expenditure and then defence expenditure as a share of GDP. While Europe has remained steady or in decline, Russia has been ramping up its defence spending since the beginning of the 21st century.
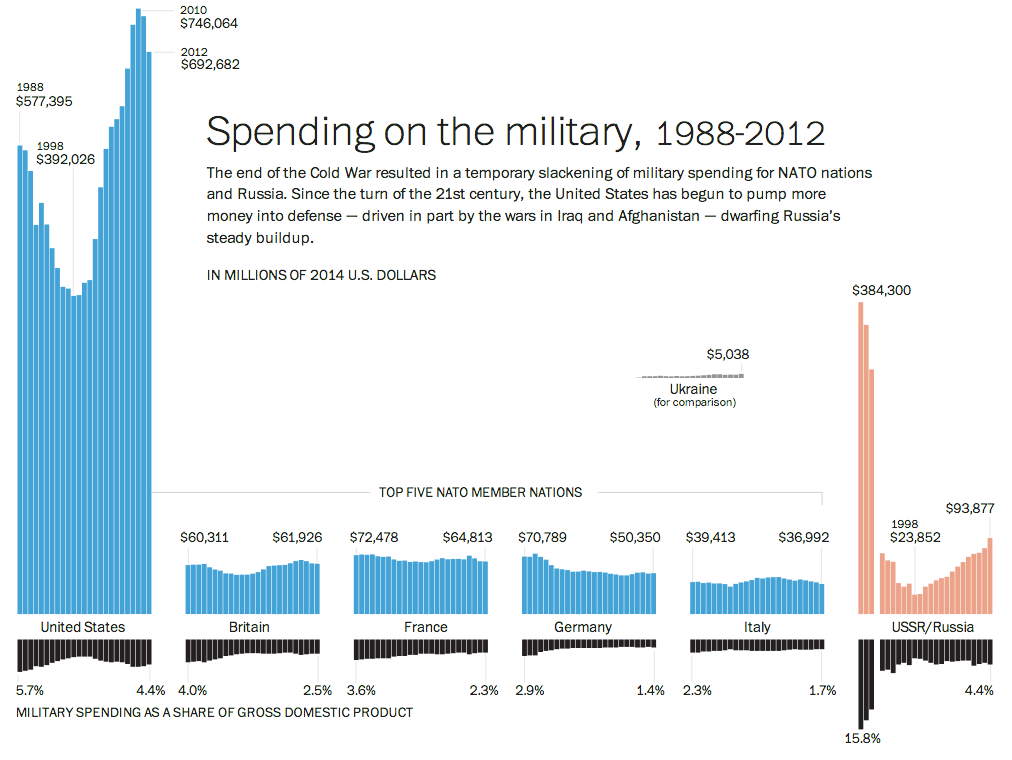
Credit for the pieces goes to Patterson Clark.
A few weeks ago, Bloomberg Businessweek published a nice graphic that summarised the last 25 years of oil spills. I’m finally getting around to posting it. But what it does really well is show just how bad the Deepwater Horizon spill was compared to the other big name disaster: Exxon Valdez. Of particular note is the bar chart at the bottom right comparing the millions of gallons of oil spilled.
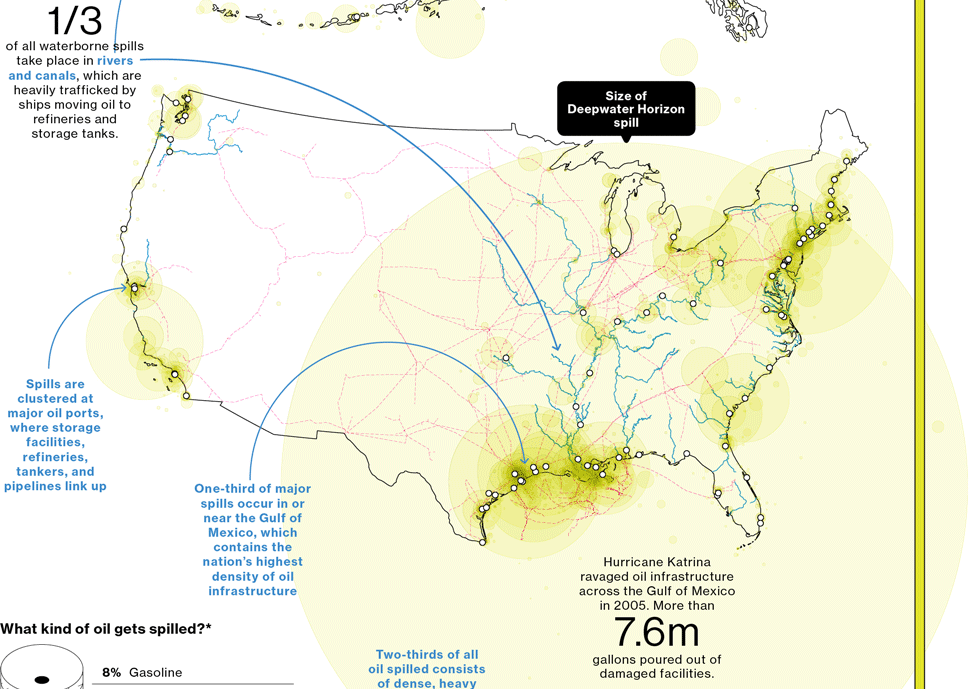
Credit for the piece goes to Evan Applegate.