Tag: bar chart
-

To X or Not to X
As it happens, the Latino culture largely remains x’ed out on using the term Latinx, according to a new survey from Pew Research. The issue of supplanting Latino/Latina with Latinx as a gender neutral replacement—or as a complementary alternative—emerged in the general discourse in that oh-so-fun year of 2020 when everything went well. One common…
-
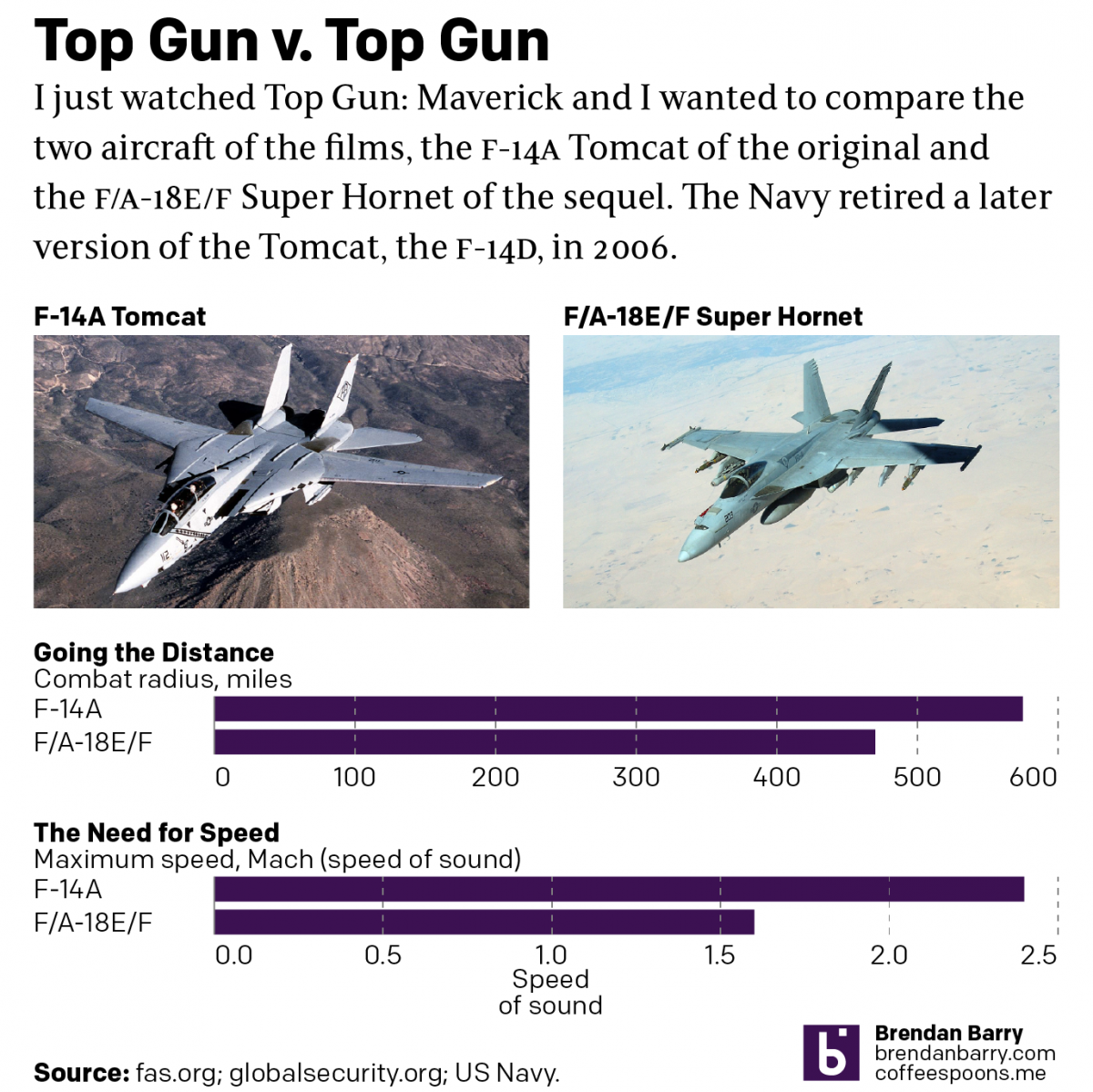
Top Gun
Last night I went to see Top Gun: Maverick, the sequel to the 1986 film Top Gun. Don’t worry, no spoilers here. But for those that don’t know, the first film starred Tom Cruise as a naval aviator, pilot, who flew around in F-14 Tomcats learning to become an expert dogfighter. Top Gun is the…
-
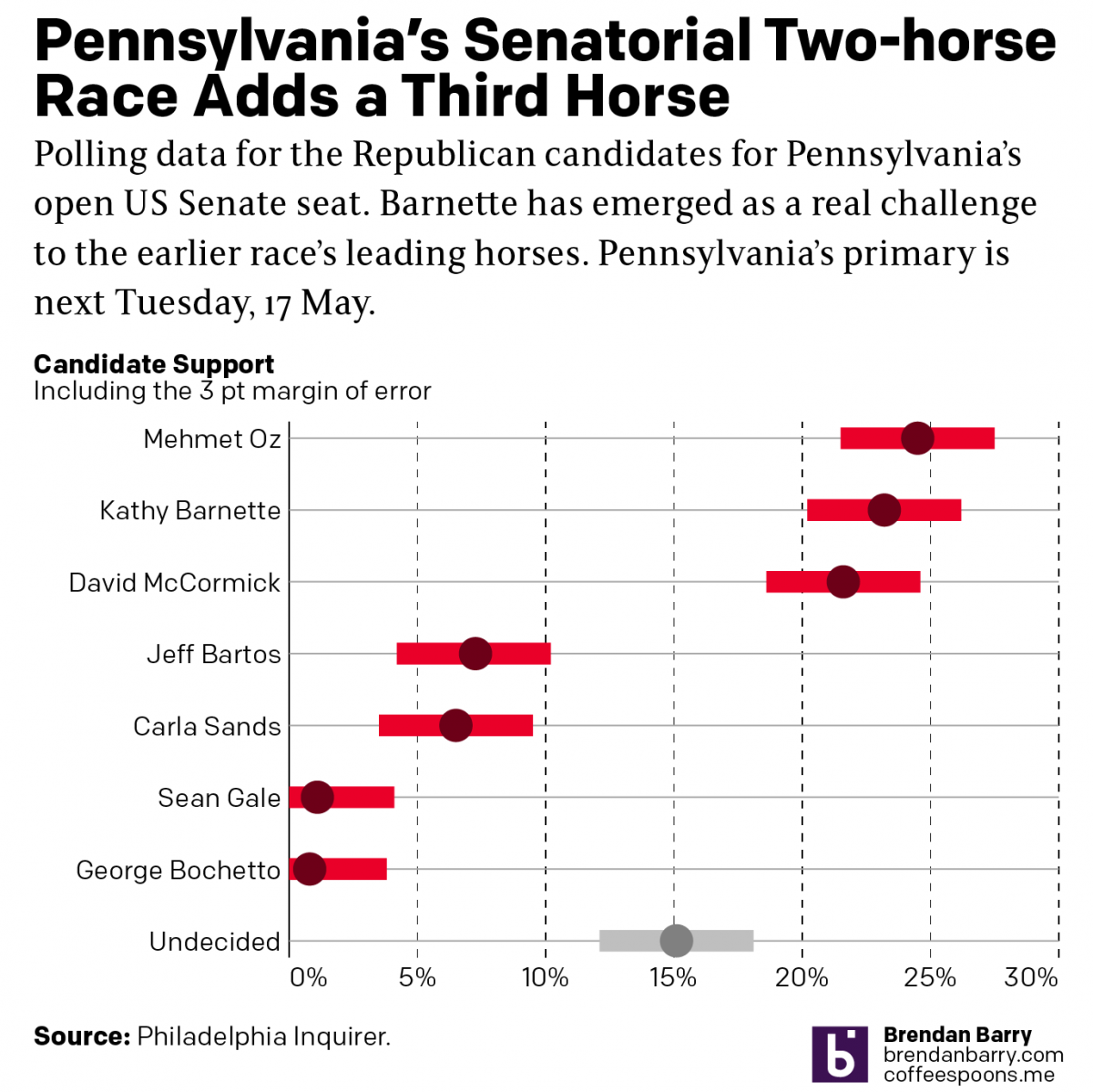
Political Hatch Jobs
Earlier this week I read an article in the Philadelphia Inquirer about the political prospects of some of the candidates for the open US Senate seat for Pennsylvania, for which I and many others will be voting come November. But before I get to vote on a candidate, members of the political parties first get…
-
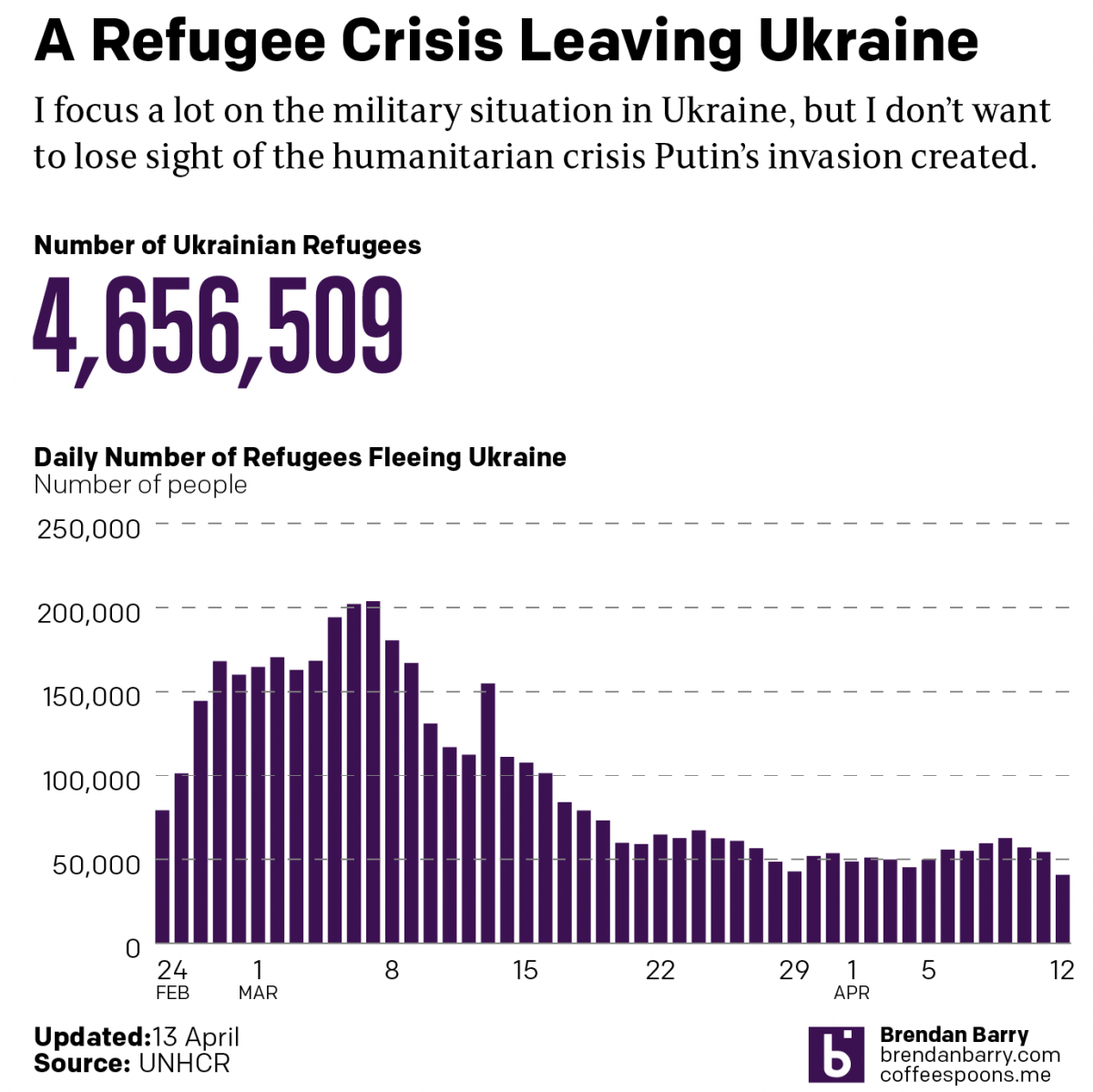
Russo-Ukrainian War Refugees: 12 April
Another week, more combat and refugees in Ukraine. I’m going to try and hold the war update until tomorrow pending some news that hasn’t been confirmed yet: the fall of Mariupol. Instead, we’re going to again look briefly at the refugee situation in Ukraine—technically outside. I haven’t seen a recent number on the internally displaced,…