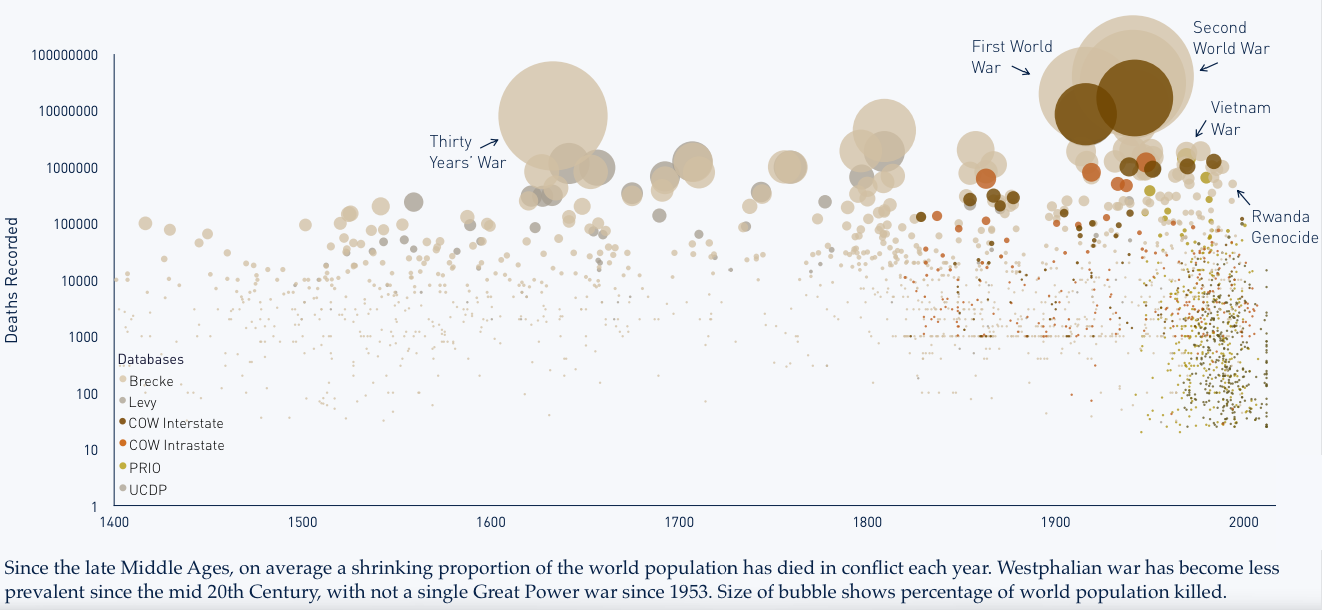
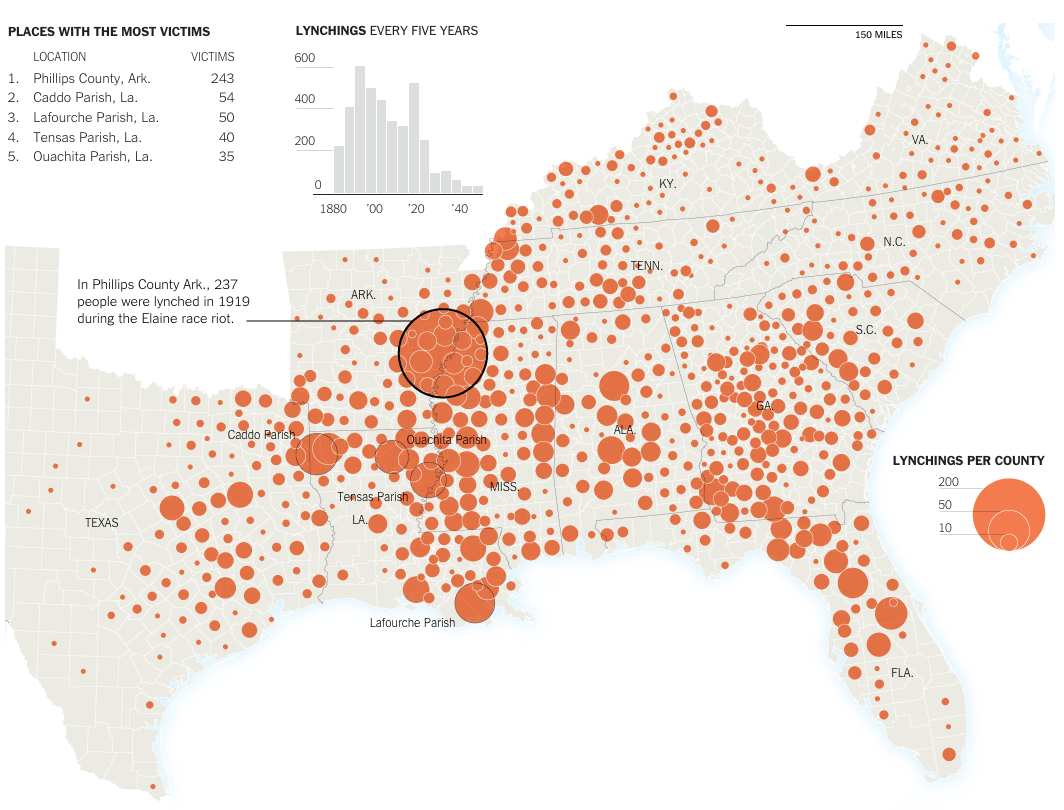
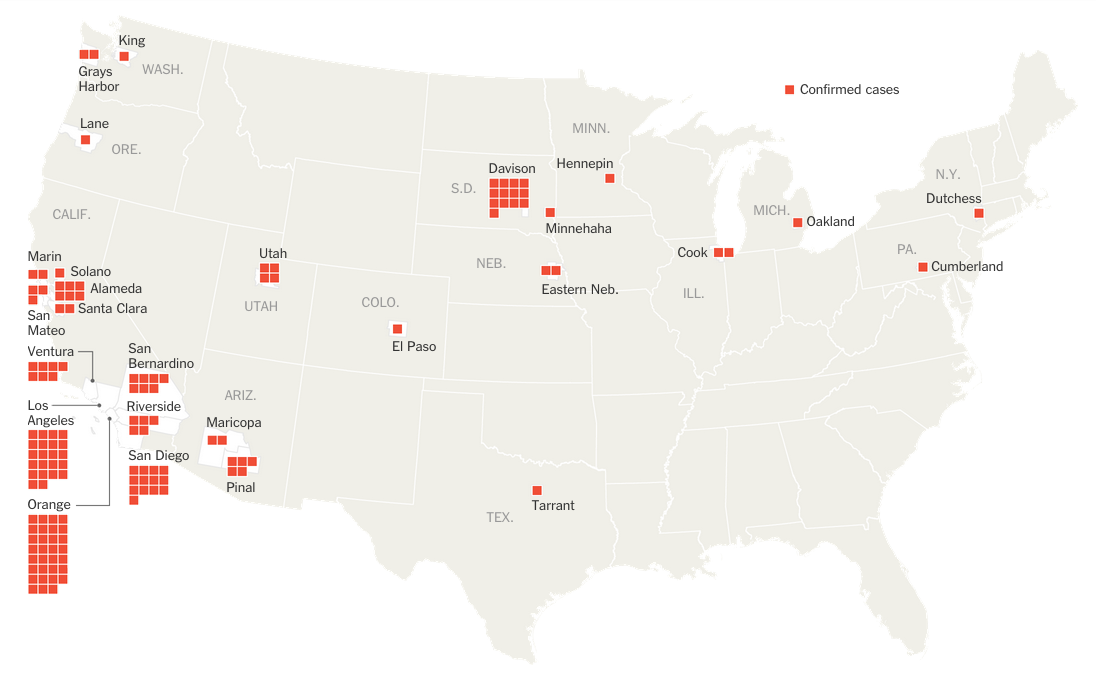
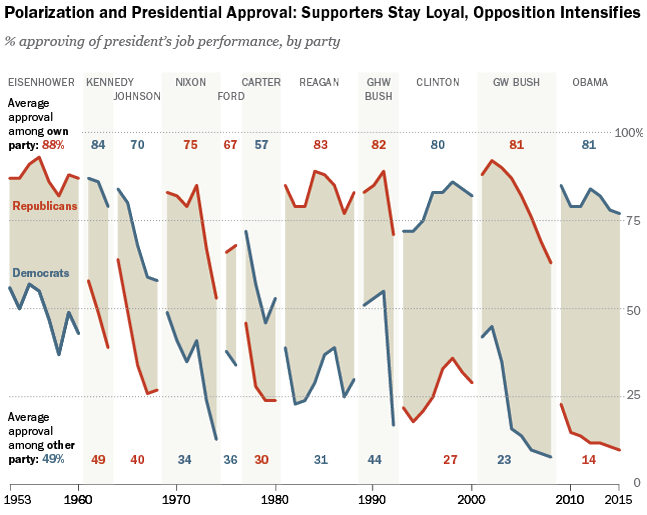
Or so says Adweek. I would heartily disagree about their inclusion of Yuengling in their group of crappy. Though the other nineteen, yeah, I would tend to agree. Regardless, the infographic that sparked the Adweek post is quite blah. I do enjoy the illustrations of the bottles and labels, but the data visualisation below is weak.
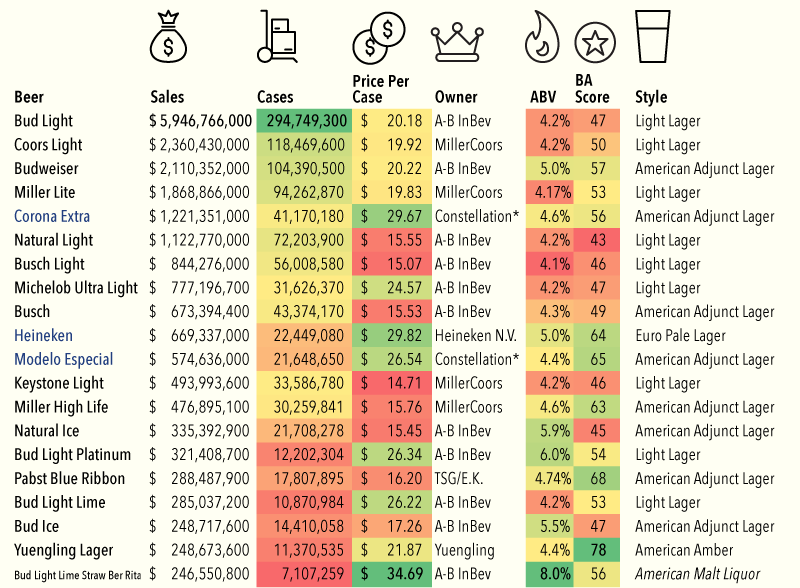
So because of Yuengling, I decided to take a quick stab at ways to improve it. My first finding in the data was that the different brands were assigned a Beer Advocate rating, and Yuengling rated the highest—though not terribly high overall. Still, unless you are looking to get drunk, it does offer a good taste/cost value among the consideration set.
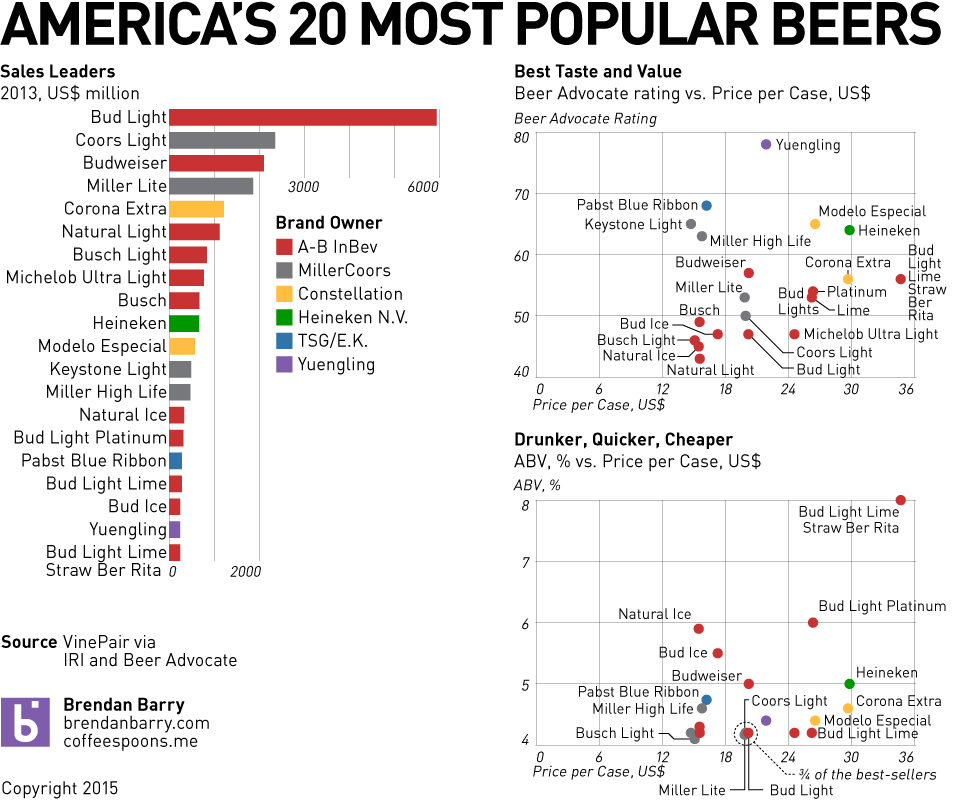
Credit for the infographic goes to VinePair.