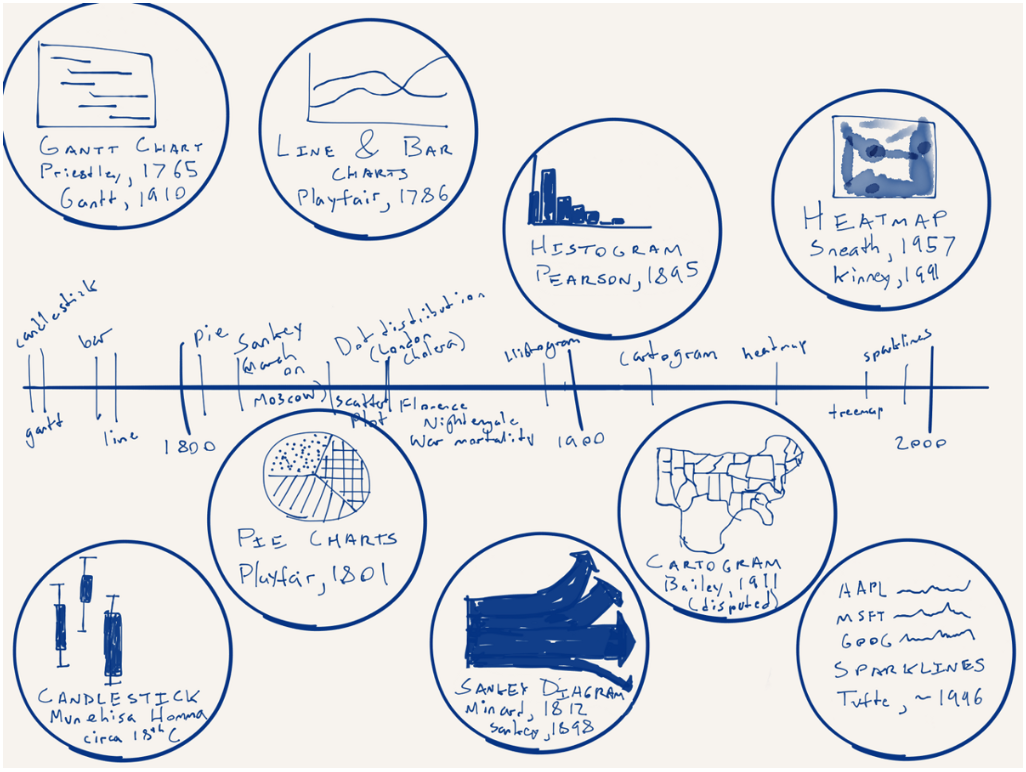
From time to time in my job I hear the desire or want for more different types of charts. But in this piece by Nick Brown over on Medium, we can see that there are really only a few key forms and some are already terrible—here’s looking at you, pie charts. How new are some of these forms? Turns out most are not that new—or very new depending on your history/timeline perspective. Brown illustrated that timeline by hand.
A timeline of chart forms
Worth the read is his thoughts on what is new for data visualisation and what might be next. No spoilers.
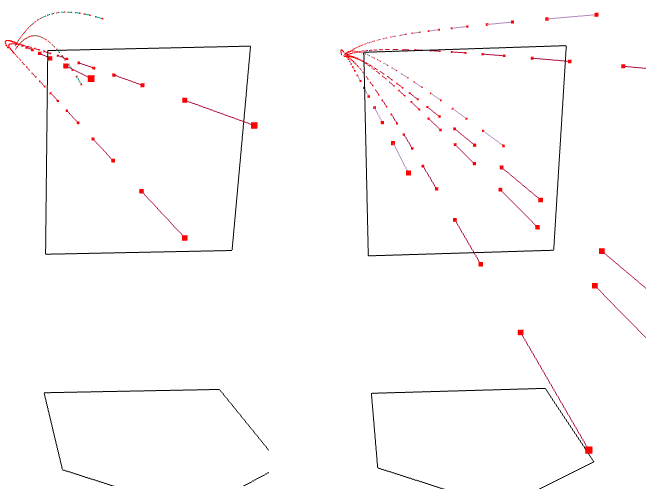
Today marks the final start of the year for Rich Hill of the Boston Red Sox. It’s also only his fourth start of the year. He was signed as depth as attrition left an empty spot in the rotation. In his three starts, however, he has given up only three runs in 23 innings while striking out 30 and walking only two. How does he do it? Over at Baseball Prospectus they took a look at Hill’s curveball and the deception he generates from his arm slot and the location of his fastball. They show this by a comparison graphic. I’ve added the names of the two players, but otherwise the graphic is unaltered.
Hill is on the left
If I am lucky, I can catch this last Hill start at the pub tonight.
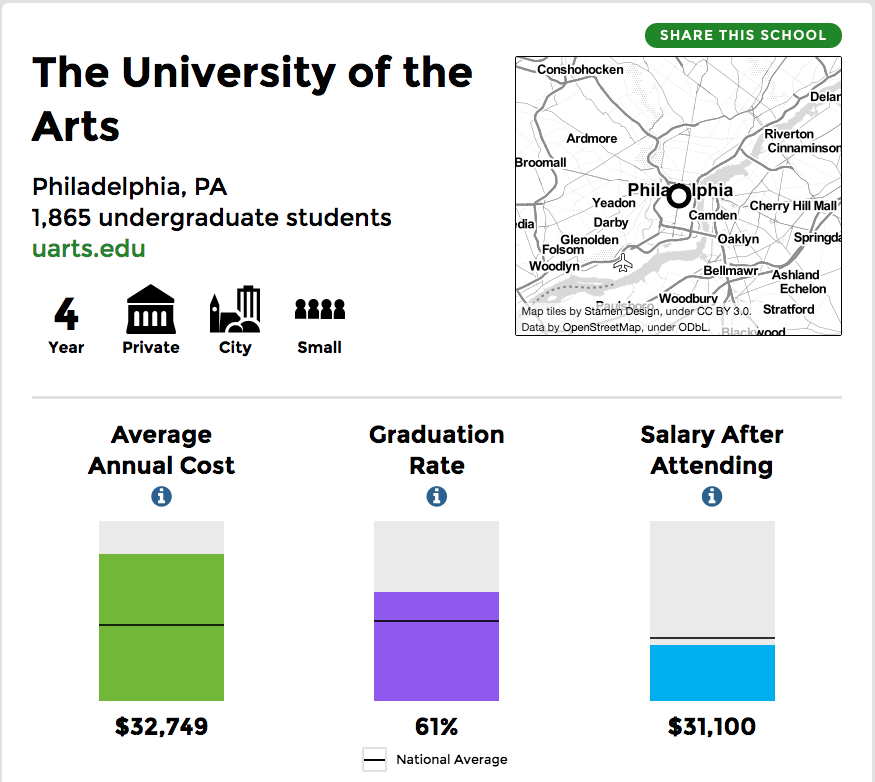
Like the title said, it’s about time I took you all to school…by which I mean university scorecards from the US Department of Education. I used my alma mater, the University of the Arts, to show the design here. Basically you have several sections key to understanding a university from the student body to the financials to the graduates’ prospects.
The scorecard for UArts
Credit for the piece goes to the US Department of Education.
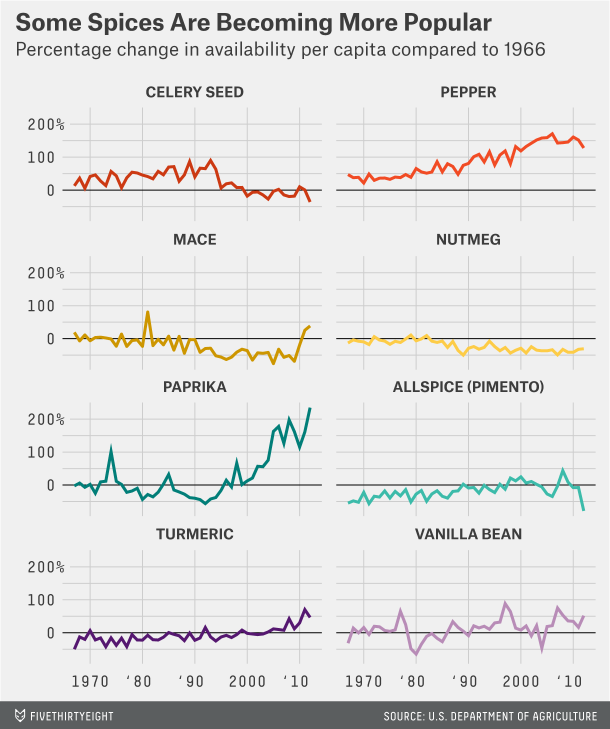
Here is a post for all you cooks and bakers out there: spices. Over the weekend I came upon a piece FiveThirtyEight ran earlier this year about American spice consumption. They use spice availability as a proxy for consumption, because no such data exists—and unfortunately the standard for reporting changed in 2012 so data is only available until then. But the piece uses some nice small multiples and a combined line chart to show some changes. Of note is the decision not to include ginger in the first, most likely because its scale would distort the rest of the chart. Anyway, if you are hungry, probably a good idea not to check this out.
How some spices have changed
Credit for the piece goes to the FiveThirtyEight graphics department.
11 candidates. 9 authors. (That would be the sub-title if my blog had sub-titles.)
I do not have cable and so watching the debate live was not an option. Instead, I rely upon post-debate coverage to understand who said what and to whom. Usually that means an article with some video clips. But this piece from the Washington Post looks at the debate by the numbers.
The Wheel of Trump
What is worth pointing out is not Trump’s hair, but the credit list below. That is nine people who had to contribute to one article, which relies both on reporting and data, on text and images, and none of it is interactive. That list is not all reporters, you have a mixture of reporters, designers, and illustrators working together to produce some quality content. And while the piece was planned—how could it not have been—it still went live within probably hours of the debate as its publish date was the same date as the debate. Sometimes people think that smart, clear graphics are simple and easy to produce. Well, not always.
The graphic itself has two nice features worth mentioning specifically. One, the use of HTML text in the graphic. That makes the text searchable and more importantly rendered by the browser on the page instead of relying upon image export quality. The second is that this piece relies on two colours: black and red. Tints of both allow the entirety of the story to be told. Each candidate is represented by the same red without need for ROYGBIV+.
Credit for the piece goes to Bonnie Berkowitz, Kat Downs, Samuel Granados, Richard Johnson, Ted Mellnik, Katie Park, Kevin Schaul, Shelly Tan, and Kevin Uhrmacher.
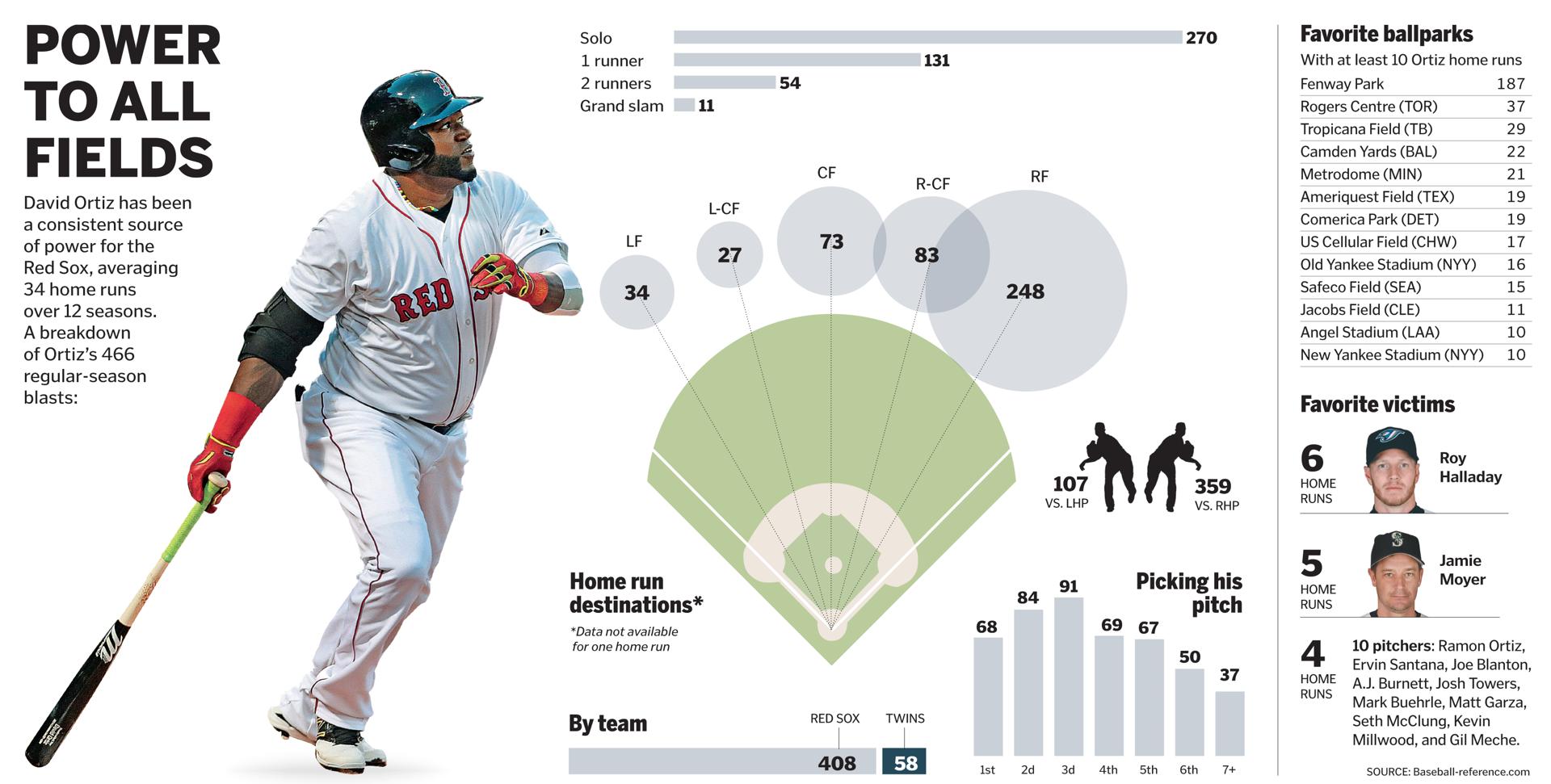
This past weekend, David Ortiz hit his 500th home run, a significant milestone in Major League Baseball attained only by a handful of players. This piece from the Boston Herald commemorates the feat—with too many photographs and embellishment for my liking—by putting his season totals on a timeline while putting Ortiz at the bottom of the 500+ home run club.
The timeline of the home runs
The following piece dates from April 2015 and was about the impact of defensive shifting on Ortiz, but it has a nice graphic on his home run output. It’s just outdated by most of this season. But, from a data viusalisation standpoint, I find it a far more useful and telling graphic.
A look at Ortiz’s home runs
Credit for the Boston Herald piece goes to Jon Couture.
Credit for the Boston Globe piece goes to the Boston Globe graphics department.
As of today, Queen Elizabeth is the longest reigning British monarch. She has surpassed the record of the famous Queen Victoria, Elizabeth’s great-great-grandmother at 63 years and seven months. Obviously a lot of things have changed over those 63 years, and in this article the BBC uses a graphic to look at how the world stage has changed.
Queen Elizabeth II’s reign
Credit for the piece goes to the BBC graphics department.
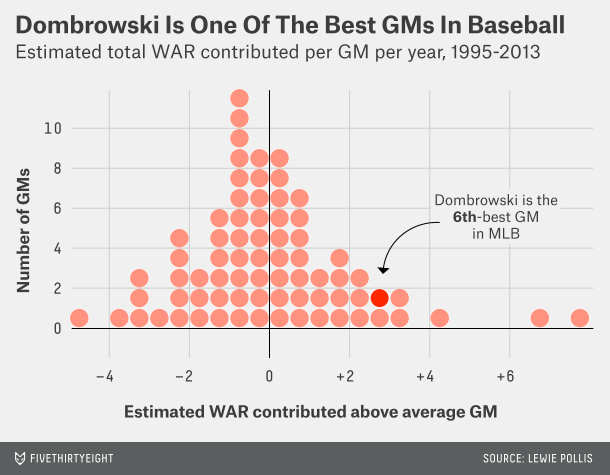
The Boston Red Sox made big baseball news last night by announcing the hiring of former Tigers GM Dave Dombrowski to head Boston’s baseball operations. The second big piece of baseball news, Boston’s GM, Ben Cherington, has resigned as he does not want to work under Dombrowski.
As you might figure, I enjoy data’s role in baseball. That Dombrowski is not the biggest analytics-embracing GM worries me a bit. But after re-reading FiveThirtyEight’s piece on the value he brings—naturally through some data and analysis—I think I will at least give him a season or two before calling for his head.
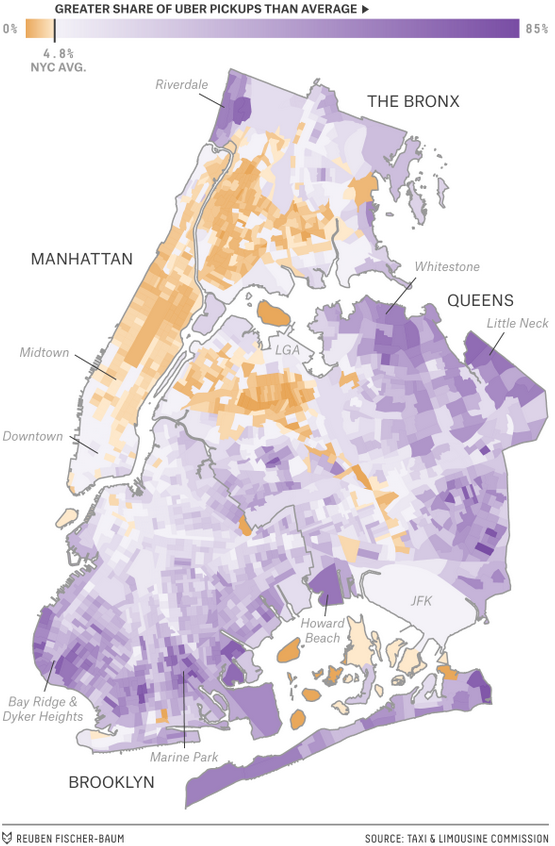
I just spent the weekend back in my hometown of Philadelphia and while we walked most places, there were a few Uber rides. As someone who doesn’t use the app and normally will hail a taxi when necessary, I had been looking forward to posting this piece. FiveThirtyEight looked at data for New York comparing Uber to taxis.
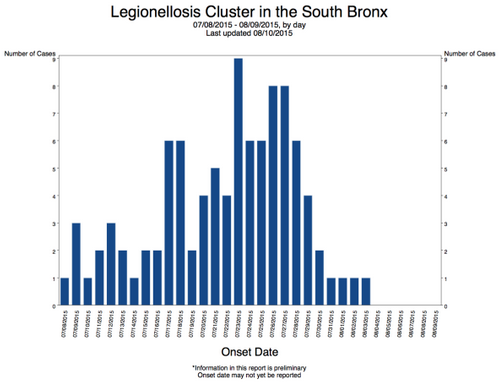
Today’s piece really is not a flashy one. I mean you can see that from the bar chart below. But, FiveThirtyEight put together a piece around it explaining just how that one chart is incredibly useful.
The epidemic curve
Credit for the graphic goes to the New York City Department of Health. For the analysis piece, that goes to FiveThirtyEight.