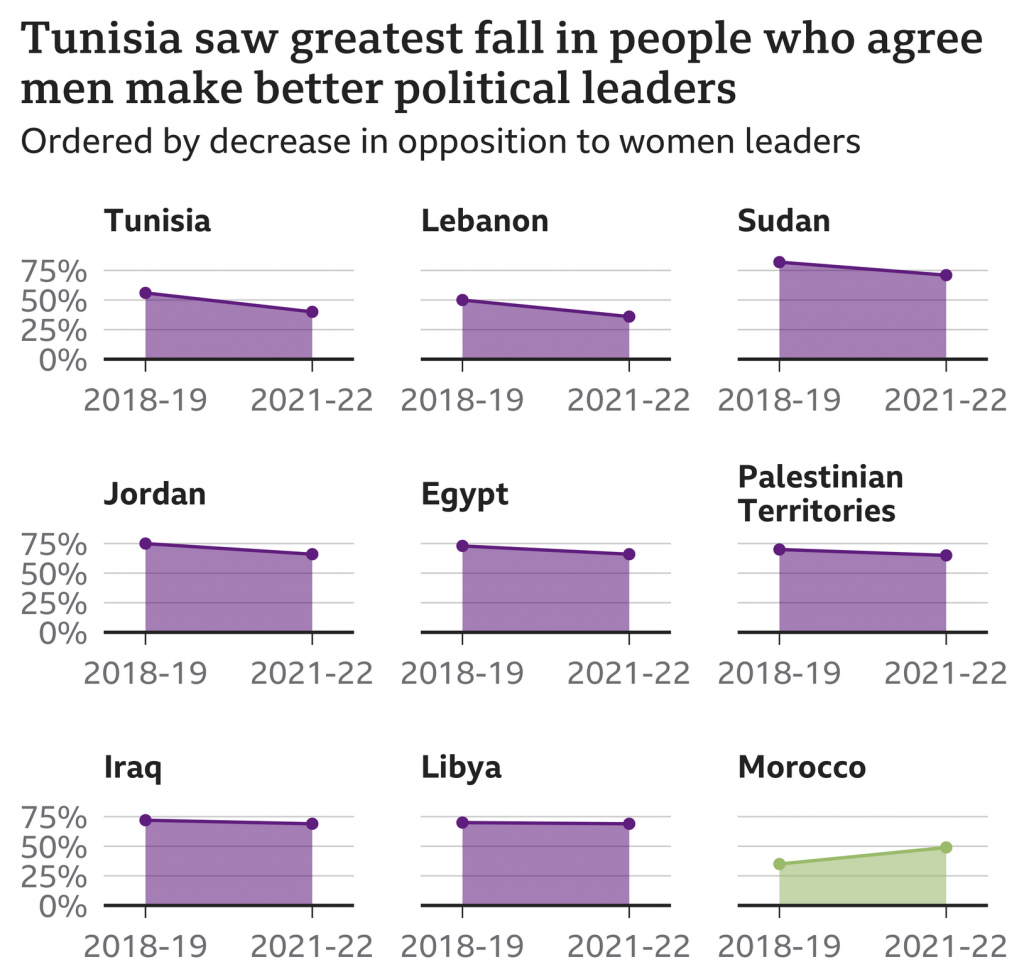
We are going to start this week off with a nice small multiple graphic that explores the reducing resistance to women in positions of leadership in Arab countries. The graphic comes from a BBC article published last week.
A lot of positive negative movement.
These kinds of graphics allow a reader to quickly compare the trajectory of a thing between a start and an endpoint. The drawback is it can obscure any curious or interesting trends in the midpoints. For example, with Libya, is its flat trajectory always been flat? You could imagine a steep fall off but then rapid climb back up. That would be a story worth telling, but a story obscured by this type of graphic.
I do think the graphic could use a few tweaks to help improve the data clarity. The biggest change? I would work to improve the vertical scale, i.e. stretch each chart taller. Since we care about the drop in opposition to women leaders, let’s emphasise that part of the graphic. There could be space constraints for the graphic, but that said, it looks like some of the spacing between chart header and chart could be reduced. And I think for most of the charts except for the first, the year range could be added as a data definition to the graphic and removed from each chart. Similar to how every row only once uses the vertical axis labels.
Another way this could be done is by reducing the horizontal width of each chart in an attempt to squeeze the nine from three rows down to two. That would mean two additional chart positions per row. Tight fit? Probably, but there is also some extraneous space to the right and left of each chart and a large gap between the charts themselves. This all appears to be due to those aforementioned x-axis labels. An additional benefit to reducing the horizontal dimensions of each chart is it increases the vertical depth of the chart as each line’s slope, its rise over run, sees its horizontal distance shrink.
Overall this is a really smart graphic that works well, but with a few extra tweaks could take it to the next level.
Credit for the piece goes to the BBC graphics department.
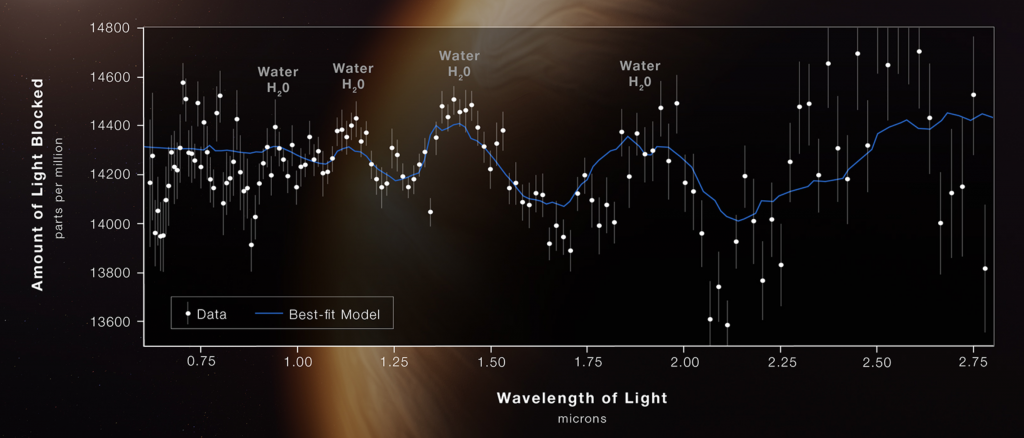
And by out there I mean 1150 light years away. One of the five amazing images out of the first day’s announcement by the James Webb Space Telescope (JWST) team was not a sexy photo of a nebula or a look back 13.5 billion years in time. Instead it was a plot of the amount of infrared light was blocked as exoplanet WASP-96b, a hot Jupiter, transited in front of its sun. A hot Jupiter is a gas giant roughly the size of Jupiter that orbits its sun so closely—often closer than Mercury does our Sun—its year takes mere days. WASP-96b is about half the mass of Jupiter and a year takes a little over three Earth days. Hot indeed.
The JWST means not just to take those images we saw, but to also capture data about the light passing through planetary atmospheres, just like WASP-96b. And showing the world Tuesday just how that works was a brilliant idea. What they shared was this graphic.
Everyone likes water.
The original post explains the science behind it, but in short we see telltale signs of water vapor in the atmosphere. Remember that the planet is far too hit for liquid water to exist. But because the peaks and troughs were not as pronounced as expected, scientists can conclude that there are clouds and haze in the atmosphere. It did not detect any significant signs of oxygen, carbon dioxide, or methane, all of which would be noticeable if present as we expect in future exoplanets to be studied.
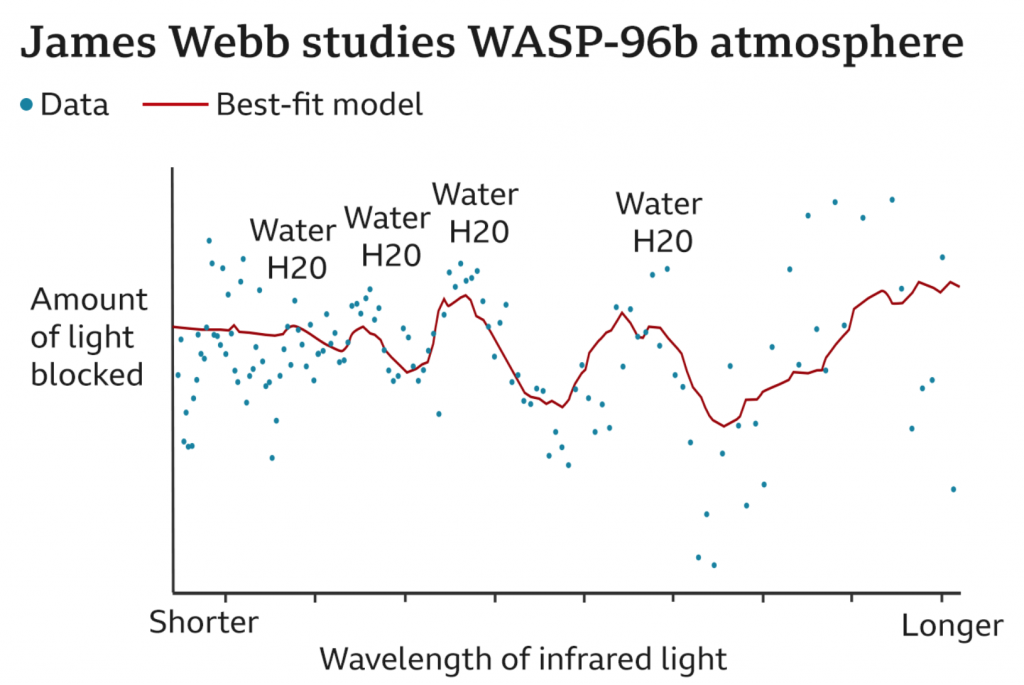
But later that day, the BBC published an article summarising the releases, but included a different version of the above graphic. Though the other four photos were unchanged. The BBC presented us with this.
Also steamy.
The most notable difference is the background. What was a giant illustration of a planet and then a semi-transparent chart background atop that on which the graphic sat is here replaced by a simple white background. Off the bat this chart is easier to read.
But then here we also lose some data clarity. Note on the original how we have axis markers for the wavelengths of light and the parts per million of light blocked. All are absent here. Instead the BBC opted to only put “Shorter” and “Longer” on the wavelength axis. I would submit that there was no real need to remove those labels, but that they could have been added to with these new ones. The new labels certainly explain the numbers to an audience that may not be as scientifically literate as perhaps the JWST’s audience was or was thought to be. There is certainly a value to simplifying and distilling things to a level at which your audience can understand. But there’s also a value in presenting more complex data, issues, and ideas in an attempt to educate and elevate your audience. In other words, instead of always trying to play to the lowest common denominator, it sometimes is worth it to lose a few in the audience if you ultimately increase the level of said denominator overall.
The other notable difference is that the data is presented without what I assume to be plots of the range of observations with their respective medians. You can see this in the original by how every wavelength has a line and a dot sitting in the middle of that line. In other words, over the 6+ hours the planet was observed, at each wavelength a certain amount of light was blocked. The average middle point over that whole time period is the dot. Then a line of best fit “connects” the dots to show the composition of the light streaming though that steamy atmosphere.
Again, I can understand the desire to remove the ranges and keep the median, but I also think that there is little harm in showing both. Though, the first graphic could like have used an explanation of what was shown, as I’m only assuming what we have and I could be way off. You can show more things and raise the level of the denominator, but you can only do so if you explain what your audience is looking at.
Overall both graphics are nice and capture not just the particular makeup of this one exoplanet’s atmosphere, but more broadly the potential power of the JWST and its impact on astronomy.
Credit for the original goes to the NASA, ESA, CSA, and STScI graphics teams.
Credit for the BBC version goes to the BBC graphics department.
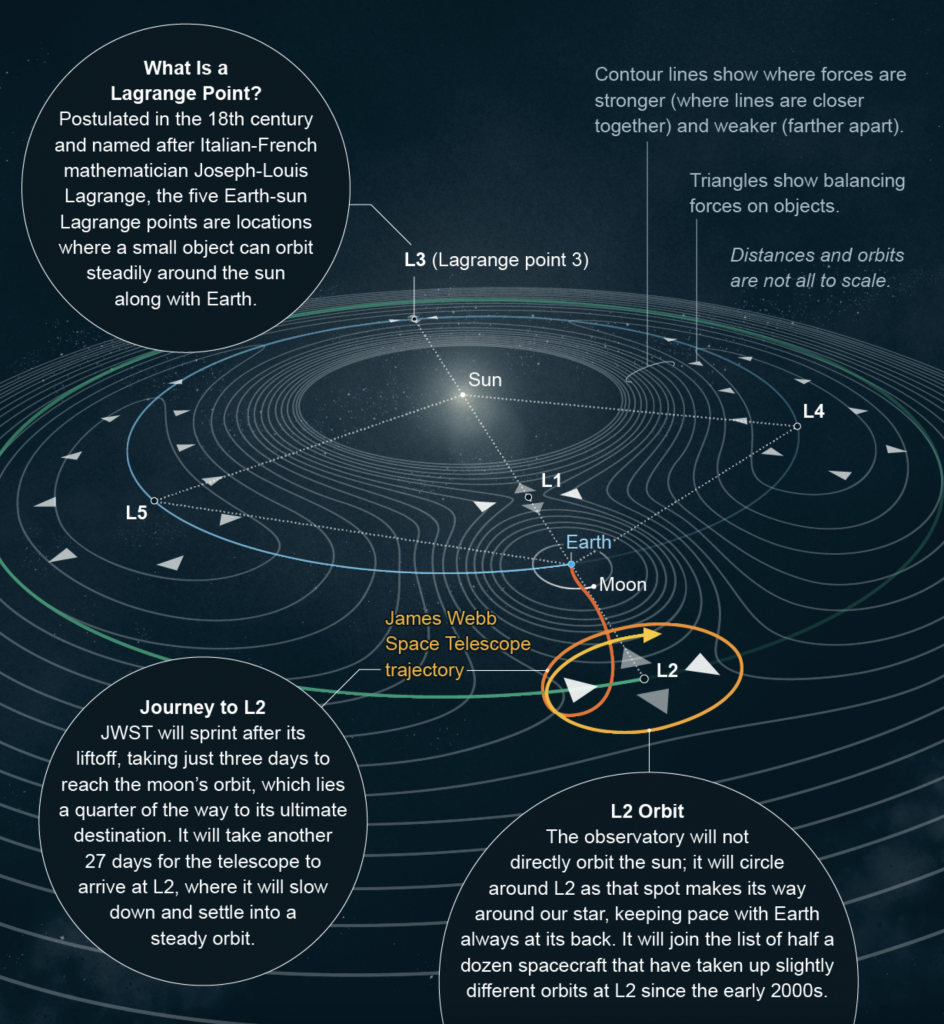
Yesterday I received a question about where the new James Webb Space Telescope is located. Is it in orbit of the Earth, like Hubble? Is it out in deep space?
The answer is no, not really. Now I spent this morning trying to illustrate the answer to that question myself. However, it’s taking me too long. So we’re going to reference this great illustration from Scientific American.
Not quite the final frontier, but the James Webb is pointing that way.
James Webb orbits around a point called the L2 Lagrange point, which sits in a line with Earth and the Sun. The telescope points out and away from the sun whilst the sun shield keeps the sunlight from warming the spacecraft while solar panels collect said light and power the spacecraft.
So if any of my other readers had a similar question, hopefully this goes some ways to answering the question.
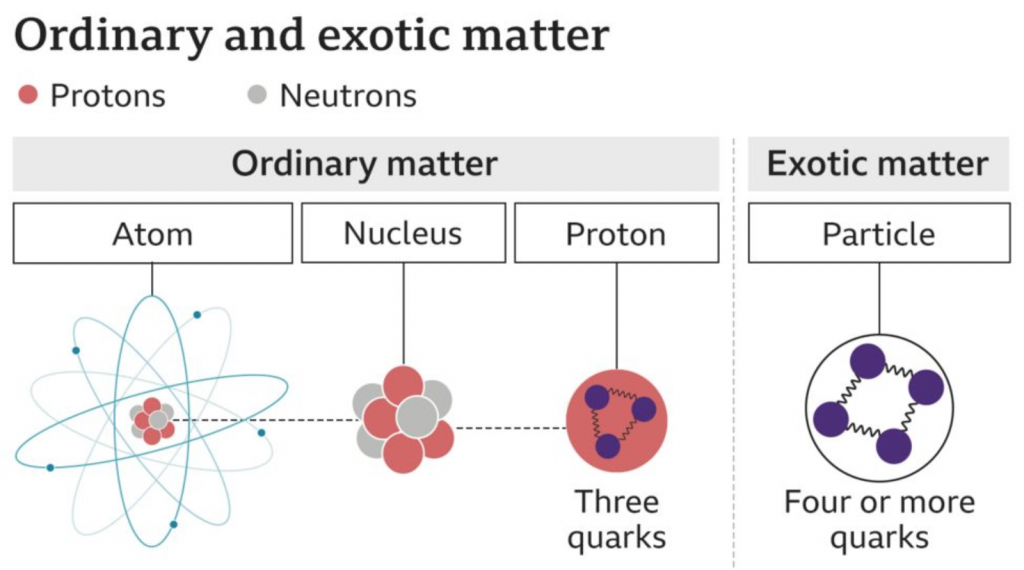
Last week scientists working at the Large Hadron Collider in Switzerland announced the discovery of new sub-atomic particles: a pentaquark and tetraquarks. This BBC article does a really good job of explaining the role of quarks in the composition of our universe, so I encourage you to read the article.
But they also included a graphic to show how quarks relate to atoms. It’s a simple illustration, but it does a great job.
There’s only one Quark though.
Sometimes great and informative graphics can be simple. They needn’t be flashy or over-designed. I could quibble about the depiction of the electron cloud around the nucleus, but it’s not terrible.
Credit for the piece goes to the BBC graphics department.
I took two weeks off as work was pretty crazy, but we’re back to covering data visualisation and design with a graphic about trains. And anybody who knows me knows how I love trains. One of the early acts of the Biden administration was funding a proper expansion of rail service in the United States.
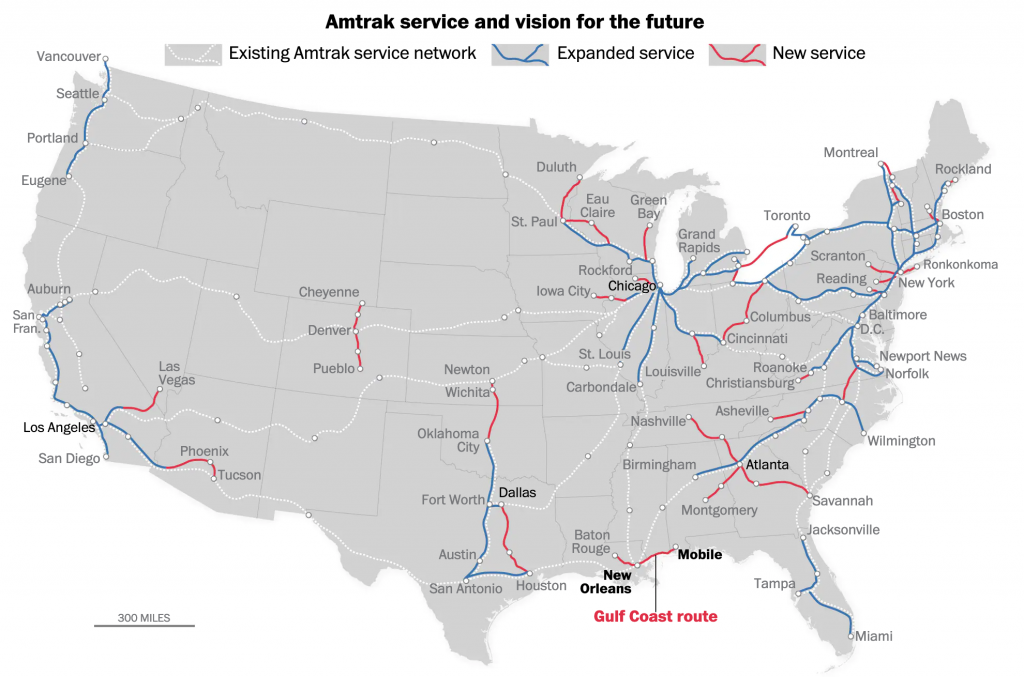
Last week the Washington Post published an article that explored some of the difficulties Amtrak, the national rail company, faces in that expansion. Most of it has to deal with the fact that outside the Northeast Amtrak largely uses rail lines owned by freight companies.
The article uses a map to show Amtrak routes and, in particular, where Amtrak wants to increase service or create new service.
No Alaska, no Hawaii
As far as the map goes, it does a nice job needing not to reinvent the wheel. When an existing route will have expanded service, e.g. the Northeast Corridor, the blue line sits next to the dotted white line. What remains a bit unclear to me is the use of black text for Chicago, Atlanta, Dallas, and Los Angeles. The bold type for New Orleans and Mobile makes sense because of the story’s focus on that particular route. Chicago is mentioned once, but Dallas is not. So that is unclear.
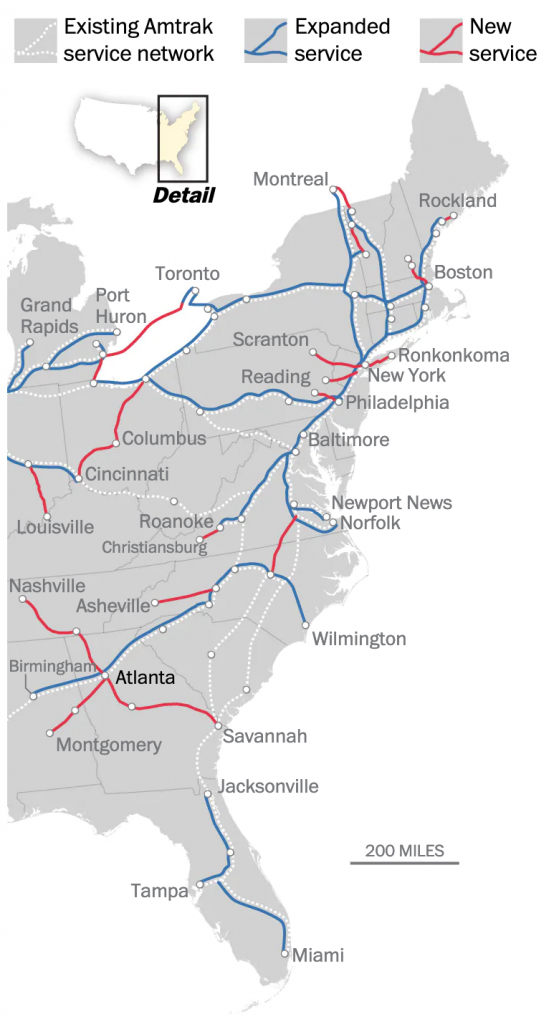
But what really stood out to me was what happened when I re-read the story on my mobile. The graphic split from a full map to three narrow graphics, each featuring 1/3 of the United States. The designers moved the text labels so that they are fully visible in each graphic.
Overall, the piece does a great job at showing the map, but in particular it shines when it swaps out the large map for the smaller graphics on small screens. And the attention to detail in moving the text labels makes it all the better.
First, as we all should know, climate change is real. Now that does not mean that the temperature will always be warmer, it just means more extreme. So in winter we could have more severe cold temperatures and in hurricane season more powerful storms. But it does mean that in the summer we could have more frequent and hotter heat waves.
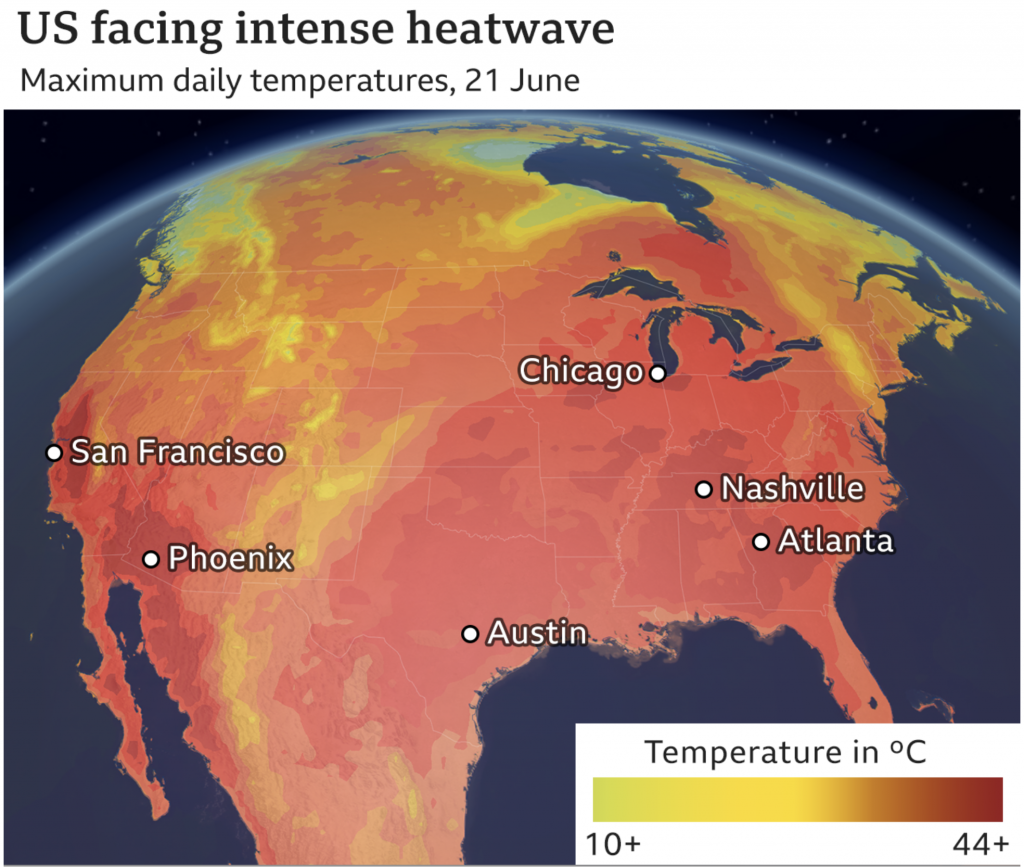
Enter the United States, or more specifically the North American continent. In this article from the BBC we see photographs of the way the current heatwave is playing out across the continent. But it opens up with a nice map. Well, nice as in nicely done, not as in this is actually nice weather.
Yeah, no thanks.
The only complaint most of my American readers might have is that the numbers make no sense. That’s because it’s all in Celsius. Unfortunately for Americans most of the rest of the world uses Celsius and not Fahrenheit. Suffice it to say you don’t want to be in the dark reds. 44C equals 111F. 10C, the greenish-yellow side of the spectrum, is a quite pleasant 50F.
And that can relate to a small housekeeping note. I’m back after a long weekend up in the Berkshires. I took a short holiday to go visit the area near that north–south band of yellow over the eastern portion of the United States. It was very cool and windy and overall a welcome respite from the heat that will be building back in here across the eastern United States later this week.
At least yesterday was the summer solstice. The days start getting shorter. And in about five weeks or so we will reach the daily average peak temperature here in Philadelphia. At that point the temperatures begin cooling towards their eventual mid-January nadir.
I can’t wait.
Credit for the piece goes to the BBC graphics department.
Editor’s note: I was having some technical issues last week. This was supposed to post last week.
Editor’s note two: This was supposed to go up on Monday. Still didn’t. Third time’s the charm?
Yesterday I wrote about a piece from the New York Times that arrived on my doorstep Saturday morning. Well a few mornings earlier I opened the door and found this front page: a map of the western United States highlighting the state of New Mexico.
That doesn’t exactly look like a climate I’d enjoy.
Unlike the graphic we looked at yesterday, this graphic stretched down the page and below the fold, not by much, but still notably. The maps are good and the green–red spectrum passes the colour blind test. How the designer chose to highlight New Mexico is subtle, but well done. As the temperature and precipitation push towards the extreme, the colours intensify and call attention to those areas.
Also unlike the graphic we looked at yesterday, this piece contained some additional graphics on the inside pages.
Definitely not a place where I want to be.
These are also nicely done. Starting with the line chart at the bottom of the page, we can contrast this to some of the charts we looked at yesterday.
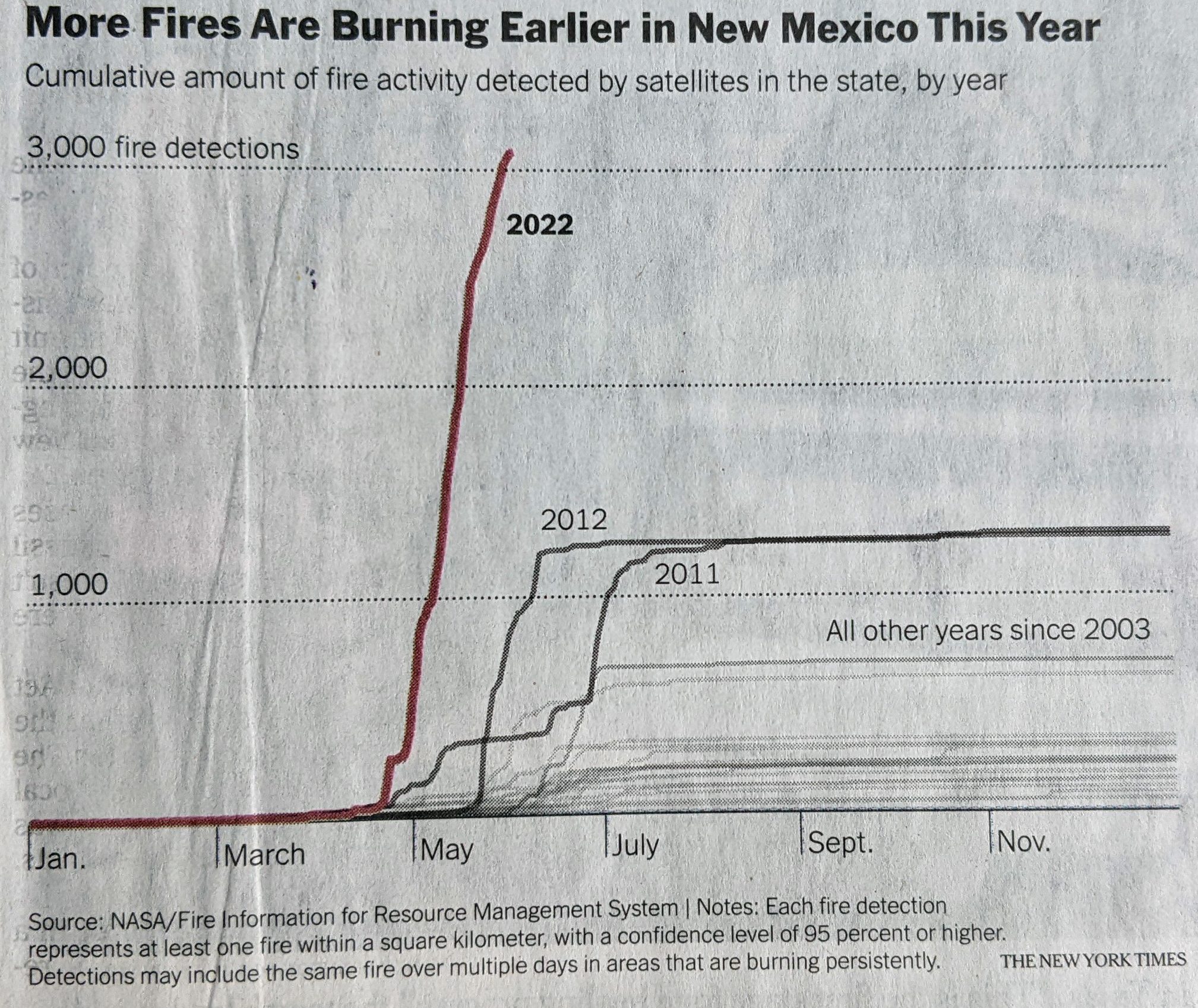
Burn, baby, burn.
Here the designer used axis lines and scales to clearly indicate the scale of New Mexico’s wildfire problem. Not only can you see that the number of fires detected has spiked far above than the number in the previous years back to 2003. And not only is the number greater, the speed at which they’ve occurred is noticeably faster than most years. The designer also chose to highlight the year in question and then add secondary importance to two other bad years, 2011 and 2012.
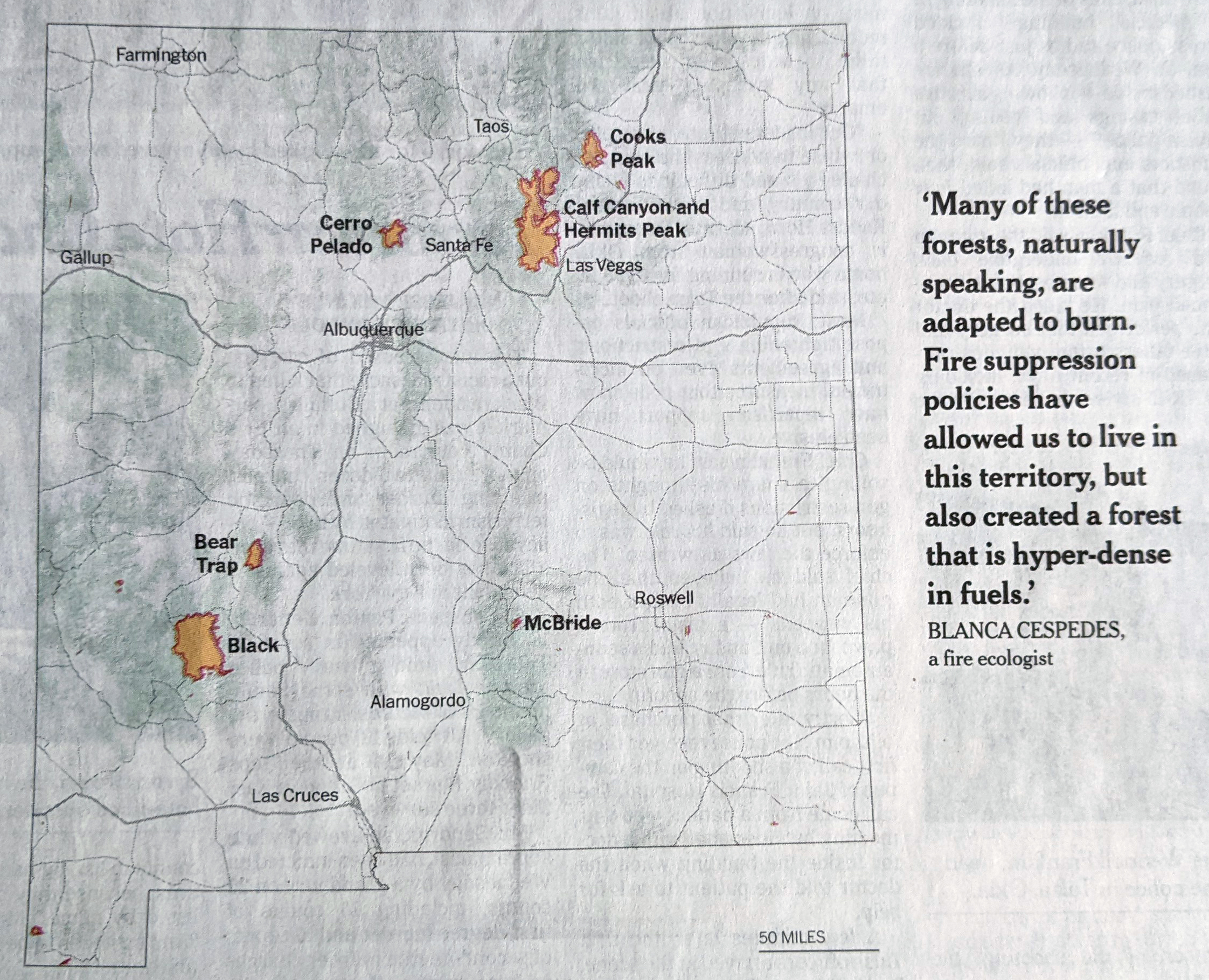
The other graphics are also maps like on the front page. The first was a locator map that pointed out where the fires in question occurred. Including one isn’t much of a surprise, but what this does really nicely is show the scale of these fires. They are not an insignificant amount of area in the state.
Pointing out where I really don’t want to be in New Mexico.
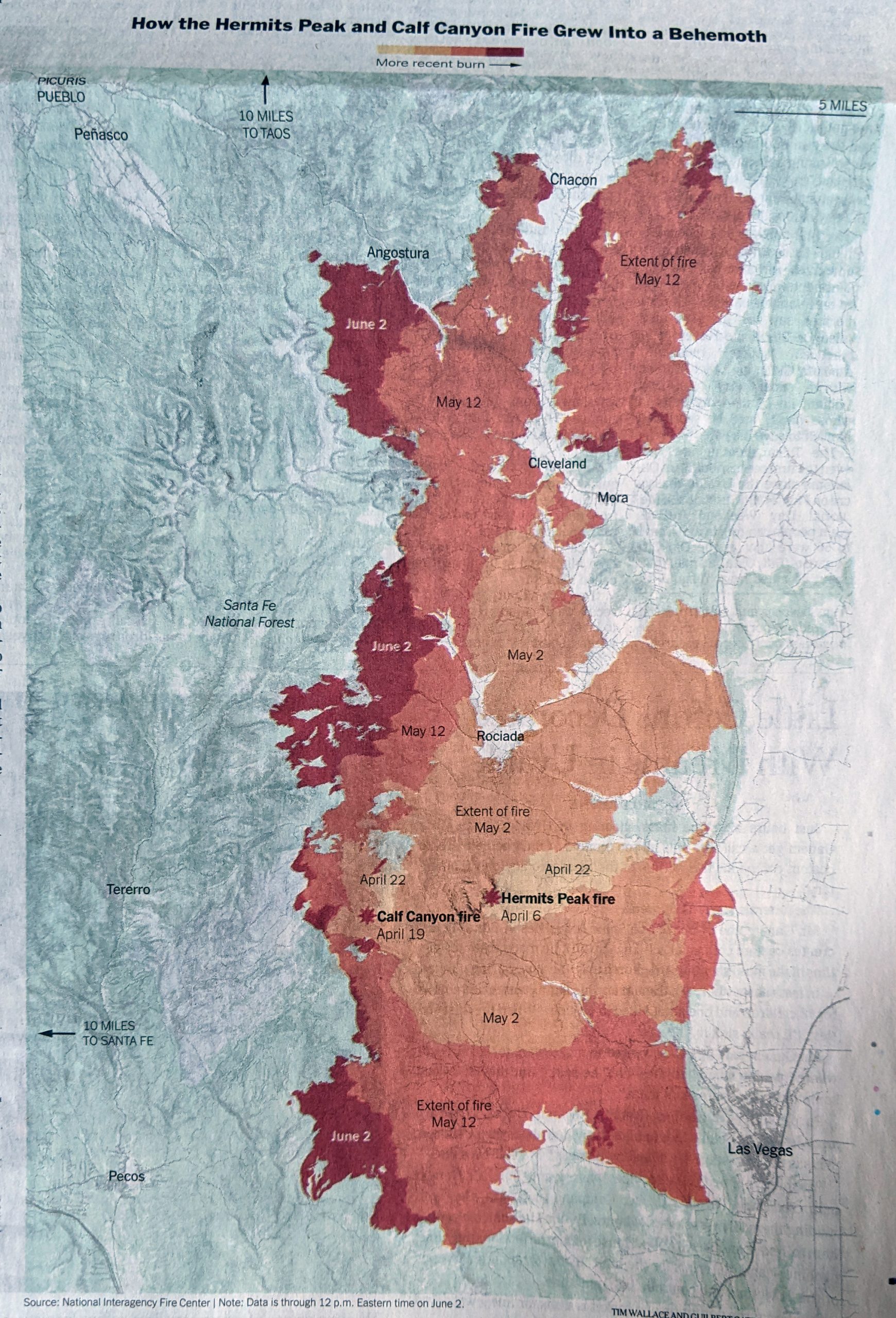
Finally we have the main graphic of the piece, which is a map of the spread of the Calf Canyon and Hermits Peak fire, which was two separate fires until they merged into one. The article does a good job explaining how part of the fire was actually intentionally set as part of a controlled burn. It just became a bit uncontrolled shortly thereafter.
Nope. Definitely not a place to be.
This reminded me of a piece I wrote about last autumn when the volcano erupted on La Palma. In that I looked at an article from the BBC covering the spread of the lava as it headed towards the coast. In that case darker colours indicated the earlier time periods. Here the Times reversed that and used the darker reds to indicate more recent fire activity.
Overall the article does a really nice job showing just what kind of problems New Mexico faces not just now from today’s environmental conditions, but also in the future from the effects of climate change.
Credit for the piece goes to Guilbert Gates, Nadja Popovich, and Tim Wallace.
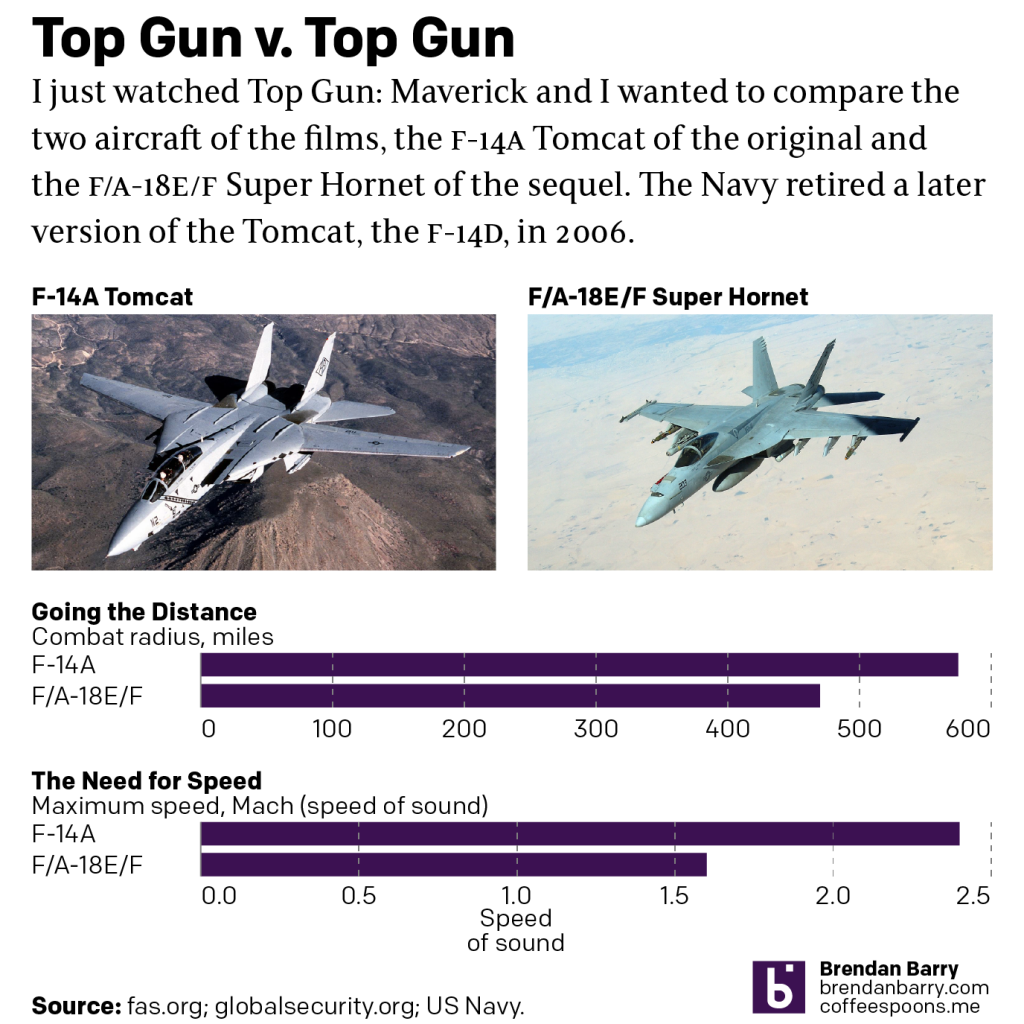
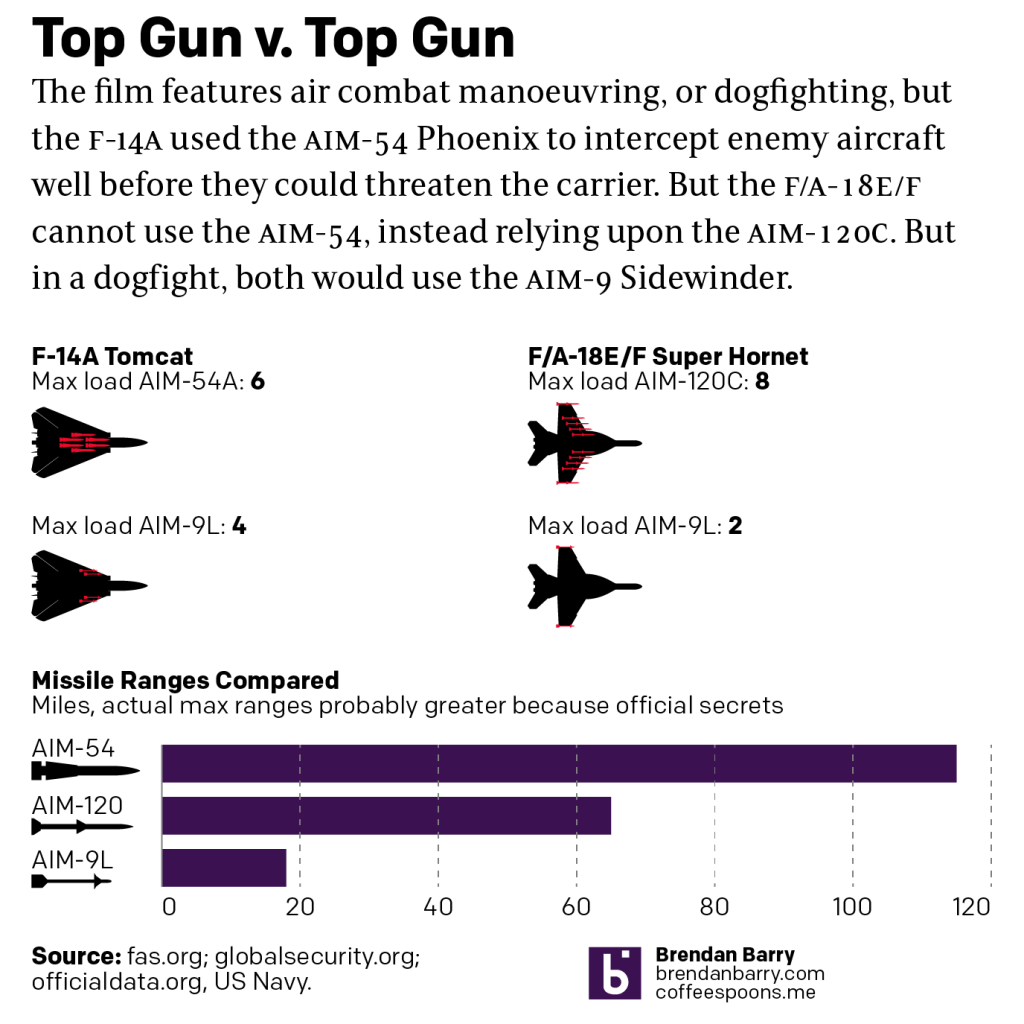
Last night I went to see Top Gun: Maverick, the sequel to the 1986 film Top Gun. Don’t worry, no spoilers here. But for those that don’t know, the first film starred Tom Cruise as a naval aviator, pilot, who flew around in F-14 Tomcats learning to become an expert dogfighter. Top Gun is the name of an actual school that instructs US Navy pilots.
Back in the 1980s, the F-14 was the premiere fighter jet used by the Navy. But the Navy retired the aircraft in 2006 and it’s been replaced by the F/A-18E/F Super Hornet, a larger and more powerful version of the F/A-18 Hornet. So no surprise that the new film features Super Hornets instead of Tomcats.
And so I wanted to compare the two.
The important thing to note is that the Tomcat flies farther and faster than the Hornet. The F-14 was designed to intercept Soviet bombers that were equipped with long-range missiles that could sink US carriers. The Hornet was designed more of an all-purpose aircraft. It can shoot down enemy planes, but it can also bomb targets on the ground. That’s the “/A” in the designation F/A-18. In the role of intercepting enemy aircraft, the F-14 was superior. It could fly well past two-times the speed of sound and it could fly combat missions over 500 miles away from its carrier.
In the interception role, however, the F-14 had another crucial advantage: the AIM-54 Phoenix missile. It was a long-range air-t0-air missile designed for the Tomcat. It does not work with any other US aircraft and so the Hornet uses the newer AIM-120 AMRAAM, a medium-range air-to-air missile.
There are plans to design a long-range version of the AIM-120, but it doesn’t exist yet and so the Hornet ultimately flies slower, less distance, and cannot engage targets at longer ranges.
However, dogfighting isn’t about long-range engagements with missiles. It’s about close-up twisting and turning to evade short-range missiles and gunfire. And even in that, the F-14 could use four AIM-9 Sidewinder missiles whereas the F/A-18 carries only two on its wingtips.
By the 2000s F-14 was an older aircraft and while the moving, sweeping wings look cool, they cause maintenance problems. They were expensive to maintain and troublesome to keep in the air. But they are arguably superior to what the Navy flies today.
Moving forward, the Navy is beginning to introduce the F-35 Lightning II to the carrier fleets. Maybe I’ll need to a comparison between those three.
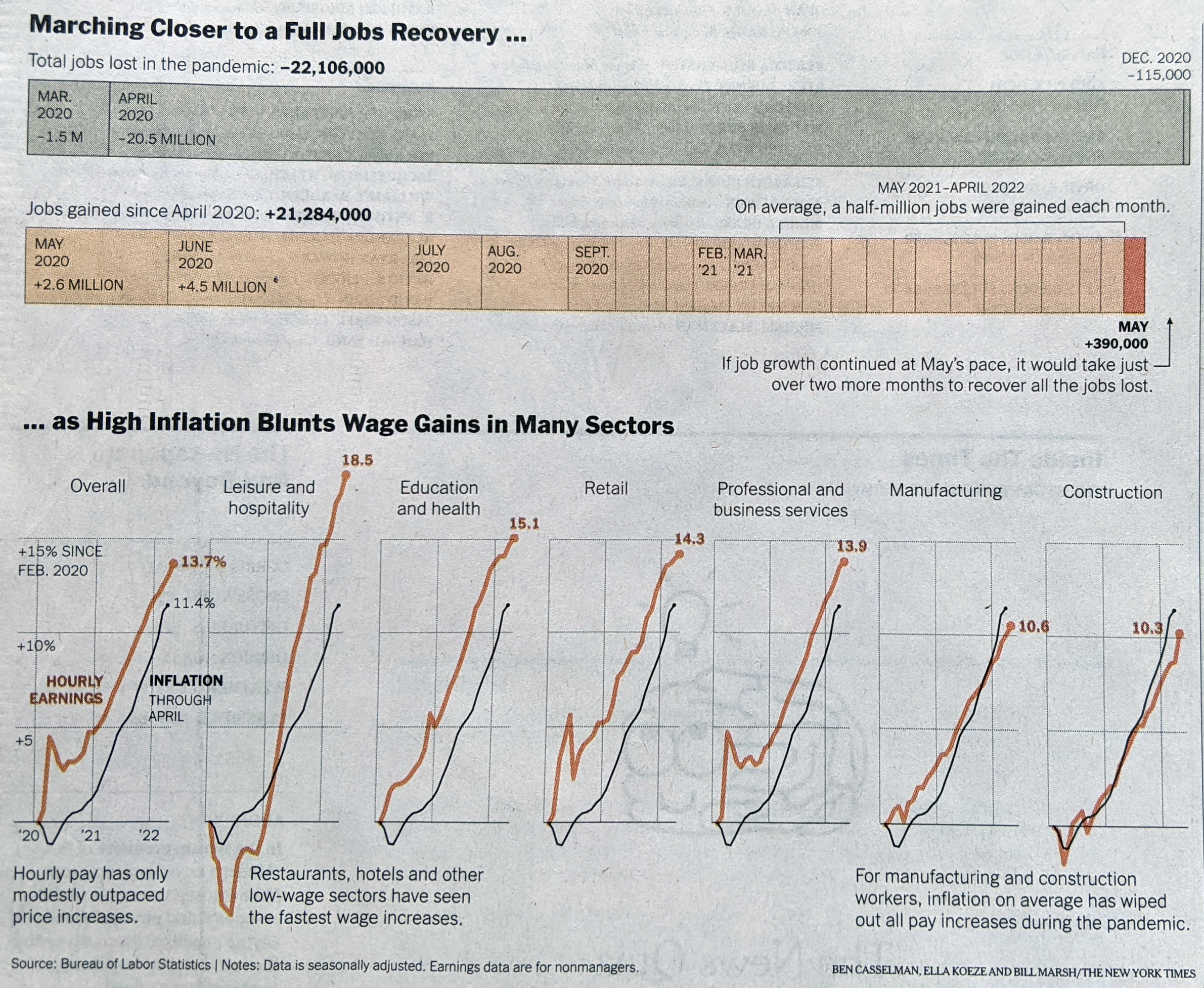
Friday the Bureau of Labour Statistics published the data on the jobs facet of the American economy. Saturday morning I woke up and found the latest New York Times visualisation of said jobs report waiting for me at my door. The graphic sat\s above the fold and visually led the morning paper.
Almost out of the hole.
We have a fairly simple piece here, in a good way. Two sections comprise the graphic. The first uses a stacked bar chart to detail the months wherein the US economy lost jobs during the previous two and a half years. We can take a closer look in this second photo that I took.
But the recovery hasn’t been uniformly good for all.
Here we can see the stacked bars pile up with the most recent bars to the right. Some of the larger bars have labels stating the number of jobs either lost (top) or gained (bottom). I’m not normally a fan of stacked bar charts, because they don’t allow a reader to easily discern like-for-like changes. In this instance, the goal is to show how close all the little bits have come towards making up the three negative bars. Where I take issue is that I would prefer the designers used some sort of scale to indicate even a rough sense of how many jobs the various bars represent.
That issue crops up again to a slightly lesser degree with the bottom set of graphics. These compare the growth of hourly earnings and inflation both from February 2020. During the first few months of the pandemic and its recession, you can see earnings for those most directly impacted by shutdowns drop. But there is no negative scale accompanying the positive scale and that makes it difficult to determine just how far earnings fell for those in, say, leisure and hospitality.
The second part of the graphic works overall, however it’s just some of the finer design details that are missing and take away from the graphic’s overall effectiveness.
This all fits part of a larger trend in data visualisation that I’ve been noticing the last few months. Fewer charts seem to be using axes and scales. It’s not a good thing for the field. Maybe some other day I’ll write some things about it.
For this piece, though, we have an overall solid effort. Some different design decisions could have made the piece clearer and more effective, but it still does the job.
Credit for the piece goes to Ben Casselman, Ella Koeze, and Bill Marsh.