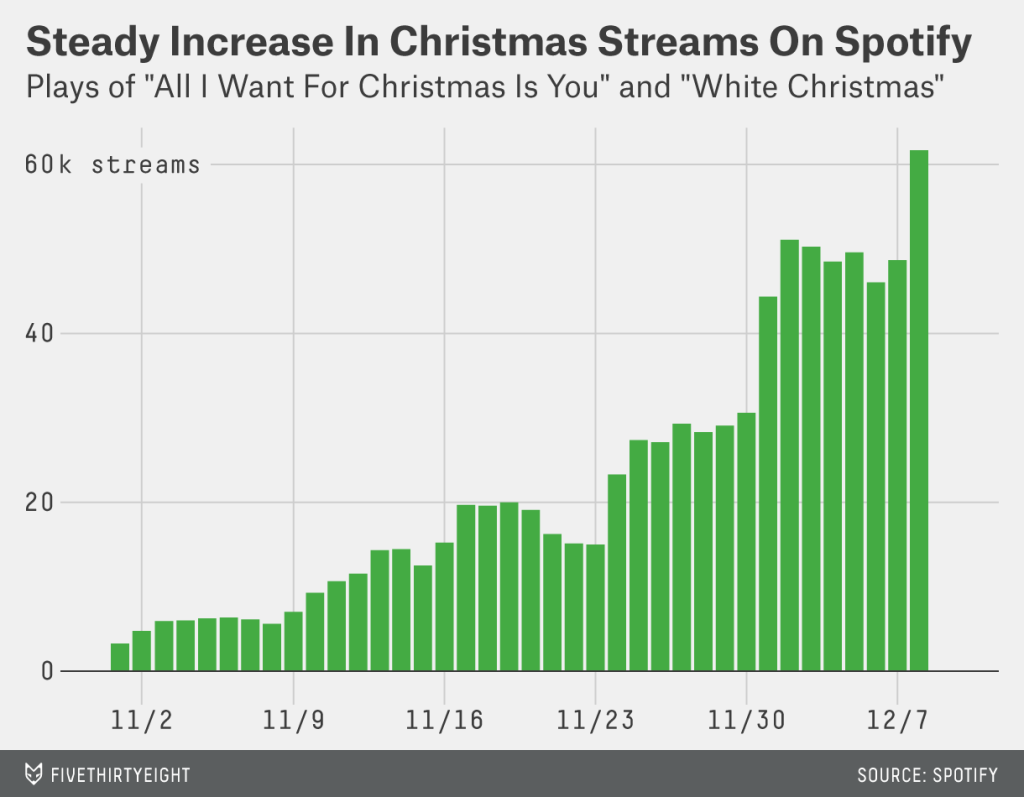
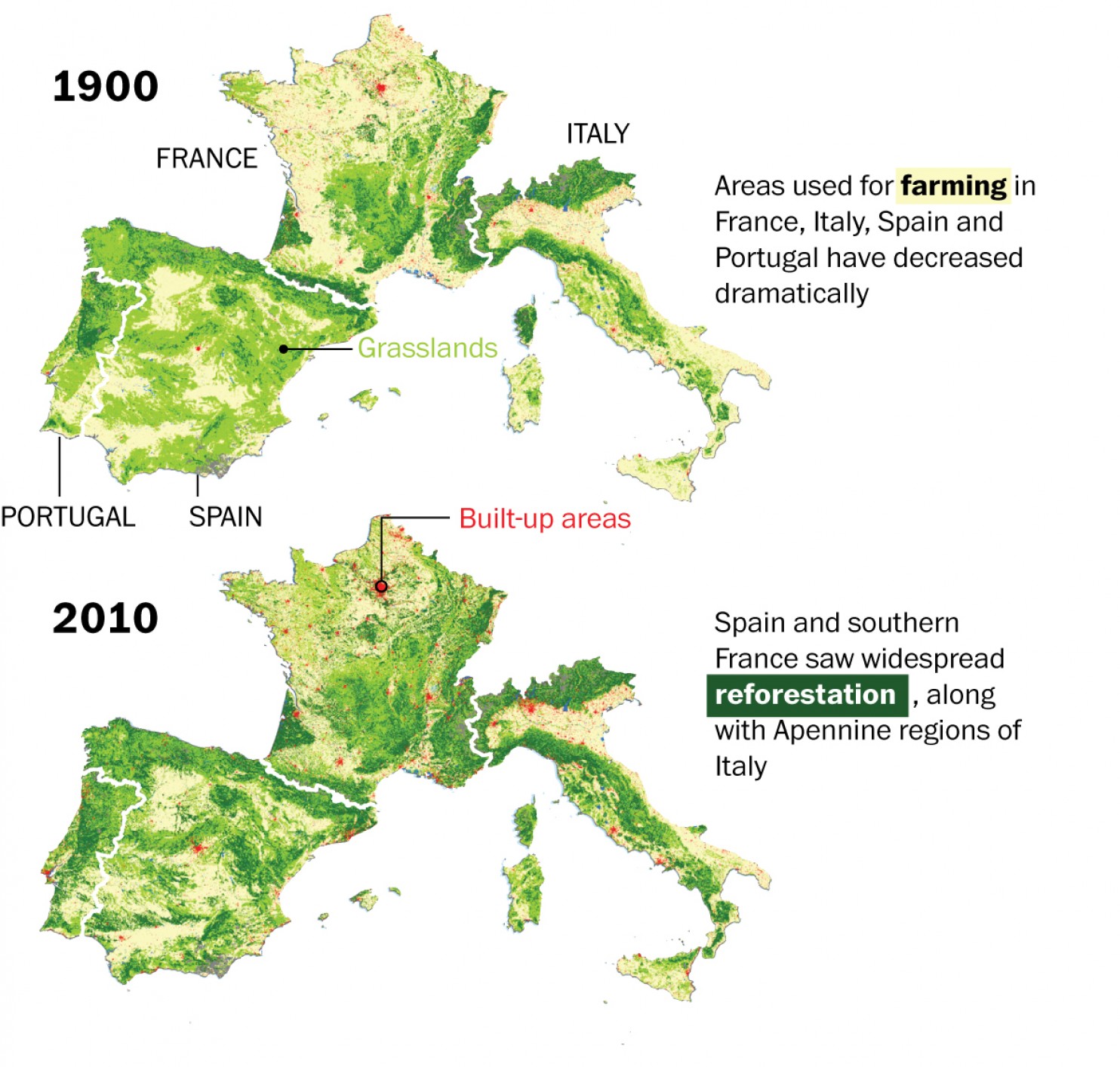
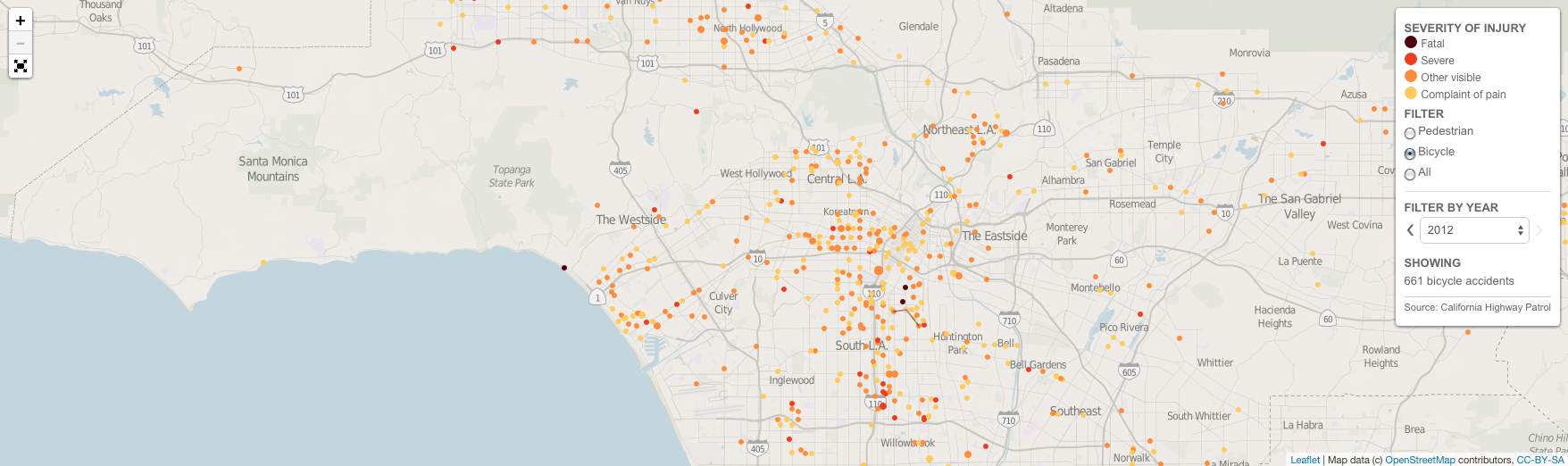
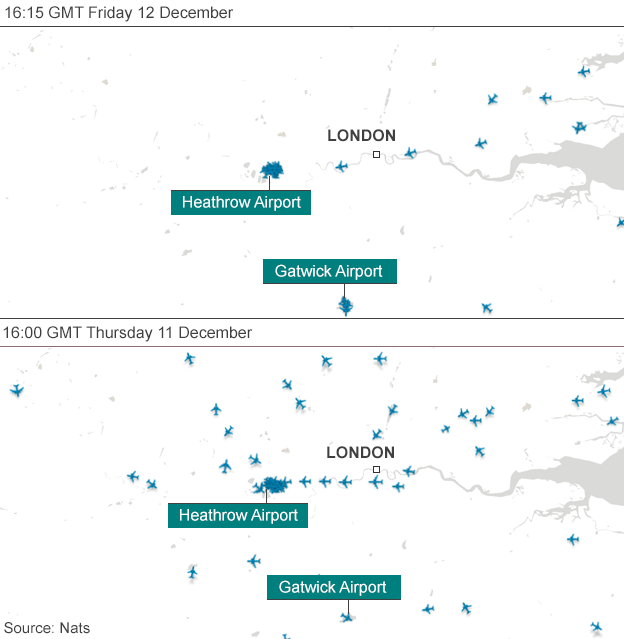
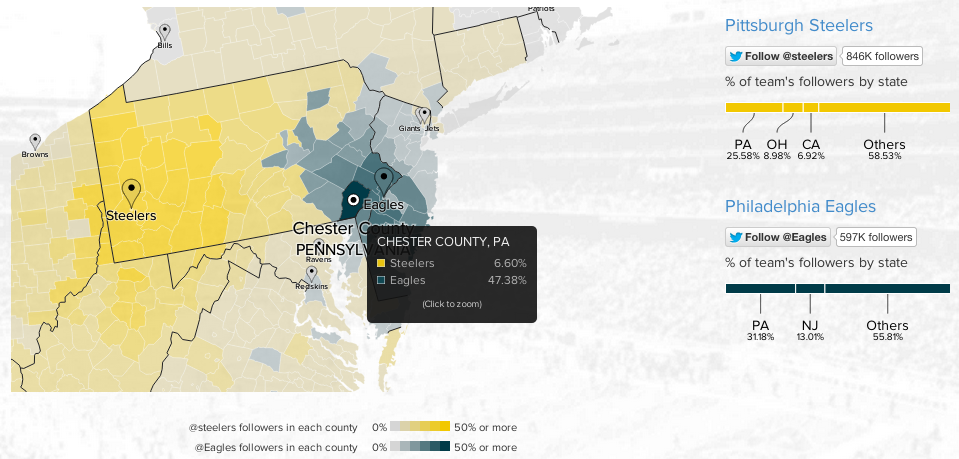
The Christmas holidays are known for many things. One of them is the office holiday party. Today’s post looks at a flow chart put together by the company for which I work, Euromonitor International. As it was put together by the design team, you might very well think that I had something to do with it. But I couldn’t possibly comment.
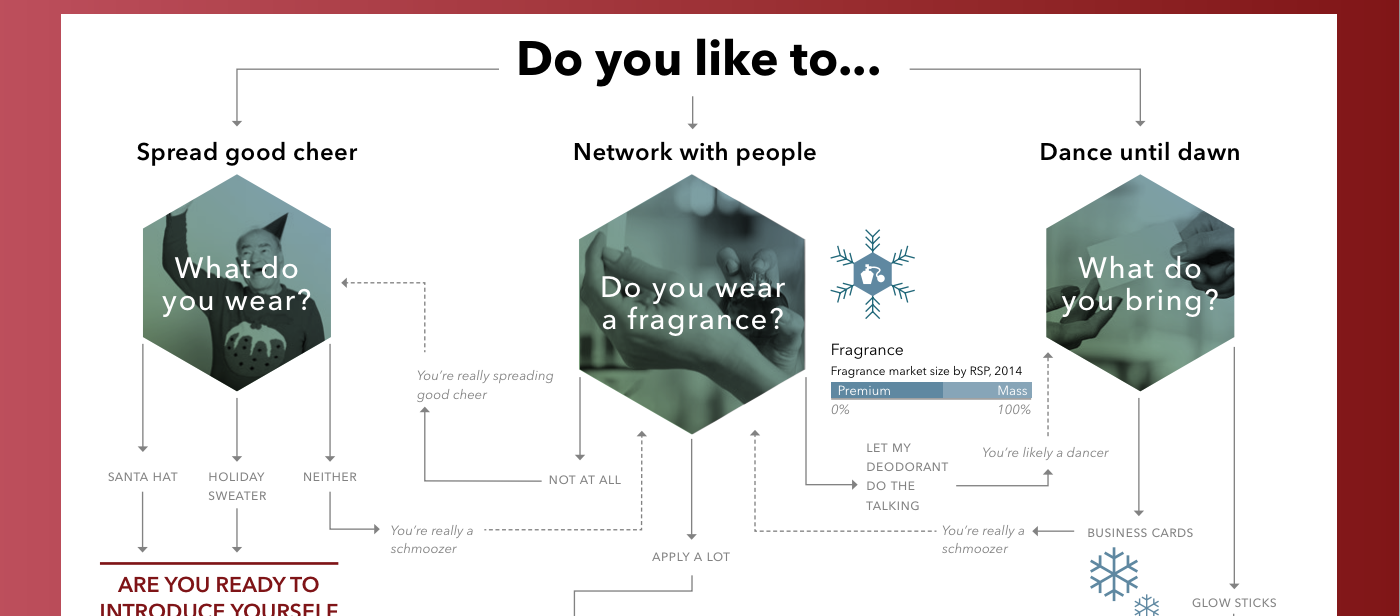
Credit for the piece goes to the Euromonitor design team.